

Allen Holub’s excellent book on C programming standards
Much has been written on the subject of coding standards and conventions over the years, and they are often the subject of vigorous debate. In this post I want to give a brief overview of the MitoSystems (C language) coding standards and the philosophy behind them. First let us be clear: the purpose of coding standards is to improve the readability, reliability, and maintainability of the code base.
In any large project such as Mitopia® wherein multiple people other than the original author must be able to rapidly understand and trace through code during a debugging session, the most important thing one can do to facilitate this is to maximize the degree to which all the code looks basically the same, and uses the same commenting, indenting, file organization, spacing, and underlying libraries and techniques. In a large code base uniformity is critical to efficiency, reliability, and comprehension. Uppermost of all these is comprehension by both the author or more likely other code maintainers. It is during maintenance that most ‘entropy’ and bugs are introduced into code through poor comprehension of the side effects of what appears locally to be a safe change.
For this reason, arguments commonly put forward that coding standards inhibit creativity and need not be followed by star programmers (these arguments are most often put forward by these individuals themselves), are merely showing a lack of professionalism on the part of the proponent, and a failure to see things in the larger ‘picture’. I have posted before on the relative irrelevance of the programming language in solving these goals, as I have on the relative irrelevance of the language metaphor, and the dangers of ‘COTS cobbling’ in this regard. There are no magic solutions to maintainability and robustness, in the end it it all up to the programmers and the degree of design and coding rigor they apply – from the bottom up, no shortcuts.
The truth is that for large long lived projects, maintainability (and thus project longevity – through resistance to entropy) is driven primarily by four things: (1) Good requirements and initial design, (2) Development of well designed and layered generalized abstraction libraries organized as packages, (3) Good coding standards, rigorously enforced, (4) Pervasive (and maintained) module tests for all packages (5) Other adaptivity techniques (see other posts on this site e.g., here).
We have discussed (1) and (5) in previous posts and have illustrated (2) throughout this blog, so in this post I want to look at the important subject of coding standards (3) in more depth. We will look at Mitopia’s module test approach (4) in a future post.
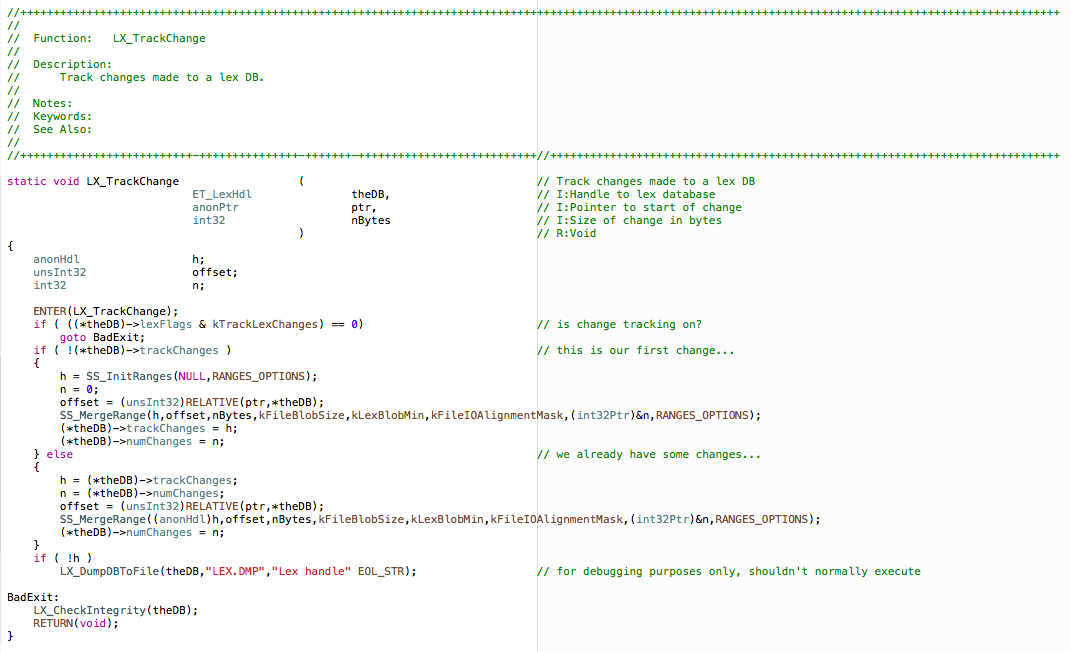
The Basics
We will use the simple function above to illustrate a number of MitoSystems’s basic coding standards:
- Every practical compiler warning should be turned on and treated as an error requiring correction before the code can execute. This practice alone, forces the code to be more explicit and maintainable and avoids time wasting in debugging. Static code analysis should be run regularly.
