 In earlier posts we discussed various problems with current approaches to information representation that are ultimately the result of a failure to decouple data organization and access from the underlying computer memory architecture. The shortcomings of this approach do not become obvious until one scales and distributes a system, and simultaneously introduces the requirement to handle rapid changes in requirements, data formats, and the data relationships that a system must handle.
In earlier posts we discussed various problems with current approaches to information representation that are ultimately the result of a failure to decouple data organization and access from the underlying computer memory architecture. The shortcomings of this approach do not become obvious until one scales and distributes a system, and simultaneously introduces the requirement to handle rapid changes in requirements, data formats, and the data relationships that a system must handle.When boiled right down to the basics, it is the need to ‘point’ from one memory block to another in order to create a link or relationship that can be manipulated rapidly by code that causes the following issues:
- Serializing and de-serializing from a textual intermediate (usually XML) in order to pass complex connected data sets is a huge burden (more than 250 times slower than a straight binary transfer) in distributed systems passing many such packets across nodes. (see here)
- Glue code necessary to convert to/from pointer-based representation in memory and a file based (using file indexes), or database (relational representation through SQL) comes to dominate the code base and severely reduce code adaptability in all large systems. The issue is that the programmer must translate every action between at least 3 different representation forms.
- Passing pointer based representations across data flows or process boundaries is not possible (without serializing) and thus limits data sharing fidelity significantly. It is not possible for two processes to share access to and manipulate the same copy of any complex data since their address spaces are distinct and thus pointer links are meaningless.
- Converting between multiple representations moves type-specific knowledge into the compiled code and out of the data itself. This makes run-time type discovery and manipulation (see here) difficult and the overall code base rigid and inflexible (see here) because it must be carefully updated and recompiled when data formats and connections change.
In summary, failure to abstract away the Von Neumann memory model (see here) of today’s digital computers forces a divergence between all the ways that complex data is stored and manipulated. This divergence is directly responsible for creating the concept of a separate database. Overcoming this divergence is at the heart of all systems-integration problems and is the root of much software complexity and expense. The concept of pointers and memory allocation is built into every programming language. In OOP languages the ‘new’ operation serves to enshrine pointers even further into the programming substrate thus making the divergences harder still to deal with. In a real sense then, the problem is perpetuated by our existing programming language metaphors, which rarely if ever consider the needs of manipulating relationships beyond a single program run (without the programmer having to explicitly code to use files or databases to do it).
Data is data, the relationships between datums should persist beyond a given program run and the programmer should not have to explicitly acknowledge any difference between transient (in memory) and persistent (in a DB or file) data. It should require special measures to distinguish the difference, and all operations by code ‘in the box’ should apply identically regardless.
As a result of the issues described above (and others), the original design concept for Mitopia® from the outset made 100% run-time discovered types and the complete elimination of the ‘pointer’ as a means of representing the relationship between two things, a key and inviolable requirement of all system data related Mitopia® code. This realization, and the resulting design approach, began as early as 1989.
Of course by throwing out the convenience of pointers as a representation of relationships, we will pay a terrible price in terms of the amount of substrate code that must be developed to replicate all that pointers give us without actually using them. The programmer trained in classical memory representation techniques and in classical a coding techniques (e.g., linked lists etc.) will also require major re-training to use the new model. Indeed, the substrate must implement essentially any and all generalized aggregation techniques that might be needed so that the programmers ‘in the box’ (see here) never need to drop below the ‘thou shalt not use pointers’ barrier. This represents a huge undertaking on behalf of the underlying environment. The benefit however is a ‘box’ world view that cannot distinguish persistent data from transient data, and within which data sharing or persisting requires no conversions of any kind. The content of this post presents just the most basic aspects of this critical transition in thinking. We will call the approach the ‘flat memory model’.
The key innovation of the ‘flat memory model’ is the elimination of the pointer for describing inter-structure references, and its replacement by a relative reference. The purpose of the relative reference is to eliminate non-flat references (i.e., pointers) so that all data in a collection can be contained in a single contiguous allocation, and, since all references are relative rather than tied to any particular memory address, the collection can now be shared in binary form across processes and machines without modification. This ability to pass entire collections including arbitrarily complex and nested cross references as a single unit is fundamental to implementing an efficient data-flow based system. In all persistent types (those that are part of the ontology, rather than the underlying platform), the use of pointers is disallowed and this in turn allows easy and efficient sharing and implementation of the server ‘database’ functionality by the architecture.
