Before future posts can discuss true ontologies and how they fit into the range of computing systems, and most particularly how ontology-based systems differ fundamentally from todays taxonomy-level systems, we need to examine the information systems “knowledge pyramid”. This post and the sequence that follows will examine this subject in more detail.
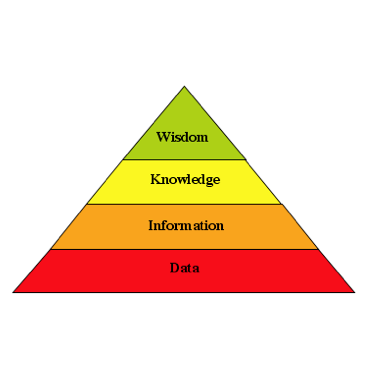
Systems that operate on the Data Level (DL) may be characterized as those that contain or acquire large amounts of measurements or data points concerning the target domain but have not yet organized this data into a human-useable form. Data-level systems are most frequently found during the ingestion or data-acquisition phase.
Information-Level (IL) systems can be characterized as having taken the raw data and placed it into tables or structures that can then be searched, accessed and displayed by the system users. The overwhelming majority of information systems out there today operate in this realm.
A system that operates at the Knowledge Level (KL) has organized the information into richly interrelated forms that are tied directly to a mental model or ontology that expresses the kinds of things that are being discussed in the information, and the kinds of interactions that are occurring between them. An ontology is a formalization of the “mental model” for the types of items that exist in the target domain, and the types of interactions that can occur between them. Few systems today operate at this level, but those that do allow their users to find ‘meaning’ in the information they contain, and see information and relationships directly in terms of a mental model that relates to real word items of interest.
Finally, we have the Wisdom Level (WL). In this domain it is all about patterns within the knowledge. A system operating at the Wisdom Level allows its users to view new knowledge in terms of their entire repository of past knowledge, to see patterns in that knowledge, and to predict the intent of known or inferred entities of interest that those patterns imply. The key to a WL system is its ability to model what is truly going on, and to predict, by comparison with past patterns, what may be about to happen. Unfortunately, there are no information systems in existence that operate at the Wisdom level in any large or generalized domain. As a result, wisdom remains the exclusive purview of the people that use our current information systems.
We can associate other adjectives with the various layers of the information pyramid, for example if we consider the needs of how information is organized we can divide the pyramid as follows:
 Recognizing what the underlying data model is within any software system, and examining the levels of functionality required of the system in terms of where they lie in the knowledge pyramid is the key to understanding what it takes to successfully build such systems. Failure to address any incompatibilities invariably leads to ‘technical problems’, schedule delays, and often to project cancellation. It is critically important to understand knowledge levels in the ‘user workflow’ that a system must support since in the end it is that workflow the system is designed to enable and enhance.
Recognizing what the underlying data model is within any software system, and examining the levels of functionality required of the system in terms of where they lie in the knowledge pyramid is the key to understanding what it takes to successfully build such systems. Failure to address any incompatibilities invariably leads to ‘technical problems’, schedule delays, and often to project cancellation. It is critically important to understand knowledge levels in the ‘user workflow’ that a system must support since in the end it is that workflow the system is designed to enable and enhance.Despite this fact, software requirements today are written without any reference to or cognizance of knowledge levels, either within the system, or in the workflows it is designed to support. Little wonder therefore that large software projects tend to fail at alarmingly high rates.
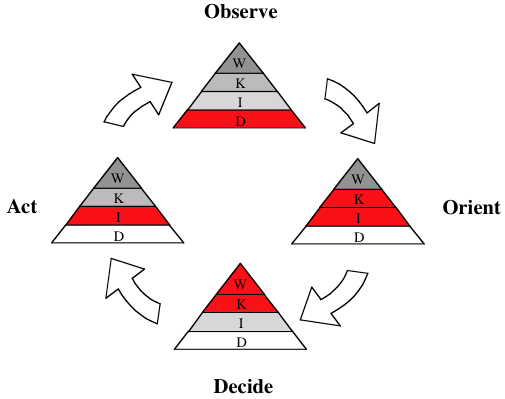
The diagram above illustrates a large Organization’s OODA loop (decision cycle – see here and here) in terms of the levels of the knowledge pyramid that are required to facilitate each step in the cycle. As can be seen, to close the cycle requires knowledge level activities in the ‘orient’ and ‘decide’ steps, and wisdom level (i.e., human in the loop) at the ‘decide’ step. Since we cannot currently create wisdom level software systems, all we can hope to do is provide extensive tools at this step to facilitate human decisions, while automating to the maximum degree possible the ‘orient’ step. To ‘orient’ generally involves integrating massive amounts of disparate data, and hence without automating this step within a system, it will be difficult if not impossible for human beings to keep up with ongoing events, thus making the remaining steps of the cycle moot.
Current generation information systems and design techniques fail to adequately address even the integration step required to ‘orient’, and thus in reality they cannot keep up with evolving events, and so they are at best retroactive tools to explain what went wrong. In the next post we will explore examples of issues and failures caused by mismatch between knowledge levels in the technologies that underly our systems, and the knowledge levels required by user workflows and queries that the systems are intended to support.