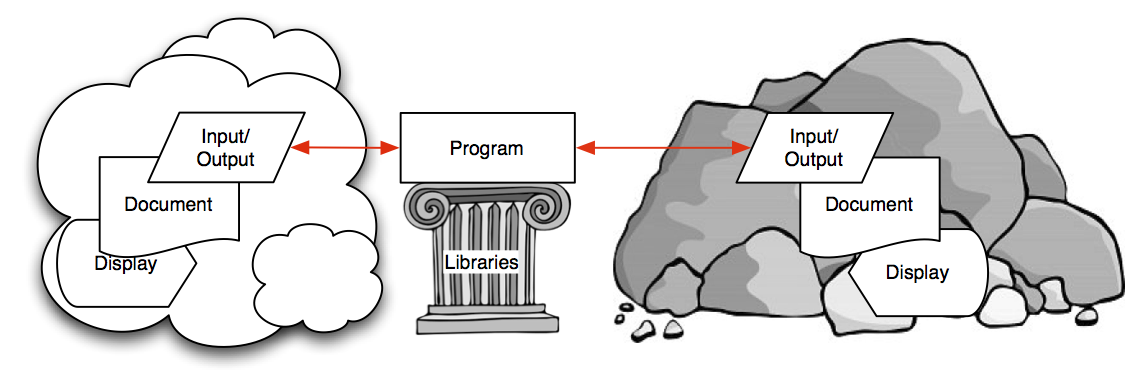
In the
previous post I gave a brief overview of the classical approach to
data integration which ultimately is embodied in the
ETL acronym. This approach unfortunately accepts and builds upon the limitations of the standard target data repositories, namely
relational databases. Because of the limitations such a target repository imposes, today’s data integration technology tends to be weak, ineffective, and non-adaptive. This is why the area is the subject of much research right now, yet none of that research appears to be addressing the
fundamental limitations that the relational repository causes. In this post I want to introduce the MitoMine™ technology which is Mitopia’s next generation ontology based data integration and mining suite.
NOTE:You will find a good demo of the power and use of MitoMine™ in “CyberSecurity.m4v” video on the “
Videos,demos & papers” page.
In contrast to the ETL (Extract Transform Load) approach taken with conventional data integration/mining approaches, Mitopia® adopts a fundamentally different ontology based data integration strategy to integrate and mine external data sources. A key driver to the Mitopia® approach is the need for rapidly adaptable interfaces or ‘scripts’ to allow for the vast diversity of external source formats (including unstructured text), and just as importantly, for the fact that the format of any given source will most likely be subject to continuous change. To combat the erosive effect of these two factors, the approach taken is to use Mitopia’s heteromorphic language technology (see
future posts) to create a nested/entangled parser pair for any given source, where the inner parser utilizes the
Carmot-E language, and the outer parser is rapidly configurable (without re-compilation) as the source format changes. The heteromorphic language suite that implements this capability within Mitopia® is known as MitoMine™.
From the perspective of the MitoMine™ ETL sequence, the location of all ‘source’ data to be extracted is simply a file on the disk. For data sources which must be obtained by other external connections, the job of moving the data to the local disk for processing is handled either manually, or through the use of plugin capabilities that are provided to interact with the original source in order to give the appearance of a local disk file. Similarly, the functionality equivalent to the conventional ‘Load’ phase of an ETL tool is already built into Mitopia’s Carmot ontology and the MitoPlex™/MitoQuest™ federation that handles persistent storage, so that all the ingestion process must do is create its output within a Mitopia® ‘collection’. For this reason, the focus within MitoMine™ is almost exclusively on the ‘Transform’ step in the classical ETL process. MitoMine™ is used pervasively within Mitopia® for a variety of purposes, but within the context of ingesting new source data, its use generally falls into one of the following two scenarios:
- A user obtains new source data to be integrated into the system by some external means, copies it to their local disk, creates (or selects) a mining script, and mines the data using MitoMine™ specifying the appropriate ‘script’. The resultant collection may be written directly to persistent storage through MitoPlex™, it may be saved to local disk for subsequent re-load and persisting, or it may be discarded.
- For sources that involve ‘real time’ or continuous feeds/updates, a dedicated server process may be created and the relevant mining script create/specified. The server can be configured to scan its ‘input’ folder on a regular basis, and if new input arrives, to mine it using the appropriate ‘script’ and persist it automatically. Servers also support regularly resolving ‘aliases’ to other locations on the network, and if source input is found there, copying it to the ‘input’ folder for subsequent automatic ingestion. Custom code can be registered to interact with complex external sources in order to obtain and mine source updates.
