Despite its intelligence software roots, as stated previously (here and here), Mitopia’s base Carmot ontology evolved primarily out of pragmatic and implementation considerations regarding the creation of a data-flow based system, and the necessity to efficiently represent and organize data in a generalized form that could be discovered and leveraged in a reusable manner over data flows, by individual and unconnected islands of computation. By training, I am a physicist, thus, given my ignorance of ontologies at the time (1993), when faced with the question of how to organize and represent information about anything in existence for the purposes of understanding world events, there was a natural tendency to gravitate towards thinking of things in terms of the scientific method. The scientific method, as everyone knows, can be summarized as follows:
- Identify a problem
- Form a hypothesis
- Design and perform Experiments
- Collect and Analyze the experimental data
- Formulate conclusions about the hypothesis
- Repeat (2)-(5) until reality appears to match theory in all test cases.
This post is part 3 of a sequence. To get to the start click here.
Essentially the scientific method is the only process/tool that has ever succeeded in explaining how the world works and what kinds of interactions can occur between things in the world, in a manner that gives any predictive power to allow us to reason what might be the results of some new situation in the absence of experimental results to tell us. Everything we take for granted in the modern world was developed by this process, and so it seemed clear to me at the time that any intelligence software or system for organizing data for the purposes of ‘understanding’, must also be based on this premise. This is clearly contrary to the approach taken in any of the semantic ontologies described earlier, and yet it seems such an obvious approach, it is hard to understand why this is the case. Perhaps the difference reflects the fundamentally different approaches between science and philosophy. Since philosophy has spawned all other ontologies, it is perhaps not surprising that the scientific method does not feature in any fundamental way in conventional ontologies.
 |
| Simplified diagram of a Particle Physics Experiment |
If we wish to understand all that goes on in the world, the worst-case requirements we can imagine would be those for an intelligence agency striving to monitor world events; we should design our ontology to handle this application.
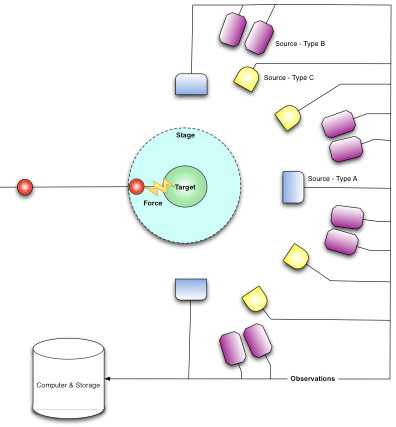
Given the premise that the scientific method should be the underpinnings of Mitopia’s ontology, the next question was to ask in exactly what ways does the problem of “observing the world for intelligence applications” have any parallels with conventional scientific experiments. Perhaps the most successful scientific experiments in exposing the true workings of the world around us have been those performed in high energy physics within accelerators. These experiments are designed to investigate the building blocks of matter, and the forces that act between them. If we draw a generic diagram of any accelerator experiment, it would consist of firing a stream of particles into a target located in an environment or ‘stage’ that is ringed by a set of different detectors, each capable of detecting different kinds of particles resulting from the ‘event’ that happens when one of the particles strikes the target. The output from all detectors results in a stream of ‘observations’ of differing types and accuracy (depending on the detector or ‘source’ accuracies). These observations are recorded into the computer system for later analysis to determine what ‘event’ might have happened.
 |
| Particle physics ‘event’ viewed through a scientific ontology |
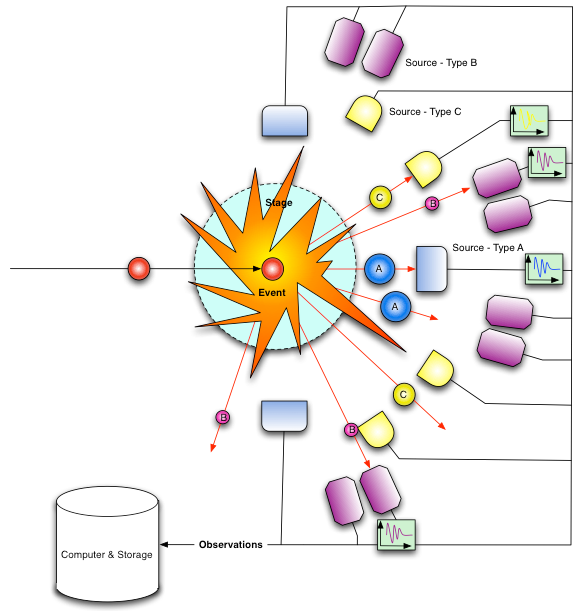
The situation after such an event occurs appears similar to that shown to the right. The colliding particle and the target have exchanged some ‘forces’ between them in an ‘event’, with the result that the target has been broken up into its constituents which we can observe as they are detected by the various sources arranged around the ‘stage’ in which the ‘event’ occurred. Of course not all the resultant particles are detected by our sensor array; we get only a partial snapshot of what actually happened. The goal of the analysis is to postulate a model for what might have happened and examine the observation stream for events that might consist of the interaction we are interested in. We then total up all the resultant bits we see in these events, and deduce what other bits we must be missing for the total energy to be conserved. By sampling multiple candidate events we are able to get a complete picture of what is actually happening in the ‘event’ and determine if the experimental results match our theoretical model. If they do, we pronounce our theory ‘good’ and we use it to model other as yet unseen situations until such time as the theory fails to match the results of some new experiment at which time we start over again on a new theory.
