
 It is obvious that for any system connected to the external world, change is the norm, not the exception. In the software realm, this reality, not poor management (which is usually blamed), is the prime reason why projects fail. The outside world does not stand still just to make it convenient for us to monitor it. Moreover, in any system involving multiple analysts with divergent requirements, even the data models and requirements of the system itself will be subject to continuous and pervasive change. By most estimates, up to 80% of the cost and time spent on software may be devoted to maintenance and upgrade of the installed system to handle the inevitability of change. Even our most advanced techniques for software design and implementation fail miserably as one scales the system or introduces rapid change. The reasons for this failure lie in the very nature of the currently accepted software development practice or process. Back the early 90‘s, my analysis of the causes for failure of an earlier system showed that this effect was a significant contribution to the problem. The graphic below illustrates the roots of the problem, which we shall call the “Software Bermuda Triangle” effect.
It is obvious that for any system connected to the external world, change is the norm, not the exception. In the software realm, this reality, not poor management (which is usually blamed), is the prime reason why projects fail. The outside world does not stand still just to make it convenient for us to monitor it. Moreover, in any system involving multiple analysts with divergent requirements, even the data models and requirements of the system itself will be subject to continuous and pervasive change. By most estimates, up to 80% of the cost and time spent on software may be devoted to maintenance and upgrade of the installed system to handle the inevitability of change. Even our most advanced techniques for software design and implementation fail miserably as one scales the system or introduces rapid change. The reasons for this failure lie in the very nature of the currently accepted software development practice or process. Back the early 90‘s, my analysis of the causes for failure of an earlier system showed that this effect was a significant contribution to the problem. The graphic below illustrates the roots of the problem, which we shall call the “Software Bermuda Triangle” effect.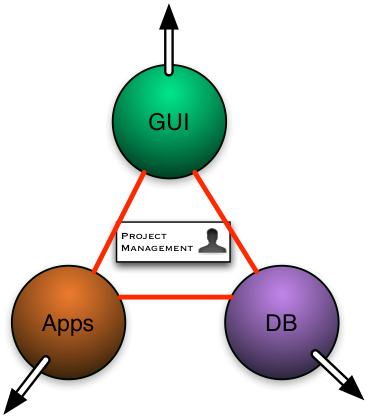
Conventional programming wisdom (and common sense) holds that during the design phase of an information processing application, programming teams should be split into three basic groups.
The first group (labeled “DB” ) is the database group. These individuals are experts in database design, optimization, and administration. This group is tasked with defining the database tables, indexes, structures, and querying interfaces based initially on requirements, and later, on requests primarily from the Applications (“Apps”) group. These individuals are highly trained in database techniques and tend naturally to pull the design in this direction, as illustrated by the outward pointing arrow in the diagram.
The second group is the Graphical User Interface (“GUI”) group. The GUI group is tasked with implementing a user interface to the system that operates according to the customer’s expectations and wishes, and yet complies exactly with the structure of the underlying data (DB group) and the application behavior (Apps. group). The GUI group will have a natural tendency to pull the design in the direction of richer and more elaborate user interfaces.
Finally the Applications group is tasked with implementing the actual functionality required of the system by interfacing with both the DB and the GUI groups and Applications Programming Interfaces (“API”). This group, like the others, tends to pull things in the direction of more elaborate system specific logic.
 Each of these groups tends to have no more than a passing understanding of the issues and needs of the other groups. Thus, during the design phase, and assuming we have strong project and software management that rigidly enforces design procedures, we have a relatively stable triangle where the strong connections enforced between each group by management (represented by the lines joining each group in the diagram), are able to overcome the outward pull of each member of the triangle. Assuming a stable and unchanging set of requirements, such an arrangement stands a good chance of delivering a system to the customer on time. The reality, however, is that correct operation has been achieved by each of the three groups in the original development team embedding significant amounts of undocumented application, GUI, and database-specific knowledge into all three of the major software components. We now have a ticking bomb comprised of these subtle and largely undocumented relationships just waiting to be triggered. After delivery (the bulk of the software life cycle), in the face of the inevitable changes forced on the system by the passage of time, the system breaks down to yield the situation illustrated to the right.
