As discussed in earlier posts, once having settled on an ontological approach to organizing information within Mitopia® (around 1993), the next question that had to be addressed, given that Mitopia® is an architecture, and not focussed on any particular application, was “what kind of upper level of organization is appropriate for laying the foundations of an Ontology of Everything (OOE)”?. The corollary question “What fundamental process do we use to extract meaning from data organized in this manner”? must also be asked. Before describing the approach taken in Mitopia®, it is first perhaps instructive to review the history and current state of the upper level ontology in the semantic realm for comparative purposes, even though as stated previously (see here and here) Mitopia’s ontology evolved in complete ignorance of other work in the ontology field. The following discussion is taken from the Wikipedia article on the subject of upper level ontology (see here).
Upper ontologies are commercially valuable, creating competition to define them. Peter Murray-Rust has claimed that this leads to “semantic and ontological warfare due to competing standards”, and accordingly any standard foundation ontology is likely to be contested among commercial or political parties, each with their own idea of ‘what exists’.
No one upper ontology has yet gained widespread acceptance as a de facto standard. Different organizations are attempting to define standards for specific domains. The ‘Process Specification Language’ (PSL) created by the National Institute for Standards and Technology (NIST) is one example.
There is debate over whether the concept of using a single, shared upper ontology is even feasible or practical at all. There is further debate over whether the debates are valid – often leading to outright censorship and boosterism of particular approaches in supposedly neutral sources including this one. Some of these arguments are outlined below, with no attempt to be comprehensive. Please do not censor them because you promote some ontology.
Why an upper ontology is not feasible
Historically, many attempts in many societies have been made to impose or define a single set of concepts as more primal, basic, foundational, authoritative, true or rational than others. In the kind of modern societies that have computers at all, the existence of academic and political freedoms imply that many ontologies will simultaneously exist and compete for adherents. While the differences between them may be narrow and appear petty to those not deeply involved in the process, so too did many of the theological debates of medieval Europe, but they still led to schisms or wars, or were used as excuses for same. The tyranny of small differences that standard ontologies seek to end may continue simply because other forms of tyranny are even less desirable. So private efforts to create competitive ontologies that achieve adherents by virtue of better communication may proceed, but tend not to result in long standing monopolies.
A deeper objection derives from ontological constraints that philosophers have found historically inescapable. Some argue that a transcendental perspective or omniscience is implied by even searching for any general purpose ontology since it is a social / cultural artifact, there is no purely objective perspective from which to observe the whole terrain of concepts and derive any one standard.
A narrower and much more widely held objection is implicature: the more general the concept and the more useful in semantic interoperability, the less likely it is to be reducible to symbolic concepts or logic and the more likely it is to be simply accepted by the complex beings and cultures relying on it. In the same sense that a fish doesn’t perceive water, we don’t see how complex and involved is the process of understanding basic concepts.
- There is no self-evident way of dividing the world up into concepts, and certainly no non-controversial one
- There is no neutral ground that can serve as a means of translating between specialized (or “lower” or “application-specific”) ontologies
- Human language itself is already an arbitrary approximation of just one among many possible conceptual maps. To draw any necessary correlation between English words and any number of intellectual concepts we might like to represent in our ontologies is just asking for trouble. (WordNet, for instance, is successful and useful precisely because it does not pretend to be a general-purpose upper ontology; rather, it is a tool for semantic / syntactic / linguistic disambiguation, which is richly embedded in the particulars and peculiarities of the English language.)
- Any hierarchical or topological representation of concepts must begin from some ontological, epistemological, linguistic, cultural, and ultimately pragmatic perspective. Such pragmatism does not allow for the exclusion of politics between persons or groups, indeed it requires they be considered as perhaps more basic primitives than any that are represented.
- Those who doubt the feasibility of general purpose ontologies are more inclined to ask “what specific purpose do we have in mind for this conceptual map of entities and what practical difference will this ontology make?” This pragmatic philosophical position surrenders all hope of devising the encoded ontology version of “everything that is the case,” Wittgenstein, Tractatus Logico-Philosophicus).
