
In this post I want to talk about some recent progress we’ve made in refining our Digital “Standard Model” of knowledge, and to compare and contrast that (and the path there) with the “Standard Model” in Physics.
The Physics “Standard Model”
The Standard Model ultimately emerged from a series of earlier refinements in our understanding of the nature of matter and the universe in general. The idea that matter is made up of discrete units (or atoms) dates back to around 400BC. In the late 1700’s John Dalton proposed that chemical elements were made up of combinations of a finite set of different, inscrutable, and indestructible atoms, these combinations made up all matter in the universe. It was not until 1897 that J.J. Thomson established that atoms themselves were made up of sub-particles when he discovered the electron. In 1913 Niels Bohr proposed his standard model of the atom with a nucleus surrounded by a protective cloud of electrons, and shortly thereafter Ernst Rutherford demonstrated the existence of nuclear isotopes. The concept of quantum mechanics began to emerge in the 1920’s (notably by Werner Heisenberg). Then in 1932 after the discovery of the neutron, the first models of atomic nuclei based on combinations of protons and neutrons emerged, and the entire atomic table (as then known) could first be described with reasonable accuracy.

It was not until 1964 that the quark model was simultaneously proposed by Murray Gell-Mann and George Zweig. This model proposed that all hadrons (nuclear particles) were themselves made up of different combinations of quarks), that the ‘forces’ acting on matter itself were in fact ‘carried’ by bosons (force carriers) that themselves were made up of quarks (and anti-quarks). Furthermore, the quarks that make up these other particles cannot be isolated or examined due to the ’strong’ force that binds them. It appears that quarks are the end of the line, the smallest building units possible. The number of known quarks was extended from four to six (and the corresponding anti-quarks) in 1975, so completing the Standard Model. Today the Standard Model is the theory describing three of the four known fundamental forces (the electromagnetic, weak, and strong interactions, and not including the gravitational force) in the universe, as well as classifying all known elementary particles. While the physics “Standard Model” may not be the long sought after “Theory of Everything” (TOE), it has been spectacularly successful in its predictions, and is perhaps as close as we have managed to get so far to a TOE.

Digital Sciences vs. Analog Sciences
If we ignore the formal sciences (maths, logic, etc.), there are essentially three fundamental natural sciences, Physics, Chemistry, and Biology each of which has myriad derivative and often overlapping specialities. From the summary above, we can see that the science of Chemistry (and materials) is focussed on the interactions of the electron clouds of various elements, that is although the nature of these clouds is dictated by nuclear content, the nucleus itself is inaccessible. The science of Biology pertains to the vastly complex interactions and combinations primarily involving the element Carbon and the emergent complexity that ultimately creates. Thus with the exception of Physics itself (which spans the imperceptibly small to the indescribably large), our understanding of the world and the variety of specialized ontologies we use to describe it, stop at the electron cloud level and can largely ignore the Standard Model, despite being fundamentally a consequence of it.
Over 30 years ago now, work on Mitopia® began with a single fundamental requirement: “To build a system able to describe everything happening in the world, unify it for analysis, and extract and present actionable understanding and prediction therefrom”.
Computer Science (CS) is currently classified as an “Applied Science” along with Engineering, Medicine, etc. This is a correct classification given the non-rigorous way CS is invariably practiced today, however, I would contend that it is a misclassification and misses the unique feature of digital knowledge representations and systems, that is their potential to create alternate digital universes of complexities that for limited domains (at least for the foreseeable future) approach reality. The ultimate consequence of this potential is the “simulation hypothesis”, the idea that we are in fact all living in a universe that is actually running inside a computer simulation. This seemingly fringe theory has testable consequences, and is in fact being seriously studied by a number of scientists around the world. Emergent Artificial Intelligence is another possibility within such a digital universe, and this too is a rapidly evolving field of study and development. Were CS to define its primary purpose as being “to create digital worlds” (often “Digital Twins“) rather than “to expeditiously solve real world problems (by ad hoc means)”, it would, of necessity, be approached from the outset not as an applied science, but as a fundamental one.
The point is that if we set out to create a “digital universe” that mirrors reality with some scope and level of detail (i.e., Mitopia’s original goal), then the first questions we must ask are:
- What is the Theory of Everything (TOE) that allows us to create a ‘useful’ digital ‘world’?