This then is the process that physicists use to ‘understand’ the world around us. A very similar approach can be found in virtually all science experiments. Thus if we are to begin to categorize the various distinct things that make up what we need to track to ‘understand’ the world in a physics sense, we come up with the following top level list, nothing more, nothing less:
- Particles (beam, target, debris)
- Forces
- Stage/Environment
- Observations
- Sources
- Events
If we now consider the intelligence software process, that is what do we have to track to ‘understand world events’, we could once again draw an idealized diagram of such an experiment and it would appear as shown below.
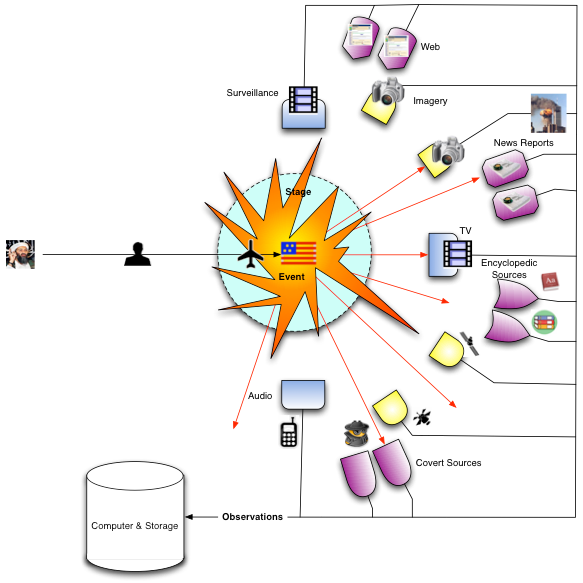 |
| A real world event viewed through Mitopia’s base ontology |
Essentially the problem is the same. Again we are interested in tracking the ‘events’ that happen, again those events happen in a ‘stage’ or environment that effects the behavior of the players and must thus be tracked carefully. Again we have a stream of ‘observations’, but this time from a much wider variety of ‘sources’ of vastly differing reliabilities which must be tracked carefully if they lead to any analytical conclusions. In the real world, we are interested not in particles and forces , but instead in ‘actors’ (mostly ‘entities’) and ‘actions’ which are conceptually analogous.
In other words, all we have to do is modify our terms slightly from the physics experiment and we have the set of things that must be tracked to ‘understand’ real world events. They are:
- Actors
- Actions
- Stages
- Observations
- Sources
- Events
Clearly then we have found the fundamental groupings which should form the top level of our
ontology of everything as shown below.
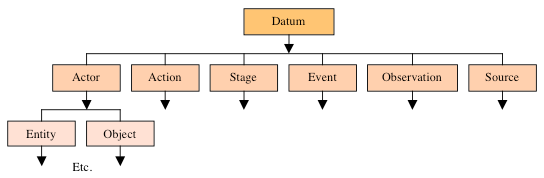 |
| Top level of Mitopia’s patented base ontology |
Remember, this ontology is based on the scientific method and is intended to allow organization and interrelation of actual data gleaned from the real world. We intend to use this ontology to generate and maintain our ‘database’ and the queries on it. This is in stark contrast to semantic ontologies which are targeted primarily at the problem of understanding the meaning of human written communication and the ideas expressed in that communication. Given this difference in intent, it seems hard to argue with the the top level arrangement used in Mitopia’s base ontology. With this choice of upper ontology, we have in one step chosen to organize our data in a manner that is consistent with ‘understanding’ it and we have simultaneously chosen the fundamental method we will use to analyze the data for meaning, that is the scientific method. This ontology has been chosen to facilitate the extraction of meaning from world events, and does not necessarily correspond to any functional, physical or logical breakdown chosen for other purposes, though given the discussion above, it is expected that the overwhelming majority of phenomena can be broken down according to this scheme.
- Datum – The ancestral type of all persistent storage.
- Actor – Actors participate in Events, perform Actions on Stages and can be observed.
- Entity – Any ‘unique’ Actor that has motives and/or behaviors, i.e., that is not passive. People and Organizations are Entities, and understanding what kind of Entity they are and their interdependence is critical to understanding observed content.