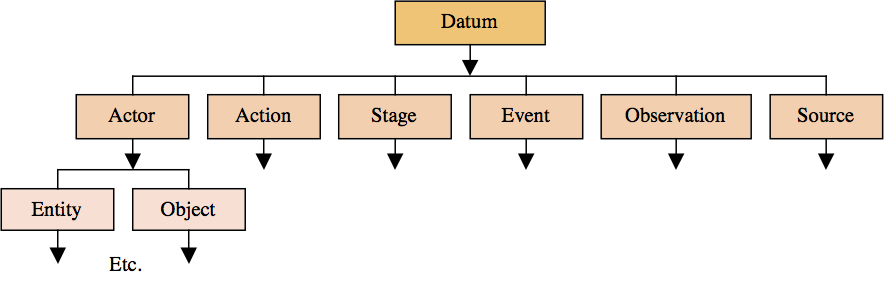
A major difference between MitoMine™ and conventional ETL tools is that the output of a MitoMine™ run goes directly into the system knowledge-level ontology, not into a set of information-level ‘database tables’. This means that the writer of a MitoMine™ script cannot simply look at the source data content, create a closely matching set of tables in the database, and then write a trivial script to transform the source into the output table space. Instead the script writer must engage in what is essentially a philosophical process of asking “what is the source data describing?” in ontological terms (i.e., in terms of relationships between entities, places, things etc.). Once the source is understood in these terms, it becomes possible in MitoMine™ to write a script to transform the source taxonomy into the system ontology and to merge it correctly with existing persistent storage content. It is for this reason that a full understanding of the system ontology and the philosophy behind it is a prerequisite for creating successful mining scripts. In the Mitopia® context, the worst thing you can do is to define types without regard to their place within the existing ontology but instead based on a given source content. The result of doing so is generally to render the system inflexible, to reduce reliability and capability, and in the end to re-create the data stovepipes that are the bane of existing information-level system integration approaches.
From a functional perspective, MitoMine™ is vastly more powerful and expressive than any ETL technology out there, bar none. This power comes through the unique and patented capabilities provided by the heteromorphic language approach when combined with a knowledge-level contiguous ontology based data substrate to yield an ontology based data integration framework. Unlike classical ETL tools, MitoMine™ does not attempt to provide graphical tools for defining the ‘transformation’ process. As we shall see later, the full complexity of the transformations required for realistic sources mean that the idea that a GUI could express the subtleties involved is simplistic in the extreme. The fact that existing tools take this GUI approach is nothing more than a confirmation that their domain of applicability is severely restricted and does not include realistic external sources, particularly the kinds of encyclopedic sources necessary to ‘teach’ a system about a new subject area of interest.
The reason for this is that such high value and reliable sources are created and distributed by publishers who invest huge amounts of time and money into creating and maintaing the source and ensuring its reputation for reliability remains unblemished. Because of this investment, there is little incentive for publishers to make this data easily available on the web since there is no economic model there for them recoup costs, so instead the data is available either through paid subscription services (e.g., Lexis-Nexis), or can be purchased in publication form (e.g., Thompson Corp).
The publishers of this valuable information have an active interest in ensuring that the information cannot easily be extracted in bulk form by conventional mining technologies since if this were to occur it would represent the loss of the publishers ‘intellectual property’. For this reason there has long been an on-going ‘arms war’ between the publishers of encyclopedic or reference information, and those who seek to mine or extract it for use in other systems. Because the peak of current data mining technology is frequently either support for ‘regular expressions’ (basically a form of lexical analyzer equivalent to the ET_CatRange part of Mitopia’s lexical abstraction), or at most conventional parsing techniques, this is an arms war that the publishers, and/or those who wish to prevent automated analysis of text, continue to win easily. This is because current parsing techniques are limited to relative simple languages that are not context sensitive (e.g., programming languages).
By contrast the human reader is able to understand meaning through a wide range of contextual mechanisms including document structure, page layout, fonts, cross references and indexes, external hyperlinks and references, images, metaphors, humor, deliberate ambiguity and conflict and errors, and a wide variety of other linguistic techniques, all of which may be used in combination by an information publisher in any given source. The casual human reader may well be unaware that these techniques have been deliberately introduced in order to protect against machine interpretation of content. As a result, virtually all high value information sources contain many if not most of these techniques and can thus defeat any conventional attempt to mine, extract, and especially to integrate source content. The only exceptions to this status quo are governments and large organizations that have largely unfiltered access to their own data collection and delivery mechanisms, or have the considerable resources necessary to pay for un-protected source data.
