As mentioned previously (see here), the Carmot ontology definition language (ODL) is an extension of the C programming language, which itself is perhaps the most widespread and fundamental high level language in existence. Not only does Carmot add to the C language syntax, it also interprets existing C syntax/constructs to imply additional ontological semantics. Carmot is the only ‘contiguous‘ Ontology Definition Language (ODL) there is; normally ontologies have little or nothing to do with physical representation and are specified using separate syntax (see here). The advantages of a contiguous ontology are fully detailed here. Formost among those advantages is the role of a contiguous ontology in overcoming the software ‘Bermuda Triangle Problem‘. Because Carmot is built on C, it is assumed that the reader of this post is familiar with the C programming language itself, at least insofar as it is used to define and access types and structures.
 For a long time alchemists believed that a key component of the legendary “philosopher’s stone” was the mythical element carmot. The philosopher’s stone, it was believed, had the power to transform base metals to gold. In an information sense, Mitopia’s Carmot ontology software and ODL is the key component that allows Mitopia® to accomplish the unique things it does in transforming information into knowledge (see here).
For a long time alchemists believed that a key component of the legendary “philosopher’s stone” was the mythical element carmot. The philosopher’s stone, it was believed, had the power to transform base metals to gold. In an information sense, Mitopia’s Carmot ontology software and ODL is the key component that allows Mitopia® to accomplish the unique things it does in transforming information into knowledge (see here).
This post is the first in a sequence of 7. Click here to get to the next post.
The basic extensions the Carmot ontology definition language adds to C are directed at the following:
- Eliminating the use of pointers so that memory is ‘flat’ and can be manipulated and shared as a contiguous collection (see here).
- Extending the language to provide one-to-one and one-to-many references that persist beyond the current running process. C supports only non-persistent in-memory pointer references.
- Support for inheritance and a tie-in between types and the system server topology.
- Support for associating scripts and annotations with types and fields.
Since Carmot is a superset of the C programming language and is required to compile the C headers files for the underlying platform so that all declared C types are available for use prior to examining the actual ontology definition itself, the language supports all of the C keywords and symbols including the ability to interpret certain C preprocessor symbols (those that start with a ‘#’ character). Remember that Carmot is actually the language understood by Mitopia’s type manager which is responsible both for handling the underlying platform C types as well as the extended types found in the system ontology.
Complete documentation for Mitopia’s type manager can be found elsewhere. In this post we will focus simply on the ontological aspects of the Carmot language. The primary motivation behind the Carmot language were:
- To unify the programming model between in-memory and persistent (conventionally in-database) data, thus eliminating the ‘Bermuda Triangle‘ problem.
- To facilitate efficient data-flow based systems so that complex inter-related data sets can be shared across nodes without the need to serialize/de-serialize. See here for details.
- To express the additional behaviors necessary to handle ontological interactions between defined types (see here for problems with current taxonomic approaches).
New Keywords and Symbols
Carmot adds the following operators/symbols to the basic C language in order to provide support for the items described above:
- script — used to associate a script with a type or field – see here
- annotation — used to associate an annotation with a type or field – see here
- @ — relative reference designator (like ‘*’ for a pointer) – see below
- # — persistent reference designator – see here
- @@ — relative collection reference designator – see here
- ## — persistent collection reference designator – see here
- <on> — script and annotation block start delimiter – see here
- <no> — script and annotation block end delimiter – see here
- ><, ?><, and ><>< — echo field specification operators – see here
- : — type inheritance – see here
Carmot also has a number of other C extensions, however in this post (and the others in this sequence) we will focus just on the basic list above, since an understanding of these key features in necessary before discussing other aspects of Mitopia®. Mitopia’s flat memory model (see discussion
here – prerequisite for understanding some of the details below) underlies virtually all data held in or described by the Carmot language, but the language is also designed to address the needs of a next generation
knowledge-level database architecture (see discussion
here) as opposed to today’s
information-level databases.
The ‘@’ symbol – relative reference
The relative reference denoted by the ‘@’ symbol is a relative offset (ET_Offset) from the start of the ET_Simplex record (see here) containing the actual value of the ontological type to the start of another ET_Simplex record which contains the data referenced. The referenced ET_Simplex record is a child of the referring ET_Simplex record (i.e., the ‘parent’ field in it’s header refers back to the referring ET_Simplex) which means that the only way to navigate to the referred record (other than by following the ‘nextItem’ links through all structure headers of course) is to follow the referring field. Functionally the ‘@’ reference can be considered and used in a manner identical to a pointer ‘*’ reference except the address reference is relative rather than absolute, so the reference can only be followed by using the abstraction layer.