The cost for disallowing the pointer within ontological types is the need to re-educate programers accessing data within Mitopia® to think in terms of the flat memory model. This can be difficult for some since we are all familiar with how to construct links and relationships using pointers in memory, but these techniques we now know will cause irreparable harm when we scale our system, or subject it to rapid change. Data held within Mitopia® can only be accessed through the flat memory model abstraction and using run-time type discovery via the ontology/type manager. You can’t get a pointer to such a data record, there is no such thing.
The full details of Mitopia’s flat memory model (which is covered by a number of patents) are beyond the current scope, however the following is a brief introduction in order to facilitate understanding of other concepts that will be introduced in later posts.
A relative reference is actually implemented as a signed 32-bit integer value of type ET_Offset. In order to support the flat memory model abstraction, we require that all structures stored within the contiguous block (referred to henceforth as a handle) that is the collection, start with a standard header block of type ET_Hdr which is not visible to standard ‘box’ code using the structure contents, but is accessed and manipulated by the underlying architecture code in order to provide the flat memory model abstraction. The content of this header structure is essentially as shown below:

This header allows for a series of structures to be concatenated within a contiguous block, and yet accessed and navigated in an efficient and flexible manner.

The diagram to the right illustrates a simple initial state for a handle containing multiple structures. The handle contains two distinct structures, A and B. Each structure is preceded by a header record which defines its type and its relationship to other structures in the handle. As can be seen from the diagram, the ‘NextItem’ field is simply a daisy chain, where each link gives the relative offset from the start of the referencing structure to the start of the next structure in the handle. Note that all references in this model are relative to the start of the referencing structure header and indicate the (possibly scaled) offset to the start of the referenced structure header. The final structure in the handle is indicated by a header record (with no associated additional data) where ‘NextItem = 0’. By following the ‘NextItem’ daisy chain it is possible to examine and locate every structure within the handle. In future diagrams, the ‘nextItem’ link will not be drawn since it is always as illustrated above. From the diagram we can see also that the ‘parent’ field is used to indicate parental relationships between different structures in the handle. Thus we can see that structure B is a child of structure A. The terminating header record (referred to usually as an ET_Null record) always has a parent field that references the immediately preceding structure in the handle, even though this does not represent a logical relationship, it is simply a convenience to allow easy addition of new records to the handle. Similarly, the otherwise meaningless ‘moveFrom’ field for the first record in the handle contains a relative reference to the final ET_Null. Again this is simply an expedient to allow rapid location of the logical end of the handle without the need to daisy chain through the ‘nextItem’ fields.
The right hand side of the diagram illustrates the situation after adding a third structure ‘C’ to the handle. As can be seen, ‘C’ is a child of B (grandchild of A). The insertion of the new structure essentially involves the following steps:
- If necessary, grow the handle to make room for C, C’s header, and the trailing ET_Null record.
- Overwrite the previous ET_Null by the header and body of structure C.
- Set up C’s parent relationship.
- Append a final ET_Null, with parent referenced to the C structure header.
- Adjust the ‘moveFrom’ field of the initial structure to reflect the offset of the new terminating ET_Null.
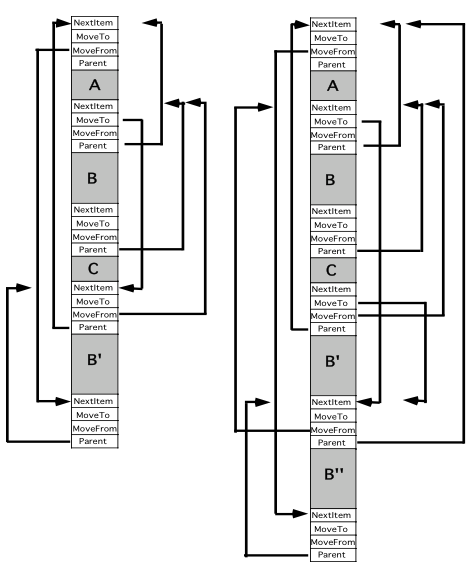 The ‘moveFrom’ and ‘moveTo’ fields come into play when it is necessary to grow a given structure (B say). Since in general there will be another structure immediately following the one being grown (C in this case), we might be tempted to move all trailing structures down to make enough room for the larger B. This, in addition to being extremely inefficient for large handles, would cause all kinds of headaches because relative references that span the original B structure would be rendered invalid once such a shift had occurred. To repair this damage, we would have to scan the whole handle looking for such references and altering them. The fact that the actual bodies of the A,B, and C structures will generally contain relative references over and above those in the header portion make this impractical without knowledge of all structures that might be part of the handle (which might not be possible). For this reason we introduce the moveFrom and moveTo fields. The diagram to the left illustrates the situation after growing B by adding the enlarged B’ structure to the end of the handle as described above.