- Event – Events are conceptual groupings of Actors and Actions within a Stage, about which we receive a set of Observations from various Sources. It is by categorizing types of Events into their desirability according to the perceiving organization, modeling the steps necessary to cause that Event to happen, and looking in the data stream for signs of similar Events in the future, that a knowledge level intelligence system performs its function.
- Object – A passive non-unique actor, i.e., a thing with no inherent drives or motives such as a piece of machinery. Entities must acquire and use precursor Objects in order to accomplish their goals and thus we can use objects to track intent and understand purpose.
- Stage – This is the platform or environment where Events occur, often a physical location. Stages are more that just a place. The nature and history of a stage determine to a large extent the behavior and actions of the Actors within it. What makes sense in one Stage may not make sense in another.
- Action – Actions are the forces that Actors exert on each other during an Event. All actions act to move the Actor(s) involved within a multi-dimensional space whose axes are the various motivations that an Entity can have (greed, power, etc.). By identifying the effect of a given type of Action along these axes, and, by assigning entities ‘drives’ along each motivational axis and strategies to achieve those drives, we can model behavior.
- Observation – An Observation is a measurement of something about a Datum, a set of data or an Event. Observations come from sources. Observations represent the inputs to the system and come in a bewildering variety of formats, languages, and taxonomies. The ingestion process is essentially one of breaking raw Source Observations into their ontological equivalent for persisting and interconnecting.
- Source – A Source is a logical origin of Observations or other Data. Knowledge of the source of all information contributing to an analytical conclusion is essential when assigning reliabilities to such conclusions.
The goal of an intelligence software system is still to reconstruct what event has occurred by analysis of the observation data streams coming from the various sources/feeds. The variety of feed and sensor types is infinitely larger than in the particle physics case, however, as for the particle physics case, many effects of the event are not observed. The major difference between the two systems is simply the fact that in the intelligence software system, the concept of an event is distributed over time and detectable particles are emitted a long time before what we generally think of as the event itself. This is simply because the interacting ‘particles’ are intelligent entities, for which a characteristic is forward planning, and which as a result give off ‘signals’ that can be analyzed via such a system in order to determine intent. For example in the 9/11 attacks, there were a number of prior indicators (e.g., flight training school attendance) that were consistent with the fact that such an event was likely to happen in the future, however, the intelligence community failed to recognize the emerging pattern due to the magnitude of the search, correlation, and analysis task. This then is the nature of the problem that must be addressed and as mentioned previously, we refer to systems attempting to address this challenge as “Unconstrained Systems”. In an Unconstrained System (UCS), the source(s) of data have no explicit knowledge of, or interest in, facilitating the capture and subsequent processing of that data by the system.
Now that we have chosen the basic organization of our ontology, we must address one last issue which is that the fundamental purpose of an intelligence software system is to recognize the patterns that lead up to a particular type of event, and if that event is undesirable, to provide warning before it occurs, so that steps can be taken to avoid it. In this regard an intelligence software system is quite different from a physics experiment in that we seek to recognize the signature of an event before it happens rather than after.
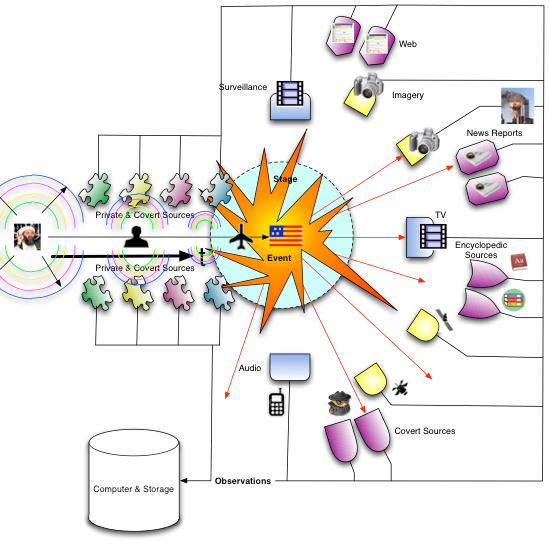
As mentioned above, we can address this issue quite simply by recognizing that thinking entities (the types of actors we are most interested in) take actions before an event they are planning to participate in, in order to get ready for that participation. Thus we must redesign our experiment slightly to gather information on a continuous basis up-stream in the time line as shown in the figure below.