According to Barry Smith in The Blackwell Guide to the Philosophy of Computing and Information (2004), “the project of building one single ontology, even one single top-level ontology, which would be at the same time non-trivial and also readily adopted by a broad population of different information systems communities, has largely been abandoned.” (p. 159)
Finally there are objections similar to those against artificial intelligence; Technically, the complex concept acquisition and the social / linguistic interactions of human beings suggests any axiomatic foundation of “most basic” concepts must be cognitive, biological or otherwise difficult to characterize since we don’t have axioms for such systems. Ethically, any general-purpose ontology could quickly become an actual tyranny by recruiting adherents into a political program designed to propagate it and its funding means, and possibly defend it by violence. Historically, inconsistent and irrational belief systems have proven capable of commanding obedience to the detriment of harm of persons both inside and outside a society that accepts them. How much more harmful would a consistent rational one be, were it to contain even one or two basic assumptions incompatible with human life?
Why an upper ontology is feasible
Most of the objections to upper ontology refer to the problems of life-critical decisions or non-axiomatized and difficult to understand problem areas such as law or medicine or politics. Some of these objections do not apply to infrastructure or standard abstractions that are defined into existence by human beings and closely controlled by them for mutual good, such as electrical power system connections or the signals used in traffic lights. No single general metaphysics is required to agree that some such standards are desirable. For instance, while time and space can be represented many ways, some of these are already used in interoperable artifacts like maps or schedules.
Most proponents of an upper ontology argue that several good ones may be created with perhaps different emphasis. Very few are actually arguing to discover just one within natural language or even an academic field. Most are simply standardizing some existing communication.
Several common arguments against upper ontology can be examined more clearly by separating issues of concept definition (ontology), language (lexicons), and facts (knowledge). For instance, people have different terms and phrases for the same concept. However, that does not necessarily mean that those people are referring to different concepts. They may simply be using different language or idiom. Formal ontologies typically use linguistic labels to refer to concepts, but the terms mean no more and no less than what their axioms say they mean. Labels are similar to variable names in software, evocative rather than definitive.
A second argument is that people believe different things, and therefore can’t have the same ontology. However, people can assign different truth values to a particular assertion while accepting the validity of certain underlying claims, facts, or way of expressing an argument with which they disagree. Using, for instance, the issue/position/argument form.
Even arguments about the existence of a thing require a certain sharing of a concept, even though its existence in the real world may be disputed. Separating belief from naming and definition also helps to clarify this issue, and show how concepts can be held in common, even in the face of differing belief. For instance, wiki as a medium may permit such confusion but disciplined users can apply dispute resolution methods to sort out their conflicts, e.g. Wikipedia ArbCom.
Advocates argue that most disagreement about the viability of an upper ontology can be traced to the conflation of ontology, language and knowledge, or too-specialized areas of knowledge: many people, or agents or groups will have areas of their respective internal ontologies that do not overlap. If they can cooperate and share a conceptual map at all, this may be so very useful that it outweighs any disadvantages that accrue from sharing. To the degree it becomes harder to share concepts the deeper one probes, the more valuable such sharing tends to get. If the problem is as basic as opponents of upper ontologies claim, then, it applies also to a group of humans trying to cooperate, who might need machine assistance to communicate easily.
If nothing else, such ontologies are implied by machine translation, used when people cannot practically communicate. Whether “upper” or not, these seem likely to proliferate.