- What are the architectural components ( e.g., here, here, and here) we need to underly a digital ‘world’ model based on that TOE?
To tackle the two problems above requires an uncommon degree of rigor, since we are in effect moving CS out of the applied sciences column, and back up to the top of a parallel ‘digital’ sciences ‘tree’ where it applies to alternate ‘digital universes’, not our own (even if modeled on it). In these digital universes, it seems that the fundamental sciences should break down quite similarly to the real world viz:
Digital Physics – This is the science of the underlying architectural components needed to create such a system including the key structures required to facilitate the representation of all knowledge, the underlying infrastructure to store, distribute, query, and display such knowledge, the algorithms and optimizations to allow system operation in real time, to schedule code execution triggered by data flow, etc. I will address this subject in more detail below.
Digital Chemistry – This is the science of what are all the ‘macro’ things that can make up the digital world and the ways they interrelate, so that a digital TOE can reason over the data in order to extract and present results that have ‘meaning’ in and are adaptive to the ever-changing real world domain being mirrored. This is primarily the job of Mitopia’s Carmot™ ontology and you can find related posts throughout this site.
Digital Biology – In a digital world, we can consider emergent or discovered ‘knowledge’ or order-from-apparent-chaos to be the equivalent of the emergent life we see in the real world. For analog life, emergence evolves over time through many levels of sophistication ranging from the virus to intelligent self aware entities such as human beings, all of which necessarily coexist in order to be viable. For digital knowledge, there is a similarly layered evolutionary path to emergent ‘wisdom’, and as for the real world, that ‘wisdom’ necessarily coexists with, and leverages, simpler forms (within the same ‘world’), even while both continue to evolve. It is the ability to host an emergent digital biome that distinguishes such a ‘digital word’ system from standard software systems of today since the ‘biome’ renders the system ‘useful’ in a way that is far more fundamental, emergent, and adaptive than standard software tools. Posts and videos relevant to this subject (and its coexistent ‘levels’) can be found throughout this site.
Mitopia’s ‘Kernel’ structures
Designing Mitopia in the early 90’s it was clear from the outset that the ‘digital world’ must be described by a single universal and ‘contiguous’ ontology, and that ontology must be based on a TOE with a proven history of successful generalization and prediction. Many if not most of the posts on this site relate to these ‘digital chemistry’ aspects of Mitopia. You will also find posts on ‘digital physics’ aspects as listed above, but in this post we will focus on the very lowest layer, the invisible “nucleus” and the ‘digital quarks’ that make it up. In this sense these digital ‘quarks’ are the simple and irreducible essential structures that underly and enable everything else. From the outset (around 1991-2), it was clear that to create a runtime discoverable types system and aggregation metaphors would be a lengthy task, and that that aggregation, in order to be scaleable, must be based on a “flat” memory model. This flat memory model it seemed must include a significant set of ‘nuclear’ (i.e., inscrutable to non-core code) components/structures that allowed Mitopia itself to create and schedule a data-flow based substrate above which all data discovery would be through the ontology. Below this ontology layer, for the sake of efficiency and practicality, internal Mitopia code would punch through and manipulate these ‘nuclear’ structures directly as needed to create the upper substrate. After considerable contemplation, an initial ‘bestiary’ of required nuclear structures needed to support all essential algorithms was determined. The initial number was somewhere between 25 to 50 different types. This then led to the fundamental 6-bit “RECORD_TYPE” field within the first ‘flags’ word of all Mitopia flat-memory structures. This omnipresent field allows low level Mitopia code to determine at any point exactly what kind of a record it is dealing with (within any given flat memory aggregate handle) and act accordingly. Over time, some of these structures proved superfluous, and others were subsumed into ontology-based forms, so it is hard to reconstruct the complete original flat-memory structure list, but the following is a list of those still in use within the last year or so:
Structures associated with data-flow-based code execution:
- kViewRecord – This is the structure that starts a ‘view’ which is a memory allocation handle associated with code and data flow scheduling, it logically contains/references all other structures in the ‘view’.
- kWidgetRecord – This is the structure associated with maintaining all state of a currently executing data-flow-based widget (atomic = with code or compound = just flow).