The ‘moveFrom’ and ‘moveTo’ fields come into play when it is necessary to grow a given structure (B say). Since in general there will be another structure immediately following the one being grown (C in this case), we might be tempted to move all trailing structures down to make enough room for the larger B. This, in addition to being extremely inefficient for large handles, would cause all kinds of headaches because relative references that span the original B structure would be rendered invalid once such a shift had occurred. To repair this damage, we would have to scan the whole handle looking for such references and altering them. The fact that the actual bodies of the A,B, and C structures will generally contain relative references over and above those in the header portion make this impractical without knowledge of all structures that might be part of the handle (which might not be possible). For this reason we introduce the moveFrom and moveTo fields. The diagram to the left illustrates the situation after growing B by adding the enlarged B’ structure to the end of the handle as described above.As can be seen, the original B structure remains where it is, and all references to it (such as the parent reference from C) are unchanged. B is now referred to as the “base record” whereas B’ is the “moved record”. Whenever any reference is resolved now, the process of finding the referenced address (which is of course transparently performed by the underlying flat memory model code) must be aware of the possibility of such moves. The code snippet below illustrates the operations involved:

Further, whenever a new reference is created, the process is:

This logic ensures that no references become invalid, even when structures must be moved as they grow. Note that in the right hand side of the diagram, B’ itself has been grown to yield B’’. In this case the ‘moveTo’ of the base record directly references the latest version of the structure (B’’ in this example), correspondingly, the latest record B’’ now has a ‘moveFrom’ field that references the base record. B’s moveFrom still refers back to B and indeed if there were more intermediate records between B and B’’, each one’s ‘moveTo’ and ‘moveFrom’ would form a doubly linked list. Thus we see that it is possible to re-trace through all previous versions of a structure via these links.
There are a great many other logistical details required to support this model, however, for our present purposes, we have enough understanding of the basics of the flat memory model to go on to briefly examine the implementation of Mitopia’s collections abstraction (which is built on the flat model by the TypeCollections package).
The ‘flags’ field of the header record is logically divided into two portions. The first portion can contain arbitrary logical flags that are defined on a per-record type basis. The second portion is used to define the structure type for the data that follows the header. While the full list of all possible structure types used by Mitopia® is beyond the current scope, the following basic types relate directly to the collection metaphor:
- kNullRecord – a terminating NULL record, described above.
- kStringRecord – a ‘C’ format variable length string record.
- kSimplexRecord – a variable format/size record whose contents is described by a type-id.
- kComplexRecord – a ‘collection’ element description record (discussed below)
- kOrphanRecord – a record that has been logically deleted/orphaned and no longer has any meaning.
By examining the structure type field of a given record, the memory model abstraction layer is able to determine ‘what’ that record is, and more importantly, what other fields exist within the record itself that also participate in the memory model, and must be handled by the abstraction layer. For example, the ‘kComplexRecord’ structure which is used to represent nodes (valued or otherwise) in a collection contains essentially the following:
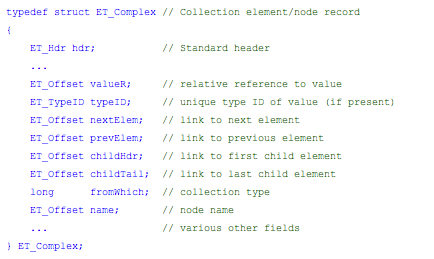
As with the fields of the ET_Hdr structure that starts the ET_Complex structure, the additional ET_Offset fields (i.e., relative references) in the ET_Complex structure contain relative offsets from the start of the referring structure to the referenced structure, both of which always start with the fields of ET_Hdr. The type collections abstraction uses these additional fields to implement arbitrary collections of typed data within the handle that can be automatically organized and navigated in a number of ways based on the value of the ‘fromWhich’ field.