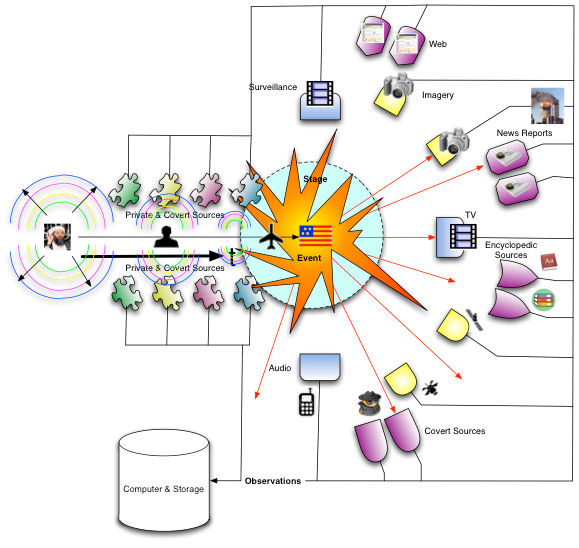 |
| Understanding and analyzing world events through Mitopia’s base ontology |

 These up-stream sensors tend to be private or covert feeds rather than open source and thus they are things like passport and travel data, financial transactions, licenses and police reports, communications intercepts, HUMINT, etc. The nature of these feeds in general is that they are more reliable and contain data with high semantic content that can be connected via link analysis to other encyclopedic data. This is important since these upstream sources must be sensitive to far lower ‘signal levels’ than those typically associated with an actual publicly perceptible event which includes media attention. These sensors are examining the ‘ripples’ in the pond and looking for correlations between them whereas the post-event sensors are examining the actual splash. It is the degree to which a system is able correlate between the various types of low level ripples that precede an event in order to recognize a significant pattern of intent, that determines how well the system itself functions in a predictive capacity.
These up-stream sensors tend to be private or covert feeds rather than open source and thus they are things like passport and travel data, financial transactions, licenses and police reports, communications intercepts, HUMINT, etc. The nature of these feeds in general is that they are more reliable and contain data with high semantic content that can be connected via link analysis to other encyclopedic data. This is important since these upstream sources must be sensitive to far lower ‘signal levels’ than those typically associated with an actual publicly perceptible event which includes media attention. These sensors are examining the ‘ripples’ in the pond and looking for correlations between them whereas the post-event sensors are examining the actual splash. It is the degree to which a system is able correlate between the various types of low level ripples that precede an event in order to recognize a significant pattern of intent, that determines how well the system itself functions in a predictive capacity.
Unfortunately, most of the effort and expenditure exerted by intelligence agencies today is focussed on gathering more different types of data, with higher accuracy, while little if any progress is made on the far more important intelligence software problem of seeking coherence of intent in the ripples from these up-stream feeds. We can now read license plates from space, but we still rarely know where to point such amazing sources before the event.
The mistake is to treat the intelligence software problem in the same way as one conventionally treats almost every other real world problem. To improve understanding post-event (right-of-bang in military parlance), all one really needs is more data with higher accuracy, and so it is easy to fall into the trap of thinking that this will also solve the pre-event (left-of-bang) issue, especially when demonstrations of new technology to potential purchasers are given using post-event historical data in order to clarify what difference the technology might have made in a known historical event. When seeking coherence and correlation in low intensity pre-event data streams, the issue is primarily one of removing the overwhelming amount of noise or insignificant data, from the tiny amount of significant data that may be mixed into the stream. In any real world scenario looking for correlation up stream, the noise is likely to outweigh the signal by many orders of magnitude, and so our analysis techniques must be able to operate in this setting. Only by organizing and interconnecting data in a rigorous ontological manner that is firmly based on an upper level ontology tied to the scientific method, is it plausible that the highly indirect series of connections that make up significance in the presence of overwhelming noise, can be discovered and extracted in a reliable manner.
Our approach to ontology must focus first on assembling the content and connections implied in the stream of observations and meta-data that make up our limited picture of the world. Much of this information is extracted by non-linguistic techniques from meta-data or by inter-source combination.
Only once this firm representation of the variety of observations and sources is in place should we consider refinement of our ontology based on linguistic and/or semantic processing of individual textual observations to understand the intent of human speech. Conventional systems cannot unify multiple sources and thus are restricted to attempting understanding based on semantic analysis of text, but this misses virtually all of the most reliable and telling connections that come from a fully contiguous ontological approach (see discussion here). This then is the philosophical reason behind the unique organization of Mitopia’s base ontology.
Fortunately all the thinking above took place in the early 90’s, long before I became aware of the existence of such things as ontologies. It was not until December 2,000 during a presentation to a US intelligence agency that I learned the meaning of the word ontology, and subsequently discovered the approach others were taking to using ontologies within computers. By that time Mitopia’s path had been set long ago, and comparison to other ontological approaches at the time made it clear, in my mind at least, that there was every reason continue to ignore conventional wisdom. This decision has I think been born out by the relative lack of progress in the semantic ontology field, notwithstanding the huge efforts made.
After that meeting in 2,000 I started to use the word ontology to try to help listeners understand the Mitopia® approach. In retrospect, it seems I traded off the utility of a known word ‘ontology’ for the burden of distinguishing my use of that word from the semantic/linguistic version implied by all others. This post, and those that led up to it, is just the latest example of this reality.