The MitoMine™ technology is capable of overcoming virtually all of these obfuscation techniques with relative ease which means it can be applied to a huge variety of sources with differing formats (up to and including binary data) and varying levels of consistency and accuracy. The main key to this ability is the powerful heteromorphic language suite that is used to flexibly adapt to source structure and anomalies and to convert the source content, including contextual clues, into ‘meaning’ as expressed through data and connections described by the Carmot ontology.
Mitopia’s patented heteromorphic language technology (on which MitoMine™ is built) defines the following:
A Homomorphic Language is one having a single fixed language grammar such that the order of execution of statements in that grammar is determined solely by the arrangement and order of statements for any given program written in that grammar.
A Heteromorphic Language exists within two or more nested parsers where the outer parser language (the Ectomorphic Language) matches and parses the syntax of a specific external ‘source’ so that at points designated by the ectomorphic language specification, the outer parser grammar invokes one or more inner parsers conforming to the syntax of an Endomorphic Language(s), passing it program statements written in the endomorphic language(s), such that the order of execution of statements in the endomorphic language(s) is determined predominantly by the ‘flow’ of the outer parser (as determined by the external ‘source’ content and the ectomorphic language specification). Endomorphic language statements may obtain that portion of the ‘source’ text just ‘accepted’ by the ectomorphic parser as a parameter. The endomorphic language(s) is tied to a specific functional environment and/or purpose (in order to do something useful) through custom code registered with, and wrapping, the parsers. It is this combination that creates a heteromorphic language ‘suite’. Either the ectomorphic or the endomorphic language may take multiple distinct forms depending on the required functionality. These pairings of many variants of one language with a single form of the other(s) form a ‘suite’. All such pairings are deemed instances or variants of a given heteromorphic language suite.
So homomorphic languages basically include all existing programming languages regardless of ‘paradigm’. By contrast, heteromorphic languages embed the endomorphic language statements directly within the ectomorphic grammar so that they execute in an order determined by the outer parser evolution. In the data integration context, one can think of a heteromorphic language as having a rapidly adaptable and malleable outer ‘layer’ (the ectomorphic language program – referred to as a ‘script’ in MitoMine™ context) that can be matched to virtually any unique source format, combined with an inner ‘layer’ which is tied intimately to the current system ontology (the endomorphic language – Carmot-E in the case of MitoMine™). This pairing/nesting of two languages, each of which is impedance matched to the data on one side of the ‘transform’ step of the ETL process, is able to almost trivially overcome complex language and context issues in mining source data in a way that is not possible for conventional tools which utilize homomorphic languages as their underpinnings. I described this problem with conventional programming languages, and introduced the heteromorphic language technique as the solution in one of my earliest posts on this site.
The power of the heteromorphic technique used within MitoMine™ comes from the fact that because the outer parser ‘state’ is driving the execution of statements in the inner parser, there is little need for the ‘program’ involved in making the mapping between the two dissimilar formats on either side to maintain any concept of the current state of what it is doing. The program is told what to do by the ‘source’ content and all the ‘state’ information is implicitly stored in the outer parser state, so that a statement in the endomorphic language will only execute when it is appropriate for it to execute given the source content. Contextual information in the case of MitoMine™ is stored in the extracted records collection. The endomorphic program statements become ‘stateless’, their state is determined by the parser production in the ectomorphic language where they reside.
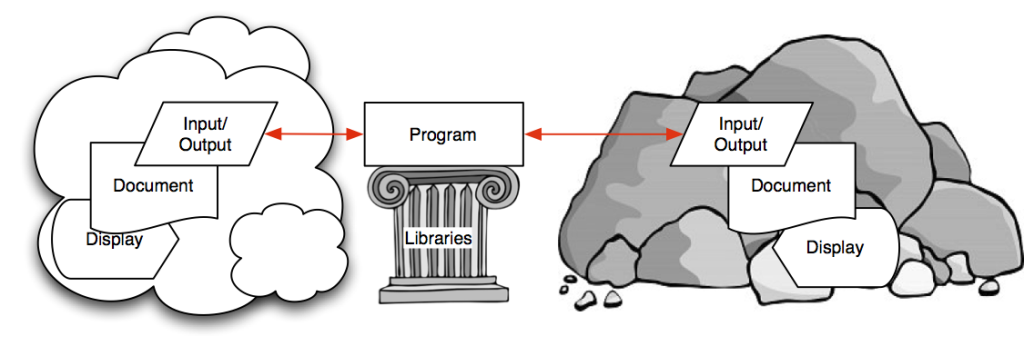
Any programmer that has tried to bridge a gap between two ‘formats’ knows that most of the programming work involved is simply keeping track of where one is within the source, and what has gone before, in order to know what the ‘state’ is and what should be done next. With the heteromorphic language technique virtually all of the housekeeping work (and the associated conditional logic it implies) fades away (into the outer parser state) leaving a simple set of statements that execute only when the source content dictates that they should. This simplification that this yields for the programmer is difficult to over-stress. The price that must be paid for this simplification is the need to understand compiler theory, and a willingness to abandon a fundamental tenet of computer programming that is ‘a program has control of its own program flow’.
