
 |
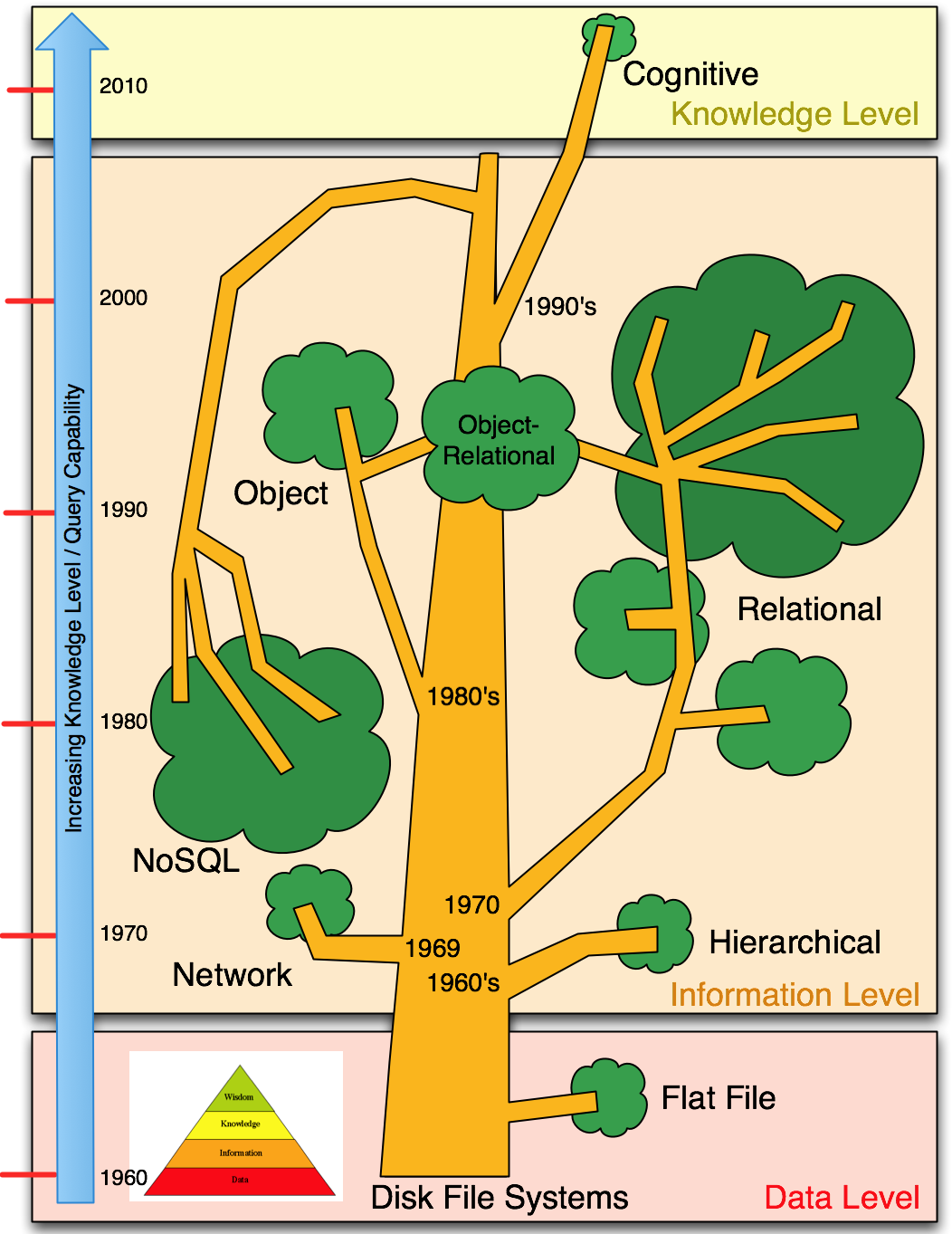
| Database model family tree by ‘knowledge level/functionality’ |
In previous posts we have talked at length about the ‘knowledge pyramid‘ and what it means in terms of how information is represented and the types of operations that are possible given software architected to utilize that level of organization. Unfortunately, the implicit assumption that there is an external ‘database‘, accessed by distinct means and using its own ‘database model‘, has crept into all existing software systems, no matter what they may claim in terms of functionality (see discussion here). This assumption pervades all software systems that manipulate data that must last beyond the life of any given program run.