- Code relating to the same abstraction all goes into the same source file forming a module or package, and every function (internal or external) starts with the identical 2 or 3 letter prefix (in this case LX_ for the package Lex – Lexical analysis). This convention rapidly clues the reader into what kind of thing a particular call might be doing (for example SS_ is the prefix for the searching & sorting package). All internal package functions (i.e., those not exposed outside the package – the bulk usually) are declared ‘static’ and where possible appear before they are used so that no separate function prototype needs to be declared (and maintained). The average number of source lines in all files (code and header) for Mitopia is around 3,000 some complex packages can be up to 15-20 thousand lines. Encapsulation (and hiding) into logical packages is the goal, regardless of the resulting file size.
- Every function is preceded by a standard function header comment giving the function name, description, notes, keywords (optional), and related functions (see also). Before the function is even written, this function header and the description of what it does and how should first be completed. Having to explain something in English goes a long way to clarifying exactly what it is supposed to be for. Simple private functions may scrimp on this description. This description should be updated whenever changes to the code require it. For the investment of a few minutes prior to writing the code, one saves the author and those that follow hours of wasted time. The function header comment contains key alignment marks (the ‘-‘ chars as opposed to the ‘+’ chars) to facilitate the creation of aligned prototypes and comments.
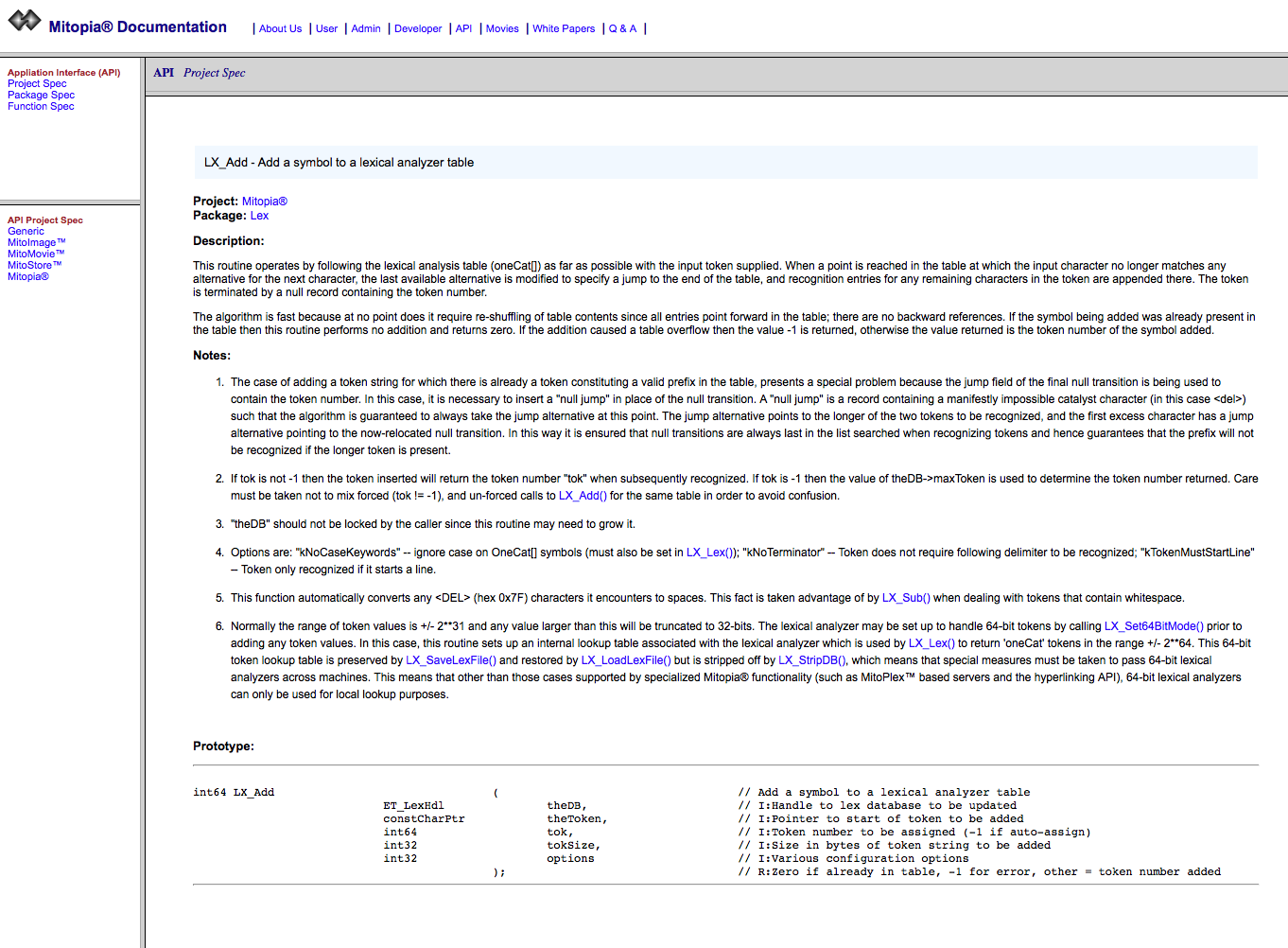
- Every function prototype is declared in a column aligned form (as illustrated above) where the ‘//’ comment marker occurs at column 80. The prototype declares the function parameters one per line with a standard line comment following that uses the convention ‘I:’ or ‘O:’ (or ‘IO:’) to define if the parameter is an input, an output, or both and then gives a parameter description. The standardization of these function prototypes and the function (and package) headers is leveraged by code built into Mitopia® itself to auto-generate the API documentation from the actual source code (much like the Javadoc and Doxgen tools). This Mitopia® tool generates all public code documentation (as a web site) whenever needed, and this approach ensures that the documentation always matches the code (which is rarely the case otherwise). Note the philosophical point that the tools you use should be actually within the program you are working on where possible, that way they stay up to date and don’t complicate your build scripts etc. For an example see below – note the auto-hyperlinking within the documentation by recognizing function names, the automatic arrangement of documentation by packages and project/subsystems, and the integration with other forms of documentation – all done automatically. Other Mitopia® internal tools use these standardized headers to perform code analysis and generate metrics (e.g., historical code metrics). The entire focus is to drive everything from the code, which is in reality about the only thing one can force developers to update properly.