- kFlowRecord – A typed flow connecting two or more pins used to mediate data flow.
- kPinRecord – A ‘typed’ pin connecting a flow to a widget or object.
- kObjectRecord – An object involved in data flow (e.g., a constant or variable).
- kDDescRecord – Maintains GUI state for all widgets having a GUI.
- kWInfoRecord – Contains fields describing a widget, its author, help, etc.
- kRefRecord – A record mediating a “hyper-flow” (data flow between views, local or remote).
- kDebugRecord – A record used to implement smart breakpoints on data-flow activities.
Structures associated with defining types and aggregations:
- kTextDBRecord – The container structure for flat-memory aggregations that are not ‘views’.
- kTypeRecord – A record describing a type in the Carmot™ ontology.
- kFieldRecord – Describes a field within a type in the ontology.
- kComplexRecord – Used to organize records into collections of various types.
- kSimplexRecord – A record of an ontological type, tied to a ‘valued’ kComplexRecord, that contains all field values.
- kOrphanRecord – A transitory re-cycling record created when other structures are destroyed.
Structures associated with maintaining assorted internal data-sets:
- kStringRecord – Used to create searchable/sortable delimited text databases. Also used to hold text referenced from kSimplexRecords.
- kErrorRecord – Used in error logging
- kPrefsRecord – Tracks user and system preferences and configurations.
- kUnitRecord – Used to create database of units and unit conversions.
- kResourceRecord – Describes resources (e.g., images, icons, sounds, etc.)
- kGroupRecord – Maintains group membership as part of security
- kCryptoRecord – Maintains cryptography keys as part of security
- kNodeRecord – Used to maintain a map of network nodes and resources
- kMemoryRecord – A record used to track widget memory allocations and ownership. Memory records are actually held in a separate kTextDB aggregate from the view that references them even though associated with executing code.
- kNullRecord – An empty flat-memory structure. Marks the end of a View or TextDB.
There are a number of asymmetries and issues in the list above that have bothered me since the time of the original ‘nuclear’ vs. ‘ontology’ split all those decades ago, however the amount of complex and highly optimized Mitopia code predicated on these ‘nuclear’ structures was sufficient to discourage any attempt at resolving them, particularly within executing ‘views’. These are as follows:
- There are two distinct types of aggregate ‘container’, the ‘view’ (and its constituent ‘hadron’ structures) which are used to manipulate running code and data flow, and the ‘textDB’ which is used to contain everything else both ontological or internal (non-view) data sets. Why?
- Mitopia provides a visual data-flow programming language to allow widgets and data flow to be created and wired up by non-technical persons. Because this is based on raw nuclear structures it represents a huge chunk of code, most of which is tied to GUI manipulation, and which is consequently difficult to maintain. Moreover the structures associated with GUIs within any given widget (i.e., windows and the controls within them) were originally fully custom and hidden within each ‘renderer’ (itself highly undesirable), and layout of the widget GUIs within views was a separate metaphor (known as WEM/VEM) built on ‘nuclear’ structures. Starting in 2009 all GUI was switched over to the Universal Renderer abstraction (which uses the ontology to describe and interact with GUI, so subjugating renderers to implementation only). As a result the motivation to do the same for the content of ‘views’ and so unify all GUI under the ontology has become stronger in recent years.
- It has always been clear that the “assorted data-set” structures could potentially be re-implemented as typed collections described by the ontology, thereby eliminating all the extensive custom code required to provide GUIs to manage these data-sets that could then simply be handled by Auto-generated GUIs. However, without subsuming views themselves under the ontology, this hardly seemed a worthwhile exercise.
- These nuclear structures cannot be shared at run-time across executing instances of Mitopia since, although ‘flat’ (and thus not requiring serialize/deserialize steps) they don’t get the benefit of all the type management and endian handling infrastructure built into the ontology abstractions and so can’t be reliably exchanged in a heterogenous network. For the same reason these structures cannot be ‘persisted’ in native form or sent to Mitopia servers. This necessitated local file-based storage strategies in most cases.
- The list of required building block structures is simply too large (~25) for it to be a plausible fundamental theory candidate for a digital “Standard Model”. This seems to confirm that we haven’t yet identified the fundamental minimal set of digital ‘quarks’.