The main use of the relative reference is to allow variable sized data to be referred to from within a referring type structure so that the referring structure does not have to allocate fields containing large blocks of empty space which are not used in most cases. This is a common problem in any large data representation, and this problem is most serious with the relational database model for which the concept that everything can be represented as tables with fixed-size cells causes all kinds of issues for database administrators (see here). The problem most often occurs with variable sized text fields but is also an inherent issue with incorporating any kind of multimedia data into persistent storage. Mitopia’s memory model strategy and the use of the relative reference effectively overcomes this issue.
The most common use of the ‘@’ reference is in conjunction with variable sized text fields. In a conventional relational database, one must usually decide on the largest number of characters that might be part of a given field and then allocate a table containing this maximum number for each occurrence of the field. Of course almost invariably one finds that there are cases where the allocated field size is not big enough and then the DBA must modify the database structure to allow for larger field values which, as a consequence, wastes more storage since the majority of the instances do not require this additional space. Furthermore, in a relational database, making a field a reference to a variable sized record (termed a ‘BLOB’) has considerable cost and results in vastly reduced search functionality in many cases. In Carmot, one simply doesn’t think about these things. There is virtually no cost associated with declaring a field as a relative reference, and by so doing, one can forget about limitations on field size, and no more storage is required than necessary to hold each field exactly. Furthermore, if a field is empty (as most are in realistic data sets), the only storage allocation is the 32-bit ET_Offset (set to zero) which is the physical field value in the referring data structure. The code snippet below shows the declaration of the first few fields of the root type of all persistent data “Datum” in Mitopia’s standard Carmot ontology:

In the declaration above, we see that there are three text fields declared, two are declared as relative references ‘@’ and one ‘datumType’ has a fixed size. The overwhelming majority of text fields in Mitopia’s standard ontology are declared as relative references because in reality for a system where data can come from a wide variety of sources, many of them published or open source and not derived from a database, it becomes very difficult to be sure that any text field can be relied on to fit into a reasonably small fixed sized allocation. Examining the logic behind the three choices shown above is perhaps instructive in this regard. Firstly consider the ‘name’ field of the record. Remember that every data type in persistent storage is derived from Datum, so one must allow enough room to hold the name of any conceivable kind of thing that may be held in the system.
A typical relational DBA might think about person names and then double what they would guess was the worst case to come up with the equivalent to “char name[80]” as the field specification, lets face it, 80 characters ought to be enough for any name right? Wrong! Remember that the name of every type of data will go into this field so as soon as we start mining our first external source into the system, the CIA World Fact Book say, we run into a political party (organization) with the name:
“National United Front for an Independent, Neutral, Peaceful, and Cooperative Cambodia (FUNCINPEC)”
which weighs in at a trim 97 characters! OK the DBA says, lets make the field 128 characters, that has to be enough. Wrong again! Remember that we are handling multilingual data encoded in UTF-8, not just English. On average it takes 2 bytes per Arabic character, 3 bytes per Korean character and for some languages up to 6 bytes per character. It should be very obvious that in such a multi-lingual scenario, not even the name of a record can be limited to less than a few hundred bytes in any multi-source system. For this reason then, the name field of Datum is a relative reference and thus can grow as large as needed for these extreme cases while occupying much less storage in the majority of non-extreme cases. The key point here is that the sources of data that might be fed into a system do not have constraints, and so the system itself cannot try to artificially limit text field size.
A very similar but much stronger argument can be made for the ‘@aliases’ field which is an open ended comma-separated list of all the known aliases for the item concerned. This list clearly could be massive. Indeed in the “GeoNames” source for world place names (see geonames.org), the translation of the place name into a number of world languages is given as a comma separated list. These translations clearly belong in the ‘@aliases’ field since they are effectively the same as an alias for the place. Below is the value of this string for Frankfurt , Germany:
Given the fact that this string contains characters encoded in a variety of multi-byte languages, one can only guess at how long the field actually is. Once again, in the overwhelming majority of records in persistent storage, the ‘@aliases’ field will be completely empty, so the relative reference strategy becomes invaluable for improving efficiency and eliminating wasted space without incurring limitations.