What this means in practical terms is that any attempt to envision software systems operating at the knowledge-level (i.e., that explore connections, not just content) is by definition hampered in this effort because it must use an existing database metaphor that cannot natively support knowledge-level operations. The result is that even systems that claim ‘knowledge-level’ features, cannot in fact deliver them in any non-trivial data domain. Obviously our programming languages are capable of representing structures and relationships of arbitrary complexity, and have been since the 1970’s; the problem comes when the data set has permanence or swells beyond the CPU address space, and so must involve a database.
The truth is that current database technology is a millstone around the neck of anyone attempting to climb up the knowledge pyramid; database models have been holding us back for decades and nothing is being done about it; indeed the ‘new frontier’ in databases is actually a giant leap backwards. For me ‘database’ has been a dirty word since the early 1990’s.
The diagram above shows the database evolutionary tree to date. The diagram is divided into three sections based on the level of operations supported by the database metaphor involved. At the bottom is the data-level as represented by the flat file model. Records are stored one per line in a text file. At this level the data is stored, but cannot be robustly searched and cannot represent connections or nesting. The only really significant remnant of the ‘flat file’ database model surviving today is the Excel spreadsheet.
 In the mid 1960’s to early 1970’s there was a revolution in database thinking. These advances brought databases up to the information-level (data content can be searched and manipulated with relative ease, sub-structures can be represented, as can simple connections). Much of these advances can be attributed to E.F. Codd. The hierarchical data model was the first true database model to emerge from IBM in the 1960’s; data is organized into a tree-like structure using parent/child relationships such that each parent can have many children, but each child can have only one parent. The model represents many simple real-world situations but is not powerful enough for generalized use. The model survives today mostly as IBM’s IMS database, and as the implementation of the Windows Registry (for storing configurations and settings on Windows operating systems). The hierarchical model largely died out once Codd introduced the Adjacency List showing how hierarchies could be represented within a relational database.
In the mid 1960’s to early 1970’s there was a revolution in database thinking. These advances brought databases up to the information-level (data content can be searched and manipulated with relative ease, sub-structures can be represented, as can simple connections). Much of these advances can be attributed to E.F. Codd. The hierarchical data model was the first true database model to emerge from IBM in the 1960’s; data is organized into a tree-like structure using parent/child relationships such that each parent can have many children, but each child can have only one parent. The model represents many simple real-world situations but is not powerful enough for generalized use. The model survives today mostly as IBM’s IMS database, and as the implementation of the Windows Registry (for storing configurations and settings on Windows operating systems). The hierarchical model largely died out once Codd introduced the Adjacency List showing how hierarchies could be represented within a relational database.
 The network data model was invented by Charles Bachman in 1969. While the hierarchical database model structures data as a tree of records, with each record having one parent record and many children, the network model allows each record to have multiple parent and child records, forming a generalized graph structure. This model is somewhat more general and powerful than the hierarchical model, but like the hierarchical model before it, the network model was largely abandoned in favor of the relational model which offered a higher level more declarative interface. Today the network model is still in use for certain specialized database applications such as IDMS but is otherwise rare.
The network data model was invented by Charles Bachman in 1969. While the hierarchical database model structures data as a tree of records, with each record having one parent record and many children, the network model allows each record to have multiple parent and child records, forming a generalized graph structure. This model is somewhat more general and powerful than the hierarchical model, but like the hierarchical model before it, the network model was largely abandoned in favor of the relational model which offered a higher level more declarative interface. Today the network model is still in use for certain specialized database applications such as IDMS but is otherwise rare.
 Then in 1970 Codd introduced the relational data model, the first database model to be described in formal mathematical terms. The model organizes data based on two-dimensional arrays known as relations or tables. These tables consist of a heading and a set of zero or more tuples in arbitrary order. The heading is an unordered set of zero or more attributes, or columns of the table. The tuples are a set of unique attributes mapped to values, or the rows of data in the table. Data can be associated across multiple tables with a key which is a single, or set of multiple, attribute(s) that is common to both tables. The most common language associated with the relational model is the Structured Query Language (SQL).
Then in 1970 Codd introduced the relational data model, the first database model to be described in formal mathematical terms. The model organizes data based on two-dimensional arrays known as relations or tables. These tables consist of a heading and a set of zero or more tuples in arbitrary order. The heading is an unordered set of zero or more attributes, or columns of the table. The tuples are a set of unique attributes mapped to values, or the rows of data in the table. Data can be associated across multiple tables with a key which is a single, or set of multiple, attribute(s) that is common to both tables. The most common language associated with the relational model is the Structured Query Language (SQL).