So, other than the subsuming all GUI structures into the Universal Renderer abstraction, the core structure list above has remained largely constant from the outset. Mitopia was until recently a system designed to mimic the real world, but lacking an all-encompassing digital “Standard Model” of knowledge incorporating its own inscrutable underlying digital ‘nucleus’ to parallel the theory we have that describes the real world.
A Digital “Standard Model”?
All that was changed by the COVID-19 crisis By the end of April 2020, we had essentially completed an extensive 2-year parallel port to full Posix compliance and a new cross platform plug-in ‘renderer’. The on-going pandemic’s effect on business activities created a window within which it was possible to tackle the issues listed above, and hope return to stability under a new unified approach, without disrupting on-going operations. So, starting in early May, to take advantage of this unique opportunity, we set out with the goal to transition views themselves over to collections. The process took almost four months, and involved literally 10’s of thousands of changes to huge swaths of core Mitopia code. The basic approach was to abstract out all access to non-ontological ‘nuclear’ structures, hiding them behind abstracting APIs that could simultaneously run under both the old flat-memory structures and the new ontology-based ones within a single Mitopia instance depending on what kind of ‘container’ they were passed (old style view or collection). This dual approach was critical since we were dealing with the fundamental units of execution, and without it Mitopia would have simply stopped working completely, thereby making it impossible to test anything during the transition process. As it was, with the duality in place, each stage of the transition process was tested incrementally with the rest of the system still using the old approach (now also hidden under the new duality API) thus allowing the system as a whole to operate normally. Once the transition of executing views was complete and tested, switching over all the other data-sets to ontology based equivalents, and their GUIs to auto-generated equivalents, then took an additional few weeks and eliminated lots of old-style custom GUI code.
As an example, the Carmot™ code below defines the ontological replacement for the kErrorRecord structure, and the side-by-side screen shots below show the ErrorBrowser GUI (dark-mode theme) before and after this transition to auto-generation/handling:

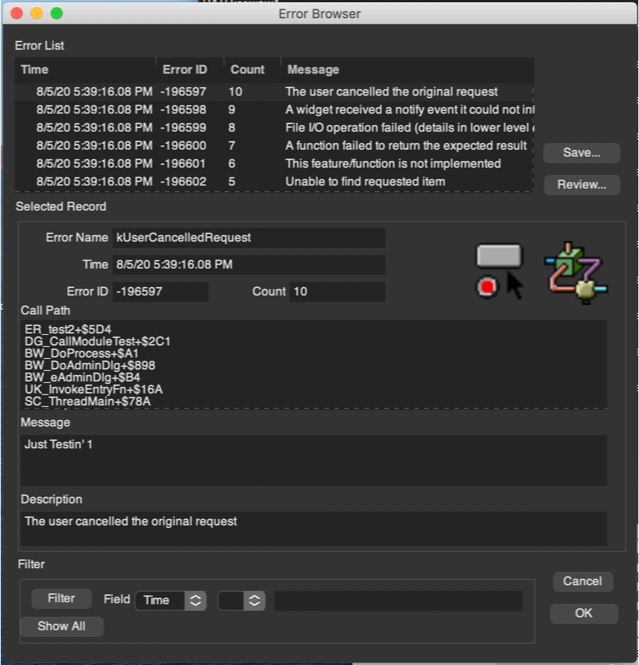
Old-style Error Browser 
Ontology-based Error Browser
You can read other posts (see here) to understand how the GUI shown on the right is auto-generated and entirely handled from the ontological definition above. The end result is identical functionality to the old custom window, but 40% of the code associated with the Error package and managing the browser GUI (and the ‘anchor’ that non-adaptive code represented) evaporated entirely and is now handled by the ontology abstraction. The only part that needs explanation is the “Description” ‘field’ which is actually a “$description” tag (registered with the ontology) associated with the error element, and is computed on the fly as the element is displayed. To ease the complexity of a ‘duality’ transition, the old-style “RECORD_TYPE” field remains packed into the the first 6 bits of the “flags” word that starts each and every one of the transitioned ‘nuclear’ types. You can see it displayed along with other parts of the “flags” bit-field on the RHS image. For some of the transitioned types the ability to switch back and forth between old and new style remains hidden below the abstracting APIs, for others (like errors), it does not. This continued duality allows consistency cross checks between old and new just in case in the future we suspect a bug in the new implementation. Eventually all such old-style code will be scrapped, but for now we keep it around (even though not normally used).