Each of these groups tends to have no more than a passing understanding of the issues and needs of the other groups. Thus, during the design phase, and assuming we have strong project and software management that rigidly enforces design procedures, we have a relatively stable triangle where the strong connections enforced between each group by management (represented by the lines joining each group in the diagram), are able to overcome the outward pull of each member of the triangle. Assuming a stable and unchanging set of requirements, such an arrangement stands a good chance of delivering a system to the customer on time. The reality, however, is that correct operation has been achieved by each of the three groups in the original development team embedding significant amounts of undocumented application, GUI, and database-specific knowledge into all three of the major software components. We now have a ticking bomb comprised of these subtle and largely undocumented relationships just waiting to be triggered. After delivery (the bulk of the software life cycle), in the face of the inevitable changes forced on the system by the passage of time, the system breaks down to yield the situation illustrated to the right.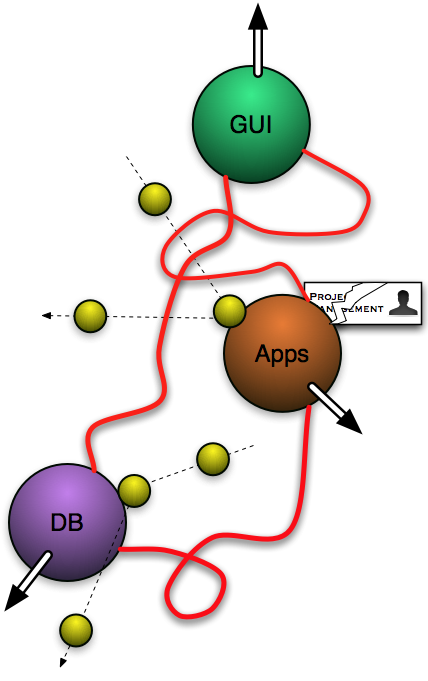 The state now is that the original team has disbanded and knowledge of the hidden dependencies is gone. Furthermore, management is now in a monitoring mode only. During maintenance and upgrade phases, each change hits primarily one or two of the three groups. Time pressures, and the new development environment, mean that the individual tasked with the change (probably not an original team member) tends to be unaware of the constraints, and naturally pulls outward in his particular direction. The binding forces have now become much weaker and more elastic, while the forces pulling outwards remain as strong. All it takes is a steady supply of changes impacting this system for it to break apart and tie itself into knots. Some time later, the system grinds to a halt or becomes unworkable or not modifiable. The customer must either continue to pay progressively more and more outrageous maintenance costs (swamping the original development costs), or must start again from scratch with a new system and repeat the cycle. The latter approach is often much easier than the former. This effect is central to why software systems are so expensive. Since change of all kinds is pervasive in any broadly connected system, an architecture for such systems must find some way to address and eliminate this Software Bermuda Triangle effect.
The state now is that the original team has disbanded and knowledge of the hidden dependencies is gone. Furthermore, management is now in a monitoring mode only. During maintenance and upgrade phases, each change hits primarily one or two of the three groups. Time pressures, and the new development environment, mean that the individual tasked with the change (probably not an original team member) tends to be unaware of the constraints, and naturally pulls outward in his particular direction. The binding forces have now become much weaker and more elastic, while the forces pulling outwards remain as strong. All it takes is a steady supply of changes impacting this system for it to break apart and tie itself into knots. Some time later, the system grinds to a halt or becomes unworkable or not modifiable. The customer must either continue to pay progressively more and more outrageous maintenance costs (swamping the original development costs), or must start again from scratch with a new system and repeat the cycle. The latter approach is often much easier than the former. This effect is central to why software systems are so expensive. Since change of all kinds is pervasive in any broadly connected system, an architecture for such systems must find some way to address and eliminate this Software Bermuda Triangle effect.If we wish to tackle the Bermuda Triangle effect, it was clear from the outset that the first step is to reduce the molecule from three components to one, so that when change impacts the system, it does not force the molecule to warp and eventually break as illustrated in the preceding diagram. Clearly since application specific logic cannot be avoided, is was necessary to find a way whereby both the database (or in Mitopia® parlance, the persistent storage) and the user interface could be automatically generated from the system ontology at run time and not compile time. The strategy was thus to transform the molecule to the form depicted below.