 From the discussion above it should be obvious that in the world of semantic ontologies, based as they are on human language, the prospects of ever agreeing on an upper level ontology in order to enable any truly global exchange of ideas has almost been abandoned. This fact notwithstanding, there are essentially just two leading upper level ontologies existing in the semantic web, the first being the Cyc Upper Ontology, and the second being the Suggested Upper Merged Ontology (SUMO). Remember that these are semantic ontologies, that is ontologies for organizing words and linguistic meaning, not for organizing or representing data. Thus we see that immediately below the root of either upper level ontology, things immediately begin to split into some very esoteric sounding groups, many of which it would require a dictionary to even begin to understand. These groupings are driven by philosophical considerations of a very obscure nature, and thus it would be very hard for the average (or even far above average) person to place a given data record type anywhere within such an ontology. Try it yourself by looking at the upper ontology diagrams given below and then trying to place the following into one of the boxes shown:
From the discussion above it should be obvious that in the world of semantic ontologies, based as they are on human language, the prospects of ever agreeing on an upper level ontology in order to enable any truly global exchange of ideas has almost been abandoned. This fact notwithstanding, there are essentially just two leading upper level ontologies existing in the semantic web, the first being the Cyc Upper Ontology, and the second being the Suggested Upper Merged Ontology (SUMO). Remember that these are semantic ontologies, that is ontologies for organizing words and linguistic meaning, not for organizing or representing data. Thus we see that immediately below the root of either upper level ontology, things immediately begin to split into some very esoteric sounding groups, many of which it would require a dictionary to even begin to understand. These groupings are driven by philosophical considerations of a very obscure nature, and thus it would be very hard for the average (or even far above average) person to place a given data record type anywhere within such an ontology. Try it yourself by looking at the upper ontology diagrams given below and then trying to place the following into one of the boxes shown:
- A dog
- A contract between two organizations
- A news story or document
- A country
Difficult isn’t it? But these are exactly the kinds of things one might track in any system designed to understand real world events. This is one of the fundamental problems with
disjoint model ontologies. Since they divorce themselves from any consideration of actually representing, storing or manipulating data, they tend to evolve on courses charted by philosophical, rather than practical, considerations, with the result that they become useless to anyone other than those few geeks that are really into ontologies, or those companies that seek to promote them. This explains the poor adoption rates for semantic ontology-based systems, despite having been in development for more than twenty years.
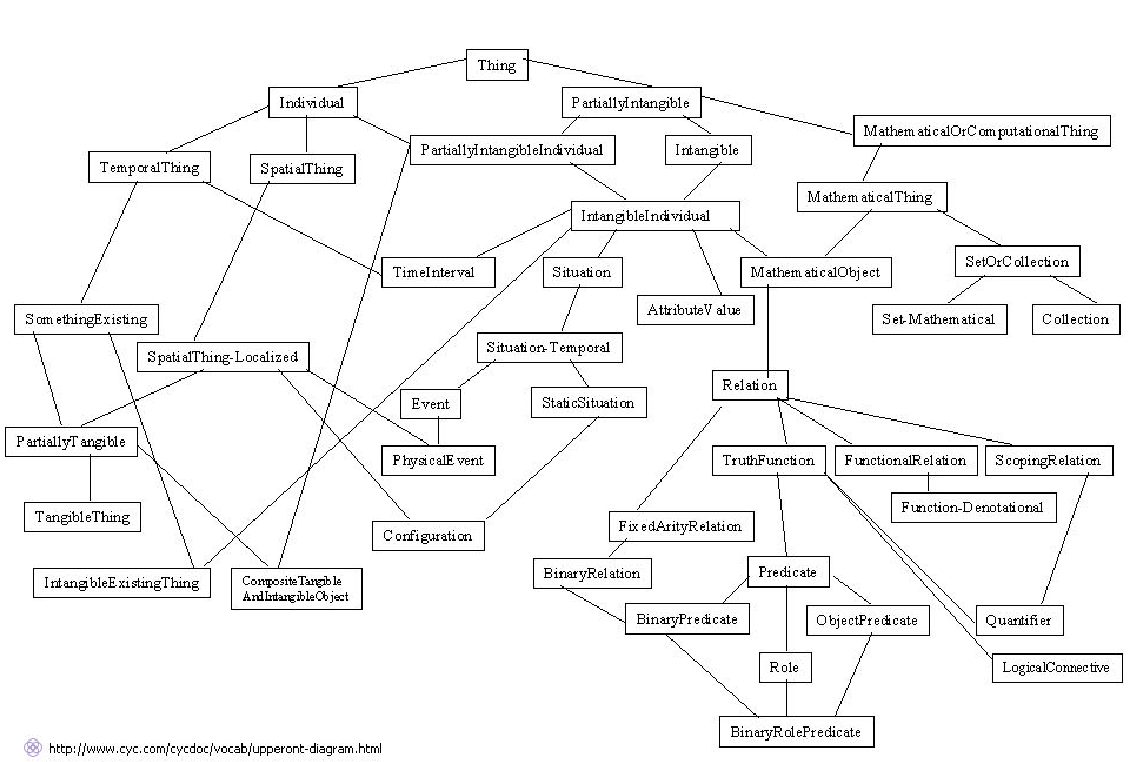
The Cyc Upper Level Ontology
 |
| The Cyc Upper Ontology |
The figure above shows the top level of the Cyc upper ontology. Cyc is an artificial intelligence project that attempts to assemble a comprehensive ontology and database of everyday common sense knowledge, with the goal of enabling AI applications to perform human-like reasoning.