The diagram below illustrates the use of this structure to represent a hierarchical tree, however the ET_Complex structure is sufficiently general that virtually any collection metaphor can be represented by it including (but not limited to) arrays (multi-dimensional), stacks, rings, queues, sets, n-trees, binary trees, linked lists, etc. In the diagram, the ‘moveTo’, ‘moveFrom’ and ‘nextItem’ fields of the header have been omitted for clarity, also any field not shown with an arrowed line contains zero. The ‘valueR’ field would contain a relative reference to the actual value associated with the tree node (if present) which would be contained in a record of type ET_Simplex, the type ID of this record is specified in the ‘typeID’ field of the ET_Complex and, given Mitopia’s infrastructure for converting type IDs to the corresponding type and field arrangement, this can be used to examine the contents of the value (which might of course contain ET_Offset fields of its own).
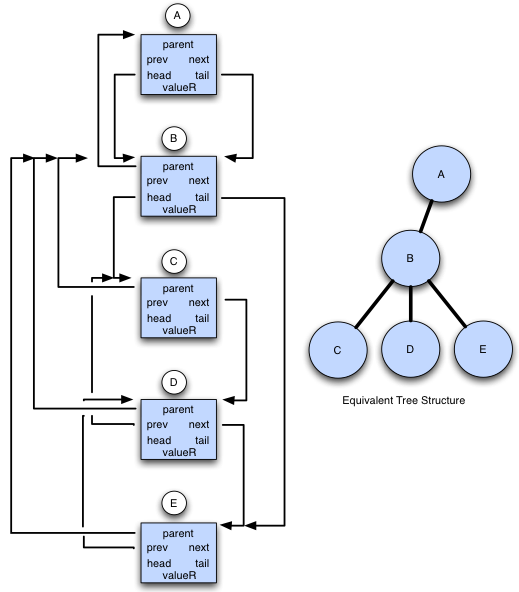
As can be seen from the diagram above, since ‘A’ has only one child (namely ‘B’), both the ‘childHdr’ and ‘childTail’ fields reference ‘B’. This is in contrast to the ‘childHdr’ and ‘childTail’ fields of ‘B’ itself which reflect the fact that ‘B’ has three children. To navigate between children, the doubly-linked ‘nextElem’ and ‘prevElem’ fields are used. Finally the ‘parent’ field from the standard header is used to represent the hierarchy. It is easy to see how by simply manipulating the various fields of the ET_Complex structure, arbitrary collection types can be created as can a large variety of common operations on those types. In the example of the N-tree above, operations might include pruning, grafting, sorting, insertion, rotations, shifts, randomization, promotion, demotion, etc. Because the ET_Complex type is ‘known’ to the Mitopia® abstraction layer, it can transparently handle all the manipulations to the ET_Offset fields in order to ensure referential integrity is maintained during all such operations. This ability is critical to situations where large collections of disparate data must be accessed and distributed (while maintaining ‘flatness’) throughout a system.
In addition to the use of the ET_Complex structure to represent nodes in a collection, Mitopia’s type collections abstraction uses the ET_Simplex structure to hold the actual values of the data. Any node in a collection that has a value will have a relative reference in the ‘valueR’ field leading to the ET_Simplex that holds the value. The type of the value held in the ET_Simplex is given by the ‘typeID’ field in the node, and this allows the type manager abstraction to be used to access the fields of the data record value which is held in the final variable sized ‘value’ field of the ET_Simplex.