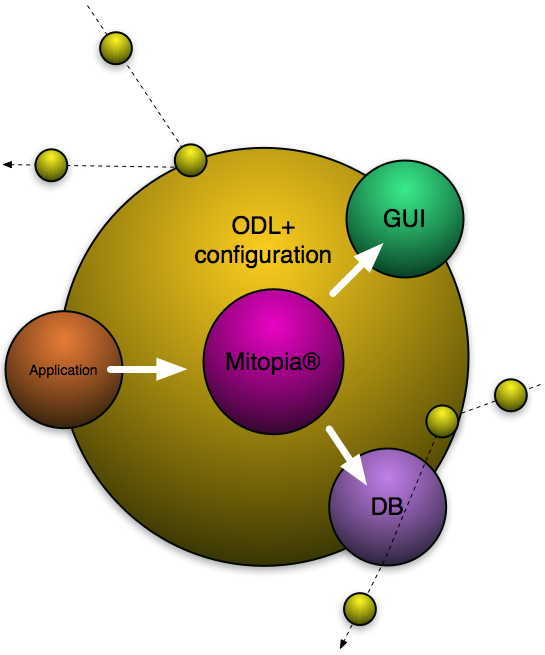 In this approach, the application-specific requirements are specified to the central Mitopia® engine primarily through the ontology itself using the Ontology Definition Language (ODL), and to a lesser extent through a number of other configuration metaphors, not through code. The central Mitopia® engine is capable of automatically generating and handling the GUI as well as the database functionality entirely from the ODL. This means that change can no longer directly impact the code of the GUI and DB since these are entirely driven by Mitopia®, based on the ODL, and thus all change hits the ODL/configuration layer, so once that has been updated, all aspects of the system update automatically in response. The molecule is now rigid and highly adaptive, and as a consequence is almost completely immune to the Bermuda Triangle effect.
In this approach, the application-specific requirements are specified to the central Mitopia® engine primarily through the ontology itself using the Ontology Definition Language (ODL), and to a lesser extent through a number of other configuration metaphors, not through code. The central Mitopia® engine is capable of automatically generating and handling the GUI as well as the database functionality entirely from the ODL. This means that change can no longer directly impact the code of the GUI and DB since these are entirely driven by Mitopia®, based on the ODL, and thus all change hits the ODL/configuration layer, so once that has been updated, all aspects of the system update automatically in response. The molecule is now rigid and highly adaptive, and as a consequence is almost completely immune to the Bermuda Triangle effect.To accomplish this transformation, a run-time discoverable types system (ODL) is essential and this ODL must concern itself not only with basic type definition and access, but also with the specifics of how types are transformed into user interface, as well as how they specify the content and handling of system persistent storage. For this reason Mitopia’s ontology, unlike semantic ontologies, had to be tied to binary data storage, had to have the performance necessary to implement complex user interfaces through run-time discovery, and most demanding of all, had to have the ability to directly implement a high performance scaleable database architecture. All code within both Mitopia®, the GUI, and the persistent storage is forced to access and handle data through the type manager abstraction in order to preserve code independence from the application specifics, and to allow data to be passed and understood across flows. However, because the Mitopia® core code itself implements the key type manager abstraction as well as the database and GUI use of that abstraction, it is able to perform whatever optimization and cacheing steps are necessary to achieve maximum performance without allowing the abstraction to be broken by external non-private code. This is a critical distinction from the object-oriented approach to data abstraction. Another critical benefit is that this approach unifies the programming model for handling data in memory with that used to access it in a database, and that associated with its display. By eliminating all the custom glue code normally associated with these transformations (which is an estimated 60% or more of any large system code base), we have drastically improved system reliability and adaptability, and reduced development time and costs associated with creating new systems.
There is considerable overlap then in the ODL requirements driven by the needs of a data-flow based system (see next post), and those driven by the attempt to eliminate the Bermuda Triangle effect. Requirements driven by the Bermuda Triangle include the need to generate and handle user interfaces, the need to provide some means of specifying application dependent behaviors for the types and fields in the ontology (i.e., ODL based type and field scripts and annotations), and the need to specify the form and topology of the system’s distributed persistent storage (i.e., database). Once again, these requirements are quite different from the focus or intent of a semantic ontology, and resulted in Mitopia’s ontology being quite distinct from the main evolutionary branch of ontological technology today which is semantic/linguistic.