Finally, we see in the code snippet above that the ‘datumType[32]’ field has been declared to have a constant fixed size of 32 characters/bytes. Why is this different from the other cases? The answer is that the ‘datumType[32]’ field contains the name of the actual data type (e.g., Person, Organization, Source etc.) and is filled out automatically by the underlying architecture. It cannot be entered any other way than by picking a type from the ontology. Type names in the ontology are constrained by the system to be in English only, to never be empty, and to have lengths that are less than 32 characters. It is therefore completely safe to declare the ‘datumType[32]’ field to have a fixed size in this manner. We will not be wasting space, since the overhead in terms of space for the additional non-empty ET_Simplex record of a relative reference (roughly 48 bytes) exceeds the declared field size. Overall we are saving space.
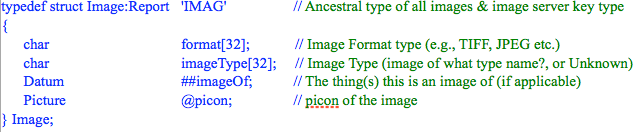
The uses of ‘@’ references are not limited however to variable-sized text fields. In the standard ontology, we also find the definition of the type ‘Image’ as shown in the code snippet below:
The ‘@picon’ field in the Image type is a relative reference to some data of type ‘Picture’ and the type ‘Picture’ is actually declared in the platform C header files, that it is the basic type the OS uses to hold and manipulate images. Firstly, this declaration indicates the intimate connection between the types and fields used in the Carmot ontology definition, and all the underlying C types declared as part of the operating system development platform. This is a huge difference between a contiguous ontology like Carmot, and standard disjoint ontologies (semantic or otherwise). At first sight, a programmer might mistake the Carmot type definitions above for straight C code. Contrast this with a small snippet of an OWL ontology such as:
Nobody looking at the OWL ontology snippet above is likely to mistake it for something that has anything to do with a normal programming language. It looks like, and is, a weird XML payload.
The ‘@picon’ field refers to the type ‘Picture’ and this type is not handled by the default MitoQuest™ container within the system servers since MitoQuest™ registers with MitoPlex™ to handle the following field types only:
- All text fields and all fields that are references of any kind to text.
- All fields that are descendent from integer or real numbers (includes dates).
- All persistent and collection reference fields (both ‘##’ and ‘@@’).
Of course the list above covers pretty much every field in the ontology, it basically only excludes multimedia types and relative or pointer references to them. This of course is what one would want since multimedia types generally require specialized handling and so we would like that all other fields are handled automatically by the underlying architecture (in this case MitoQuest™) while leaving fields for specialized types to be handled by specialized code. Unless some other code registers to handle the type ‘Picture’ and references thereto, Mitopia® will be unable to fetch the field from persistent storage or to display and/or query the field. For this reason, if one looks in the source file “ServerPlugins.c” which is supplied basically as example code with every Mitopia® installation, you will see that the function SPG_IsImageField() is registered with MitoPlex™ to determine if the type or field type relates to the type ‘Picture’ and if it does, the Image server (key data type ‘IMAG’) is declared to be responsible for the data and the “Image” container is declared to be responsible for accessing and/or searching the field.
This same technique is used to tie all multimedia types into the ontology. In fact, because the data is referenced as “Picture @picon” in the ‘Image’ type, that is, it is a relative reference to a variable sized block of data, the ‘Image’ server does not need to add any specialized code to fetch the ‘picon’ value.
This is because as we have said, relative references (‘@’) are completely handled within the flat memory model, which means that the data will already be present after the MitoQuest™ container has fetched the fields of the referencing structure. The ‘Image’ server does however need to concern itself with fetching and processing the original full sized image file that gave rise to the ‘picon’. This external file holds the actual multimedia data of which the ‘picon’ is simply a small representation for rapid display purposes. Registered ‘Image‘ server code will also be required to query image content (e.g., a fingerprint recognizer, face recognizer, etc.); this level of registration is fully supported within the Mitopia® MitoPlex™ abstraction. We will discuss server aspects in later posts.
It should be clear from the discussion above that the capabilities of the Carmot language cannot really be separated from the Mitopia® architecture that underlies it. This is perhaps a fundamental property of any contiguous ontological system. Carmot is leveraged throughout Mitopia® to provide all areas of functionality in an adaptive manner. Mitopia’s patented flat memory model is thus essential to the Carmot language, as are many other patented areas of the architecture. In this sense then, Carmot is not a general purpose ontology language, it is specific to Mitopia® with which it is contiguous.
In the following posts in this sequence, we will discuss some of the other C extensions listed above and their purposes.
Click here for the next post in this sequence.