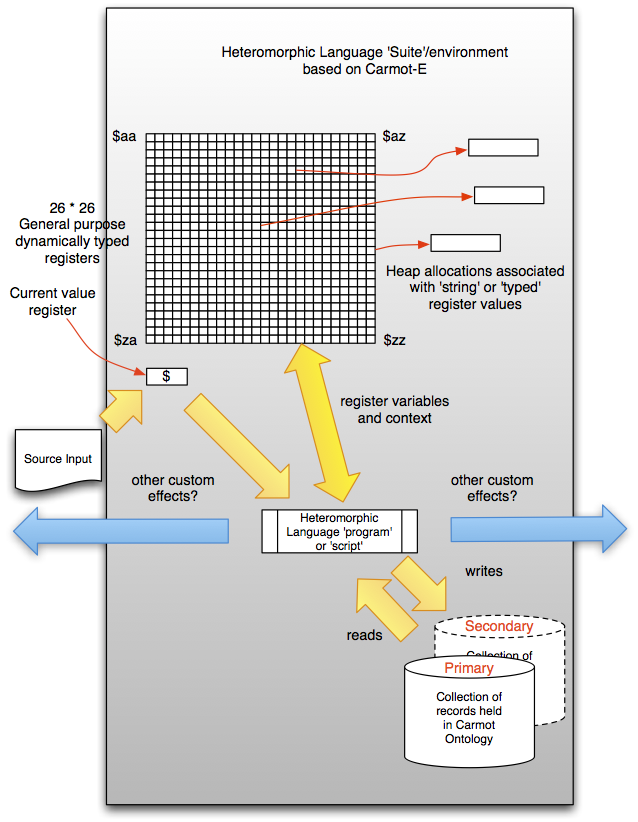 |
| The Carmot-E environment |
In a MitoMine™ script, the source format and content drives the program flow in the script, not the order of the statements/productions in the script. This unique approach to program flow can be confusing initially, but once once becomes used to it the simplifying power it brings is amazing. The endomorphic language Carmot-E that is used by MitoMine™ is fully described elsewhere, along with details of the Carmot-E programming environment model so it will not be detailed herein. It is however illustrated in the diagram to the right.
In the MitoMine™ language suite, the ‘primary’ collection supported by Carmot-E is referred to as the ‘temporary’ collection while the optional Carmot-E ‘secondary’ collection is referred to as the ‘output’ collection, and contains all mined data records from the current MitoMine™ run. Other than this nomenclature change and the differences implied by the custom ‘plugin’ and ‘resolver’ functions registered by MitoMine™ with the parser abstraction, the Carmot-E programming ‘model’ is unchanged within MitoMine™. Essentially MitoMine™ adds a large library of functions and procedures to Carmot-E that can be used within the embedded endomorphic language statements and the necessary wrapping to handle the required source ‘scripts’ and examination and persisting of the output collection.
We will explore this process in more detail in
future posts.
 In the previous post I gave a brief overview of the classical approach to data integration which ultimately is embodied in the ETL acronym. This approach unfortunately accepts and builds upon the limitations of the standard target data repositories, namely relational databases. Because of the limitations such a target repository imposes, today’s data integration technology tends to be weak, ineffective, and non-adaptive. This is why the area is the subject of much research right now, yet none of that research appears to be addressing the fundamental limitations that the relational repository causes. In this post I want to introduce the MitoMine™ technology which is Mitopia’s next generation ontology based data integration and mining suite.
In the previous post I gave a brief overview of the classical approach to data integration which ultimately is embodied in the ETL acronym. This approach unfortunately accepts and builds upon the limitations of the standard target data repositories, namely relational databases. Because of the limitations such a target repository imposes, today’s data integration technology tends to be weak, ineffective, and non-adaptive. This is why the area is the subject of much research right now, yet none of that research appears to be addressing the fundamental limitations that the relational repository causes. In this post I want to introduce the MitoMine™ technology which is Mitopia’s next generation ontology based data integration and mining suite.