A similar GUI switchover applies to all other custom editors and browsers for the old ‘nuclear’ Mitopia types. However, the conversion of the entire data-flow editing environment (currently known as WEM/VEM) and its unification with a new GUI layout editor is a larger task and still a work in progress.
A new ontology definition file D.DEF now contains all definitions associated with what were inscrutable kernel structures in a view, all non-view data-set types, all GUI specific types (controls, windows, etc.) and everything else that underlies basic Mitopia operation. The list of types that is now implemented as raw-flat-memory building blocks is now as follows:
Structures associated with defining types and aggregations:
- kTextDBRecord – The container structure for ALL flat-memory aggregations. There is no longer a distinct ‘view’ container, it is simply one of many specialized collection types.
- kTypeRecord – A record describing a type in the Carmot™ ontology.
- kFieldRecord – Describes a field within a type in the ontology.
- kComplexRecord – Used to organize records into collections of various types.
- kSimplexRecord – A record of an ontological type, tied to a ‘valued’ kComplexRecord, that contains all field values.
- kOrphanRecord – A transitory re-cycling record created when other structures are destroyed.
- kStringRecord – As used by the ontology (and ET_StringLists) only.
- kNullRecord – An empty flat-memory structure. Marks the end of a TextDB.
This is the complete list of fundamental structures underlying everything Mitopia does, there are no longer any others! The types that were previously distinct within a view are now just part of the ontology, that is the system ontology is now also introspecting itself down to the “nuclear” level, as required for a candidate digital TOE.
What this means is that:
- All GUIs including those for WEM/VEM, GUI layout, internal data-sets, etc. can now be auto-generated from the underlying typed collections.
- All aggregates can be shared just like other Mitopia data and no longer require file-based storage approaches.
- Most custom GUI code within Mitopia is eliminated completely. This process is on-going (see earlier note about WEM/VEM/GUI-layout).
- Every aspect of the system is adaptively driven by the ontology, there are no hidden code-based ‘anchors’ to detract from system adaptability.
- Performance in these areas has not been adversely impacted, and in many cases is improved.
One additional and unexpected benefit of the transition was that the use of typed collections to underly scheduling and data flow impacted some of the tightest and most time-critical activities within Mitopia. Initially after making the transition to collection-based views, there was a slowdown in scheduling rate by a factor of maybe two orders of magnitude. This was at first alarming and discouraging. To investigate where the slowdown occurred, necessitated developing additional ontology-based performance analysis tools. However, these tools ultimately led to discovery of a new and radical optimization technique applicable to all ontology-based aggregates including executing views. All transitioned code now uses this optimization strategy and any timing impact on core Mitopia operation is now immeasurable (i.e., identical to the old dedicated flat-memory equivalent). Other areas of Mitopia operation have actually become faster as a side benefit.
So, where does this leave our digital “Standard Model”? First let me point out that the “container” itself (kTextDBRecord) doesn’t really count as a building block record, as the name suggests it is merely a wrapper for aggregates of others. Similarly the kNullRecord type is analogous to an End-of-File marker for a file; it is merely an EOF marker for a kTextDBRecord container. Excluding these two from our list leaves us with just 6 different structures required to implement EVERYTHING in our digital world. This is a pretty radical concept when you think about it, and a very different approach to all other existing software systems.
If we look at the functionality of our six digital ‘quarks’, they fall now into two groups namely those associated with defining things in the Carmot™ ontology (i.e., kTypeRecord and kFieldRecord), and the rest which are associated with creating instances and interconnected aggregations of those types that can be persisted, shared, queried, visualized, and otherwise manipulated through the defined ontology.
Moreover, the number six we have seen before, it is the total number of different types of quarks required in the Physics “Standard Model” to describe the real world and the forces within it (except gravity). This immediately makes one think that these six structures may well, in some fundamental way, be exactly the ‘quarks’ needed to create and describe a digital world and everything within it (a digital “Standard Model”)…(except containment).
Coincidence? Probably, but still, one can’t help wondering, what if the Physics Standard Model really were some kind of simulation artifact…