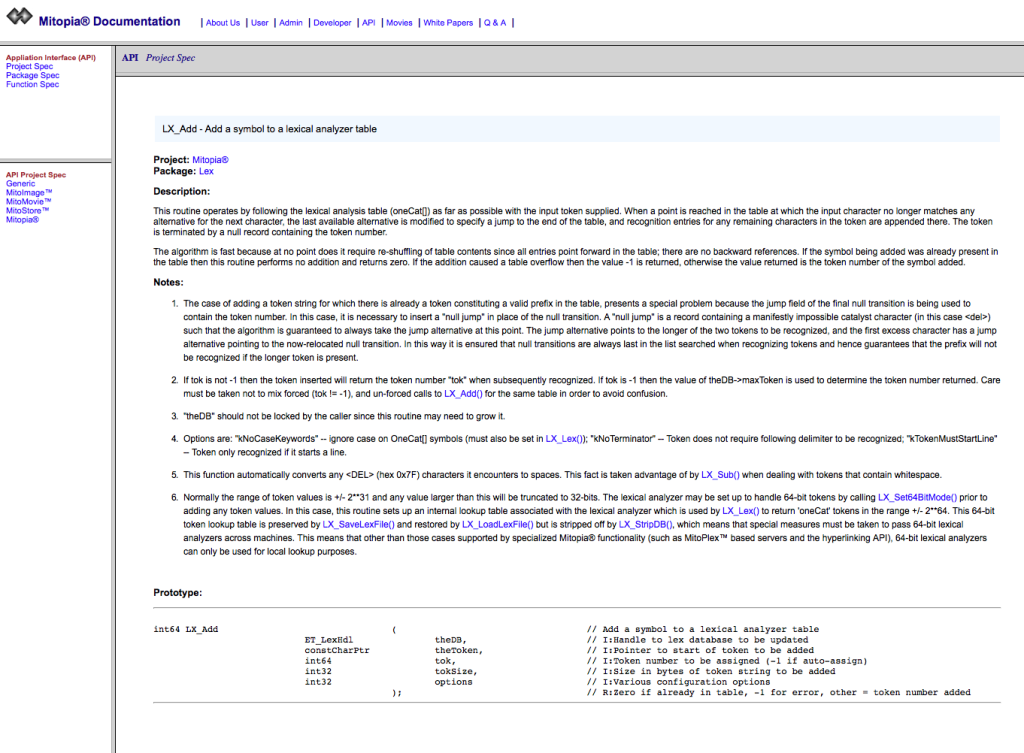
Example auto-generated documentation from standardized headers/prototypes
- Non-static function prototypes are accumulated (organized by package) into a SINGLE private function headers file for each subsystem (e.g., MitopiaFuncs.h). Non-static constants are similarly organized into a single file per subsystem (e.g., MitopiaConsts.h), as are types (e.g., MitopiaTypes.h), and globals (e.g., MitopiaGlobs.h). We found that the standard approach of one header file per source file led to conflicting definitions, proliferation of trivial files, and an inability to quickly find things. This was why we required header file unification on a per subsystem (e.g., Mitopia, MitoImage, MitoMovie, MitoScript, MitoSphere, etc.) – it vastly improves comprehension and reduces inconsistencies (since the compiler will forbid multiple conflicting declarations in the headers), it also means that only a single header per subsystem needs to be included in source code.
- Using these unified header files, a custom MitoSystems tool automatically creates a single public header file during build containing only those portions of all declarations in the individual files that are not with an ‘#ifdef INCLUDE_PRIVATE‘ conditional compilation block. Similarly a unified private file is created containing all content. The private header is used within the subsystem, the public header is used elsewhere. This automated approach thus ensures that maintenance changes can never create inconsistencies in headers (or documentation) which is otherwise one of the primary causes trouble downstream. All this from a few simple rules regarding header files, function prototypes, and function/package commenting standards.
- Every function starts with an ENTER() macro and ends with a RETURN() macro. These macros are leveraged to provide a host of benefits. The ENTER() macro for example (which must be the first statement of the function) internally declares necessary variables and implements logic that provides the full stack crawl capability associated with all Mitopia® errors. This same capability is utilized in Mitopia’s built-in leak checking technology to tag allocations with a crawl where allocated. This makes leak hunting and resolution almost trivial within Mitopia®. Setting various debugging options also allow this macro to provide pervasive thread debugging, full execution profiling of function calls and execution times, stack depth monitoring, and many other capabilities critical to rapid fault isolation. The matching RETURN() macro is critical to much of this functionality and also effectively enforces the requirement that there be only a single return statement (at the end of the function – labelled either ImmediateExit or Good/BadExit by convention) for all functions.