Therefore when referring to elements in a collection, Mitopia® uses the node reference which is the relative offset of the ET_Complex record in the handle, generally referred to as an “element designator”. If the element has a value then it can be found by following the ‘valueR’ field of the element designator to the corresponding ET_Simplex record and then offsetting to get to the start of the ‘value’ field. To get to a given field of a data value, the abstraction layer utilizes the ‘typeID’ value to access the definition of the type for the data and from this it determines the additional offset to get to the field data within the value. It also uses the field type ID to determine the field size so that it can fetch the appropriate bytes. This then is the basic operation underlying every relative reference occurring within the collections metaphor. This behavior is of course hidden by the abstraction layer and replaces the common C language Von Neumann style pointer operation of:
fieldValue = (*ptr).fieldName;
The C version is much simpler because the value ‘ptr’ directly points at the address of the data involved, and the type definition was compiled when the program was built, and thus the offset to the field and the field size are known to the compiler and hence it can generate appropriate code to access the field. Other than the additional levels of indirection imposed by the flat memory model, and the fact that all type operations are determined at run-time, not compile time, the basic operational process is identical. Because all this complexity is hidden by the abstraction layer, one might write the equivalent relative reference statement as follows:
fieldValue = (@relref).fieldName;
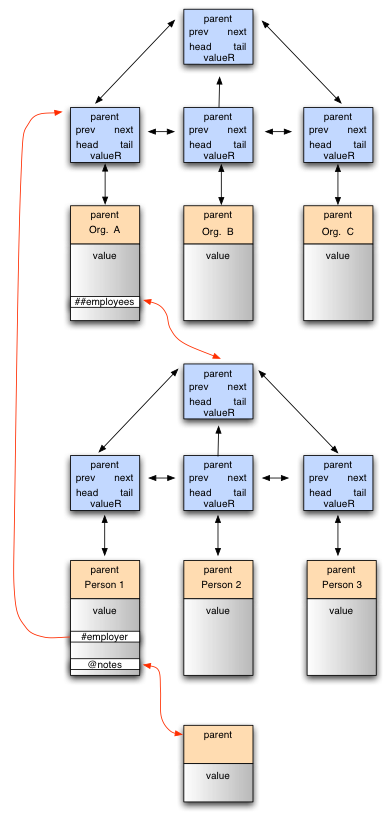
The diagram to the right illustrates the three basic types of references that may occur between the various ET_Simplex and ET_Complex records in a collection. The relative reference ‘@’ occurs directly between two ET_Simplex structures in the collection, so that if the ‘notes’ field were an arbitrary length character string, it would be implemented as a relative reference (char @notes) to another simplex record containing a single variable sized character array. This permits the original “Person” record to have fixed size and an efficient memory footprint, while still being able to contain fields of arbitrary complexity within it by relative reference. For example, another use of such a reference might be to a record containing a picture of the individual. This would be implemented in an identical manner (Picture @picture) but the referenced type would be a Picture type rather than a character array.
The collection reference ‘##’ indicates that a given field refers to a collection (possibly hierarchical) of values of one or more types and is mediated by a relative reference between a collection field of some typed data value within an ET_Simplex structure, and the root node of an embedded collection containing the referenced items (an ET_Complex structure). This embedded collection is in all ways identical to the outer containing collection, but may only be navigated to via the field that references it. It is thus logically isolated from the outermost collection, though still contained within the same contiguous handle. Thus the field declaration “Person ##employees” implies a reference to a collection of Person elements. Obviously collections can be nested within each other to an arbitrary level via this approach, and this gives incredible expressive power while still maintaining the flat memory model. So for example one might reference a ‘car’ which internally might reference all the components that make up the car, which may in turn be built up from collections of smaller components.
The persistent reference ‘#’ is a singular reference from a field of a typed data value held within an ET_Simplex record to an ET_Complex node containing a value of the same or a different type. The referenced node can be in an embedded collection but most commonly is to a node in an outermost collection. In this case the ‘employer’ field of each ‘employee’ of a given organization (Organization #employer) would be a persistent reference to the employing organization as shown in the diagram. The employer/employee link is bi-directional (see later discussions regarding the ‘><‘ symbol), so that when for example, a person record is modified to specify the employer organization, the employees field of that organization is automatically modified to reference the person. The ‘#’ and ‘##’ references are implemented internally using a combination of unique ID and ET_Offset references, and so all the connections within the collection are relative and completely independent of absolute address in memory. The details of handling and resolving collection and persistent references are beyond the scope of the current discussion, but between the two of them, they form the basis for tying typed data held in the collection model into real world data residing elsewhere, including on external servers.
Of course, since the entire contents of an in-memory collection of ontological type data is contiguous and contains no pointer references, it can be written out to disk completely un-modified, and reloaded at a later time, again without modification. This ability is built into the TypeCollections abstraction layer so that client code of the abstraction can no longer distinguish if data is in memory, in a file or held remotely on a server. The TypeCollections abstraction uses this interchangeability extensively (and transparently) to implement various in-memory cacheing strategies in order to overcome the performance limitations inherent in file or storage based data without adding complexity to the client code of the abstraction. This yields the ultimate objective of the entire abstraction, which is that there is no distinction whatsoever between the in-memory programming model and that used to access the data in persistent containers such as files or databases. It is this unification of programming models that yields some of the significant increases in productivity and automation that Mitopia® provides. The price of this abstraction is the complexity of implementing the necessary layers of abstraction within Mitopia®, but this price, though high, is a one-off cost. We will explore the benefits and ramifications of this approach in future posts.