
In any distributed system involving heterogeneous computer nodes, over the long time frame the system designer must inevitably face up to the problem of endianness. For Mitopia®, this reality hit home in 1999 (when Apple transitioned from 68K to PowerPC processors), and then again in 2006 (with the transition from PowerPC to Intel 80×86 processors).
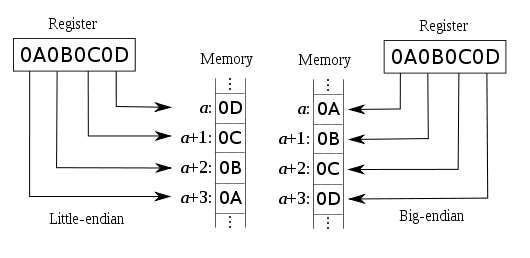
 Endianness refers to the ordering of the bytes when a multi-byte binary value (e.g., a 4-byte integer) is stored to memory (or sent over a network connection). A big-endian machine stores the most significant byte first (at the lowest byte address); a little-endian machine stores the least significant byte first. The two diagrams above illustrate the difference. Other architecture have even more exotic byte-ordering strategies. As long as all the data is read/written by exactly the same computer architecture, the programmer can remain completely oblivious of these details, however as soon as binary data goes between machines of different endianness, it becomes gibberish. For example if a little-endian machine sent a 4-byte integer with the value 1 to a big-endian machine, the receiving machine would receive it as the 4-byte integer value 1,677,216. Obviously this would cause some serious problems, especially in financial systems. The 68K and PowerPC are both big-endian machines, the Intel 80×86 on the other hand is little-endian.
Endianness refers to the ordering of the bytes when a multi-byte binary value (e.g., a 4-byte integer) is stored to memory (or sent over a network connection). A big-endian machine stores the most significant byte first (at the lowest byte address); a little-endian machine stores the least significant byte first. The two diagrams above illustrate the difference. Other architecture have even more exotic byte-ordering strategies. As long as all the data is read/written by exactly the same computer architecture, the programmer can remain completely oblivious of these details, however as soon as binary data goes between machines of different endianness, it becomes gibberish. For example if a little-endian machine sent a 4-byte integer with the value 1 to a big-endian machine, the receiving machine would receive it as the 4-byte integer value 1,677,216. Obviously this would cause some serious problems, especially in financial systems. The 68K and PowerPC are both big-endian machines, the Intel 80×86 on the other hand is little-endian.
A separate, but related problem is that of data-structure alignment differences between processors (and also between compilers, and even versions of the same compiler). This issue happens because different processors require different alignments for multi-byte values (e.g., 4-byte integers, 8-byte reals). For example, on the 68K, the compiler will align 4-byte integers on the nearest 2-byte boundary, on the PowerPC the preferred alignment is 4-byte (same as the size), however the CPU contains hardware to handle 2-byte aligned integers, and on the 80×86 architecture alignment must be 4-byte. If the programmer were to declare and then use a structure such as:
typedef struct MyStruct
{
Boolean myFlag;
int32 counter;
};
The result would once again be disaster as any data using this structure were passed. On a 68K the size of this structure would be 6 bytes, on Intel 8. Even different compilers within the same architecture may choose to align structure members differently. The result is that much as with the endianness problem, the alignment problem makes it hard to reliably pass binary data across a network of heterogeneous nodes. For any system deployed over decades, it is virtually guaranteed that these problems will rise up to bite you.
The classical solution to this problem is to convert data to/from a textual form when sending it between systems (or to/from file) so that regardless of either endianness or alignment, the receiving node will correctly interpret the values sent. This process is known as serialization. In the late 1990’s, most serialization strategies coalesced around the use of XML as the intermediate language. Unfortunately serializing and de-serializing is a time consuming process (last 3 paragraphs), and serialized data occupies far more space (and network bandwidth) than the binary equivalent.
For Mitopia®, from the outset we took the approach of storing and manipulating all data (in memory, in file, and in the ‘database’) in binary form using Mitopia’s flat memory model, and describing and accessing it using Mitopia’s Carmot ontology defintion language. This had the beneficial effect of removing any compiled types from the code that had anything to do with the data structures (see here), and thus avoided a whole host of the problems inherent in transitioning old data to new structures whenever the ontology changed. It also allowed all data to be stored in file and persistent storage directly in its binary form, and so avoided the performance penalties of the classical approach (see here). The performance penalties of a serialization approach were simply not acceptable (see here).
Thus it was that in 1999, when it came time to transition customer data from 68K machines to PowerPC replacements, we already had automated ontology-mapping tools in place and so, given the fact that both 68K and PowerPC were big-endian machines, we did not anticipate any problems with transitioning the data. The reality was somewhat more complex, largely because of alignment issues. As expected, there was little or no problem with any data accessed through the Carmot ontology, and this meant server data moved across without incident. However, in defining various structures that were part of communications packets and headers, we had not given sufficient regard to the alignment of the various elements within a structure. The result was that client server communications between mixed 68K and PowerPC nodes failed miserably. Fortunately, the PowerPC compiler had an option allowing you to specify that it use the (somewhat sub-optimal) 68K alignment rules when laying out structures and that helped somewhat. The option did not however work completely, so we were forced to add explicit padding bytes into all such structures. As a result, the 68K/PowerPC transition went fairly smoothly. The situation was quite different on the PowerPC/Intel transition in 2006.
In this transition, not only did the compiler option for 68K structure alignment go away, but also we were transitioning from a big-endian to a little-endian environment, with the reality being that installed systems would contain a mixture of each for some number of years. We now had to maintain operation on a heterogeneous network with different endianness between nodes. This meant we had to solve the following problems:
- All messages sent across the network containing structures must contain a ‘flag’ byte defining the endianness of the source. The receiving end must check for an endianness mismatch and if it exists, must re-map the bytes of every structure and structure element received to correct it. This includes of course any data collections sent over using the flat memory model, and described through the ontology. This correction process must happen within the low level environment so that all higher level code is unaware of the endian issue.
- Any binary data written to/read from file must also have a ‘flag’ byte and must be fixed for endianness when the file is opened if a mismatch is found. Once the file contents in their entirety have been fixed, the file must be re-written to disk using its new endianness so that subsequent accesses do not incur the performance penalty of correcting the mismatch. Once again, this includes all data collections written and saved using the ontology, but it also includes various other binary ‘flat’ structure types (e.g., string lists, preferences, etc.) used internally by Mitopia®. As for the network case, this mapping must happen transparently at the low level so that all higher level code is unaware that it occurs.
- Since Mitopia® server data is stored in a set of files using the flat memory model, the endian fixing will happen transparently within the server when it encounters a problem with its own data files. This means that one could simply copy the PowerPC data to an Intel replacement machine and immediately start up the server and issue queries, albeit that for a while the server response might be somewhat slowed (as it encounters a thus far unused data file, and is forced to convert it before proceeding with the query).