details of the RETURN macro
It does this by redefining the C reserved word ‘return‘ so that it cannot be used in the code directly, and so that if used twice in the same function, it will generate a compiler error/warning. Experience has shown that having multiple return statements dotted around a function is the #1 cause of leaks and other unintended side effects introduced by subsequent maintainers that have not fully understood all possible execution paths. By enforcing a single exit, all these debugging features are possible and it also makes all functions look the same and perform their cleanup in a standard place. Moreover, notice the three definitions RETURN_ret, RETURN_void, and RETURN(res). In effect these enforce another standard which is that the return value for ALL functions must be either ‘void‘, or ‘ret‘ (since RETURN(x) where ‘x‘ is anything else is undefined). Figuring out what a function is returning is a key time waster when stepping through code. Through these macros, this problem goes away, the function return value is always called ‘ret‘ (you can’t even return constants like true or false!). Again this standard is focussed on the goal of rapid code understanding, and the ENTER()/RETURN() formalism is a huge part of enforcing this standardizations in a way that programmers cannot simply work around.

Common pattern for function exit handling
- Code indentation is by one tab character per block, ‘{‘ and ‘}‘ always aligned vertically with each other and with the outer code indent (i.e., no ‘leftie’ (per K&R), ‘uppie’, or ‘innie’ forms – MitoSystems code is always ‘outie’). This requirement is made to facilitate rapid scanning of complex blocks of code for block structure without having to waste time looking for the matching ‘{‘ or ‘}‘ mixed up with any other tokens. They are on their own line and always vertically aligned. Once again understanding the block structure of the code is a key time waster during debugging of unfamiliar code and this convention minimizes this.
- Variable names and parameters use ‘camel case‘ first char always lower, constants (#define) generally start with ‘k’ and use camel case, or if complex or fundamental in some way, they are all upper case. Types generally start with an upper case character and also use camel case, they may include the package prefix. Low level built in types (e.g., int32, anonPtr, etc. are an exception). This allows easy and rapid recognition of what something is. Variable names need not be over long since given other coding standards, the programmer can rapidly identify their purpose, and making longer names simply ‘spreads out’ the code making it harder to see the meta-structure.
- No space between function names and their parameters, however except for unary operators, there should be a space between operators and their operands.
- Block comments (i.e., /* and */) are discouraged in favor of line comments throughout. This allows block comments to be trivially used on a temporary basis to comment out any chunk of code. Line comments (i.e., // ) except for function headers and very occasionally large block discussions always start at column 80 and describe in English the purpose of the statement only if necessary to clarify.
- Blank lines between lines of code should be kept to an absolute minimum. Combined with the commenting standards, this ensures that the maximum amount of code can be seen at once (a large screen is required for the comments) and ensures that comments don’t break up the obvious structure of the function since they are pushed off to the right thus allowing pure compact and standardized indented code on the left side. Note that some lines of code may extend well past the 80 column mark if this makes the overall structure of the code easier to understand at a glance (primary related to block indenting). The effect of this, when combined with code ‘coloring’ provided by the development tools (in the example above types and functions are blue, strings red, macros/defines brown, and comments green), is to greatly increase the speed with which it is possible to understand ‘at a glance’ what a function is trying to do, and this is of course critical to operating effectively within a vast and largely unfamiliar code base. Comments embedded within code degrade this ability and should either be moved to the right (if brief), or to the function header “Notes:” (if more extensive); this allows them to be looked at only if/when the reader wants to and so increases speed of understanding.
- Where a function may take parameters specifying various optional behaviors, the last parameter to the function should be an integer ‘options‘ parameter and the various options mask bits are defined (along with the function prototype in the ProjectFuncs.h header) by constant bit masks (e.g., kDoSomethingSpecial) which can be added together in order to specify multiple options. This makes it simple for the unfamiliar reader to find such options, and also avoids having to change the external API whenever a new option is added.
- No static globals are allowed, all globals for a subsystem should be referenced via a single global pointer which references a globals structure. This allows all such globals to be easily found and examined in a debugger and ensures they are all cleaned up as required.