The project was started in 1984 by Doug Lenat as part of Microelectronics and Computer Technology Corporation. The name “Cyc” (from “encyclopedia”, pronounced like psych) is a registered trademark owned by Cycorp, Inc. in Austin, Texas, a company run by Lenat and devoted to the development of Cyc. The original knowledge base is proprietary, but a smaller version of the knowledge base, intended to establish a common vocabulary for automatic reasoning, was released as OpenCyc under an open source license. More recently, Cyc has been made available to AI researchers under a research-purposes license as ResearchCyc.
Typical pieces of knowledge represented in the database are “Every tree is a plant” and “Plants die eventually”. When asked whether trees die, the inference engine can draw the obvious conclusion and answer the question correctly. The Knowledge Base (KB) contains over a million human-defined assertions, rules or common sense ideas. These are formulated in the language CycL, which is based on predicate calculus and has a syntax similar to that of the Lisp programming language.
Much of the current work on the Cyc project continues to be knowledge engineering, representing facts about the world by hand, and implementing efficient inference mechanisms on that knowledge.
Increasingly, however, work at Cycorp involves giving the Cyc system the ability to communicate with end users in natural language, and to assist with the knowledge formation process via machine learning.
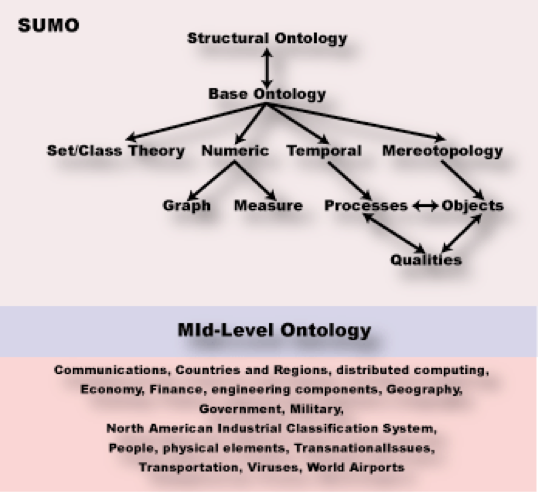
The Suggested Upper Merged Ontology (SUMO)
 |
| The Suggested Upper Merged Ontology (SUMO) |
The Suggested Upper Merged Ontology or SUMO is an upper level ontology intended as a foundation ontology for a variety of computer information processing systems. It was originally developed by the Teknowledge Corporation and now is maintained by Articulate Software. It is one candidate for the “standard upper ontology” that IEEE working group 1600.1 is working on. It can be downloaded and used freely.
 SUMO originally concerned itself with meta-level concepts (general entities that do not belong to a specific problem domain), and thereby would lead naturally to a categorization scheme for encyclopedias. It has now been considerably expanded to include a mid-level ontology and dozens of domain ontologies.