While very effective at searching record content, relational databases, are complex to set up and maintain, and contrary to what the name ‘relational’ suggests, are very inflexible in terms of representing arbitrary and evolving relationships between records. It is this lack of power in representing and querying complex connections that prevents relational databases from forming an effective substrate for knowledge-level systems. This problem persists even today and little or nothing is being done about it, with the result that all our information-level systems remain stuck in a rich content, but not rich connections quagmire.
The relational model effectively ended the database wars; it became so dominant as to reduce all other models to virtual irrelevance. Even today, more than 40 years later, the relational model has steadfastly resisted all attempts to create and spread more modern concepts into the world of persistent data. The relational monopoly has brought progress to a virtual halt.
 In the 1980’s, the object database model emerged and for a brief time posed a real threat to the relational hegemony. The model started out as a way to mirror object oriented programming and to store and retrieve objects so as to reduce the divergence between the programming model and that of the database that underlies it (a major issue with the relational model). While offering potential advantages over the relational model, primarily in ease of mapping to/from the application code, the object model has lower efficiency and simpler relationship support than does the relational model (making it actually less suited to knowledge-level systems). Nonetheless, in response to the perceived threat of the object model, most large relational database vendors in the 1990’s added object model features on top of existing relational databases, thus creating the hybrid object-relational database. This has the benefits of the object model’s ease of mapping to application code, but is essentially just a thin veneer over the relational model, and thus does not represent any significant change. Today the pure object database model has largely died out leaving only object-relational descendants. SQL:1999 incorporated many of the ideas of object databases directly into SQL, the relational query language. Threat averted.
In the 1980’s, the object database model emerged and for a brief time posed a real threat to the relational hegemony. The model started out as a way to mirror object oriented programming and to store and retrieve objects so as to reduce the divergence between the programming model and that of the database that underlies it (a major issue with the relational model). While offering potential advantages over the relational model, primarily in ease of mapping to/from the application code, the object model has lower efficiency and simpler relationship support than does the relational model (making it actually less suited to knowledge-level systems). Nonetheless, in response to the perceived threat of the object model, most large relational database vendors in the 1990’s added object model features on top of existing relational databases, thus creating the hybrid object-relational database. This has the benefits of the object model’s ease of mapping to application code, but is essentially just a thin veneer over the relational model, and thus does not represent any significant change. Today the pure object database model has largely died out leaving only object-relational descendants. SQL:1999 incorporated many of the ideas of object databases directly into SQL, the relational query language. Threat averted.
In the mid to late 2000’s, the NoSQL movement emerged. This was essentially a by-product of the extremely high cost of relational database licenses required (for massive data sets) by emerging internet startup companies. The idea was basically to use anything but the relational model because the application involved didn’t need all that the relational model provided. As a result these companies turned to the largely free technologies introduced by Google, Amazon, and FaceBook, and scaled by such techniques as Hadoop and MapReduce. NoSQL databases are not built primarily on tables, and generally do not use structured query language for data manipulation. NoSQL database systems are often highly optimized for retrieve and append operations and often offer little functionality beyond record storage (e.g. key–value stores). ACID properties are generally relaxed in order to support easy distribution. The reduced run-time flexibility compared to full SQL systems is compensated by marked gains in scalability and performance for certain data models.
In short, NoSQL database management systems are useful when working with a huge quantity of data and the data’s nature does not require a relational model for the data structure. The data could be structured, but this is of minimal importance, and what really matters is the ability to store and retrieve great quantities of data, and not the relationships between the elements.
There are many who argue that NoSQL technologies should not even be considered databases, since the functionality is so low and is predicated on a return to the data-level (i.e., a document model). Programming and configuring these systems is a nightmare, and only very simple operations (on a large scale of course) are possible. Boiled right down, NoSQL is a huge retrograde step driven by financial considerations, and predicated on the need to truly distribute search (which is not possible under the relational model). In a very real sense, NoSQL represents a failure to face up to the urgent need to advance database frontiers, instead NoSQL chooses to retreat and accept the horrific performance and functionality losses. Performance is then recovered by massively scaling the number of machines used (and paying the resultant electricity bills); functionality is irretrievably gone. This is why I have shown the NoSQL branch in the database tree diagram above as bent over and reaching almost to the ground.
But there are some very real truths that underly the ‘Big Data‘ problem that first gave rise to the NoSQL movement. Data sets regularly exceed the petabyte level and thus cannot (cost effectively) be handled in relational databases. Big data is difficult to work with using relational databases and desktop statistics and visualization packages, requiring instead “massively parallel software running on tens, hundreds, or even thousands of servers”. What is considered “big data” varies depending on the capabilities of the organization managing the set. “For some organizations, facing hundreds of gigabytes of data for the first time may trigger a need to reconsider data management options. For others, it may take tens or hundreds of terabytes before data size becomes a significant consideration. Big data requires exceptional technologies to efficiently process large quantities of data within tolerable elapsed times. The NoSQL movement was triggered by the trend towards big data, and many techniques used by NoSQL have merit (e.g., the Hadoop distributed file system), however, we should not make the mistake of equating big data and NoSQL as the same thing, they are not. Big data is a real problem for which a few initial steps and techniques are emerging. NoSQL is a reaction to the relational database model, and is a retrograde step that likely has little real future. We need more powerful distributed database models, not a return to the dark ages.
For big data to be practical and provide the promise of enhanced functionality and insight, a number of things appear to be true:
- The database model must be truly distributed, that is it cannot require shared storage (like SAN or NAS). Such reliance of necessity slows the cluster down and cannot be distributed over a wide geographical area, instead it tends to be ‘within rack’. For speed, each node must have access to and utilize its own local storage independent of all others. This essentially rules out the relational database model. The nodes of server cluster might be geographically globally distributed.
- The database model must operate at the knowledge-level (i.e., using ontologies), not the information-level (i.e., taxonomies), and certainly not a data-level document model. The model must natively and efficiently support complex chains of connections as well as simple record content. The model must be capable of everything the relational model can do and a whole lot more. We need a vastly more powerful query engine than the relational model provides.
- The database model cannot require fixed sized ‘cells’ to hold data. Almost nothing but numeric data nowadays fits into a fixed sized field (as required by the relational model). Today’s data includes multimedia items like images and video. Even text fields can be arbitrarily large and must allow the pervasive use of any known language, not just English.
- The database model must solve the ‘join problem‘, in particular since the model must be truly distributed, the behavior of passing around possibly massive intermediate hit lists between nodes or federated components must not be allowed to occur.
- Like the object model, there should be minimal difference between the in-memory programming model and that required to manipulate and access data in the ‘database’. Ideally, the programmer should be completely unaware of the difference between temporary and persistent data (see here). The concept of a separate ‘database’ needs to go away.
- The model must handle the need to ingest massive streams of new data in parallel into different nodes of the server cluster while ensuring that no duplication of existing records occurs, and that any new data relating to an existing record, regardless of where in the cluster that record is stored, is merged into the existing record. Transactional requirements (a la ACID) may be relaxed. All this without slowing such an ingesting cluster to a relative crawl as all nodes ‘cross-check’ with others.
- The model must be extensible, that is it must allow the servers to be implemented as a federation of components so that additional specialized components can be created and added to handle newly emergent multimedia or specialized data types. For example, it should be easily possible to plug a fingerprint recognizer say right into the server query logic on every node in the cluster so that a federated query involving this new component can occur in-line and locally with other queries executing on the node. Support for the special needs of multimedia (e.g., isochronous delivery of video) must be integrated into the model. Integrated and automatic support for multimedia data migration to/from near-line storage is also desirable.
- The server cluster topology must be reconfigurable easily as new resources are added. Load balancing should be automatic, and all distributed data should automatically migrate to any new structure whenever the underlying record definition is changed. To fail to address these issues would create an administrative nightmare when servers are updated as a result of the inevitability of change. Such updates should be possible without bringing down the servers. Furthermore, a means to provide a consistent backup of state across the entire server cluster is required.
- A far more powerful and extensible (due to the federated requirement) query language than SQL is required, though at its heart the language must be simple and representable in a fully textual form. The expression of queries involving complex indirect chains of connections must be supported natively.
That is a pretty demanding list of required features for our new database model to truly address the ‘big data’ challenge. The truth is that there is only one database model in existence that can handle the list above, and that is Mitopia’s cognitive data model which began in the mid 1990’s. Without such a database model, truly massive systems addressing knowledge-level problems will not be possible. We will be stuck with simple keyword searches combined with exporting small data sets into external information-level visualization suites. This is today’s reality.
It has been over 40 years since the last radical advance in database models. It is time we moved on.
If you want to learn more on this subject, watch the “MitoipaNoSQL.m4v” video on the “Videos, Demos, & Papers” page.
In upcoming posts we will examine some of the aspects of Mitopia’s cognitive data model that make the list of bullet points above possible whilst simultaneously providing improved performance and scaleability over any existing approach.