SUMO originally concerned itself with meta-level concepts (general entities that do not belong to a specific problem domain), and thereby would lead naturally to a categorization scheme for encyclopedias. It has now been considerably expanded to include a mid-level ontology and dozens of domain ontologies.
SUMO was first released in December 2000. It defines a hierarchy of SUMO classes and related rules and relationships. These are formulated in a version of the language SUO-KIF which has a LISP-like syntax. A mapping from WordNet synsets to SUMO has also been defined.
SUMO is organized for interoperability of automated reasoning engines. To maximize compatibility, schema designers can try to assure that their naming conventions use the same meanings as SUMO for identical words, (eg: agent, process). SUMO has an associated open source Sigma knowledge engineering environment.
As can be seen from Figure 6, SUMO is really more of a grab bag of individual ontologies that loosely fit into parts of an upper framework. It is ontology by accretion, not design, and lacks much of the consistency of the Cyc Upper Ontology because of the open source style in which it has evolved.
SUMO and its domain ontologies form the largest formal public ontology in existence today. They are being used for research and applications in search, linguistics and reasoning. SUMO is the only formal ontology that has been mapped to all of the WordNet lexicon. The ontologies that extend SUMO are available under GNU General Public License.
The ontology comprises 20,000 terms and 70,000 axioms when all domain ontologies are combined. These consist of SUMO itself, the MId-Level Ontology (MILO), and ontologies of Communications, Countries and Regions, distributed computing, Economy, Finance, engineering components, Geography, Government, Military (general, devices, processes, people), North American Industrial Classification System, People, physical elements, Transnational Issues, Transportation, Viruses, World Airports A-K, World Airports L-Z, WMD, and terrorism.
Summary
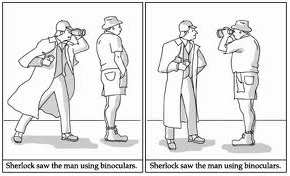 |
| Ambiguity in the English language |
It is clear that there is a serious problem with current approaches to applying ontologies to computing, and that problem is the decision to adopt existing philosophical approaches and to apply them to linguistic understanding of text within documents stored digitally. The problem is that the use of natural language prevents any concrete connection to representing reality in a computable manner, since natural language is so imprecise and changeable. In any case there are literally hundreds of natural languages, all different. Most things that happen on Earth happen somewhere where the language is other than English, so if linguistic analysis of English is our fundamental underpinnings, by definition we will be unable to keep up with unfolding events in real time. The problem is perhaps best explained by this quote from John F. Sowa (see here):
People have a natural desire to organize, classify, label, and define the things, events, and patterns of their daily lives. But their best-laid plans are overwhelmed by the inevitable change, growth, innovation, progress, evolution, diversity, and entropy. These rapid changes, which create difficulties for people, are far more disruptive for the fragile databases and knowledge bases in computer systems. The term knowledge soup better characterizes the fluid, dynamically changing nature of the information that people learn, reason about, act upon, and communicate … The most important requirement for any intelligent system is flexibility in accommodating and making sense of the knowledge soup. – John F. Sowa
Using natural language to represent concrete facts and instances and then compute the implications thereof appears to be largely an exercise in futility. Natural language is too imprecise, is country-specific, context-specific, and changes over time (particularly English). Use of philosophical ontologies without first considering their suitability simply aggravates the problem (see here).
- Separating the ontology from the physical representation and manipulation of the data within the system. If the code that manipulates data both in memory and to/from the database is different from that which operates ontologically, as it is with all existing semantic ontology approaches, then the pervasive change in the knowledge soup will render code assumptions invalid within a short period of time. There is no formalism to keep up with this change that can bridge the gap using natural language as its underpinnings. Such systems are thus non-adaptive and doomed to obsolescence.
- Failure to address the corollary question “What fundamental process do we use to extract meaning from data organized in this manner”? Semantic ontologies are targeted at understanding the meaning of human communication, not at representing specific complex knowledge of the world around us for the purpose of computation.
We will discuss these issues in greater depth in the next two posts (
here and
here).