- Declarations within inner blocks of a function should not be used, only the initial declarations list for the function should be used. Once again this ties into the unified cleanup solution imposed by the ENTER() and RETURN() macros. The only allowable exception is variables associated with conditionally compiled testing code within the function. Do not initialize local variables to anything other than a constant in the declarations section.
- Labels always start at column zero.
Bottom line for all these basic standards and conventions is they make the code easier to understand and test, and they automate completely the task of making documentation match code, as well as various other maintenance tasks that might otherwise be avoided by the lazy.
Packaging, abstraction, and run-time standards
In addition to the basic MitoSystems coding standards described above, Mitopia® itself imposes a number of of additional rules to further enhance reliability and programmer productivity within a large code base. The paragraphs below discuss some of these standards.
All code should utilize the standard abstractions provided by Mitopia® to manipulate data structure aggregations. These standard metaphors include the flat memory model, types and the ontology, string lists, lexical analyzers, and the database/persistent memory abstractions. In particular, the creation of any memory resident structure that contains pointer links is strongly discouraged. The underlying abstractions are powerful enough to represent anything one might need and are highly optimized. By using them for all things, we make the operation of most areas of the code immediately familiar by analogy with other known code based on the same abstractions. Of course the minimize the code size and avoid introducing low level bugs also.
The code should be designed throughout to be as platform and architecture independent as possible (e.g., endian issues). This means overt declaration of the size of variable implementation intended (as in the sequence int16, int32, int64). This runs somewhat contrary to C norms, however experience has shown that programmers alway have in their mind what size ‘int‘, ‘long‘, or ‘short‘ might be, even if not stated, with the result that code breaks badly over time through range and structure alignment changes mandated by compilers and the underlying processors. The only constant in this world is change, and change breaks all hidden assumptions. Better to be explicit in everything – including explicit structure padding if needed to guarantee universal alignment. The only exception to this rule is the C assumption that ‘long‘ is the same size as a pointer (though that may be either 32 or 64 bits depending). If in doubt, use 64-bit values for integers and double for real – with modern computers there is really no reason not to.
Further to the platform independent goal, all calls to the underlying OS toolbox (and C library for that matter) must be wrapped (and preceded by the prefix XC_ e.g. XC_NewPtr). These wrappers are all declared in the single header file ToolBoxMap.h, and the implementations (which simply call the toolbox routine) are all gathered into ToolBoxMap.c. This structure ensures that all toolbox/external calls emanate from ToolBoxMap.c, and the macros XC_fnName() declared in ToolBoxMap.h and used to invoke are the wrapper functions can then be organized to go through a mapping table. This in turn allows any and all toolbox calls to be dynamically patched for debugging purposes, or if one switches to an underlying OS that does not provide it. This allows calling code the be platform agnostic to the highest degree possible.
One key example of use of this technique is to wrap all memory allocators and de-allocators and then substitute alternates that take advantage of the ENTER() and RETURN() formalism in order to implement leak checking and a variety of other critical debugging capabilities. In this way, all allocations can be fully analyzed by Mitopia® itself without requiring external debugging capabilities. This is essential in a heavily multi-threaded environment such as Mitopia® where tracing memory ownership becomes a real challenge any other way. The end result is that you cannot find direct toolbox calls in any Mitopia® code other than the wrappers.
Packages should provide a complete suite of functions to manipulate the abstraction to which they relate, all those functions (public and private) appearing within a single source file. Externally defined structure types should be avoided if at all possible. Instead provide additional accessor functions to get at fields hidden within structures referenced via an abstract reference. Publishing structures is a sin and inevitably leads to problems down the line with client code directly accessing the structure which may of course change later. Better to hide the data behind the package accessor functions. The entire Mitopia® code base publishes less than 100 structure types publicly (that is substantially less than one per Mitopia abstraction package) despite having many times that defined and used internally. On the other hand, there are literally thousands of public API calls grouped into packages. If data structure is to be published, use the ontology.
Mitopia® code tends to be very dense in terms of the number of functions called compared to the kind of code one might find say in an open source project. The snippet below is typical:
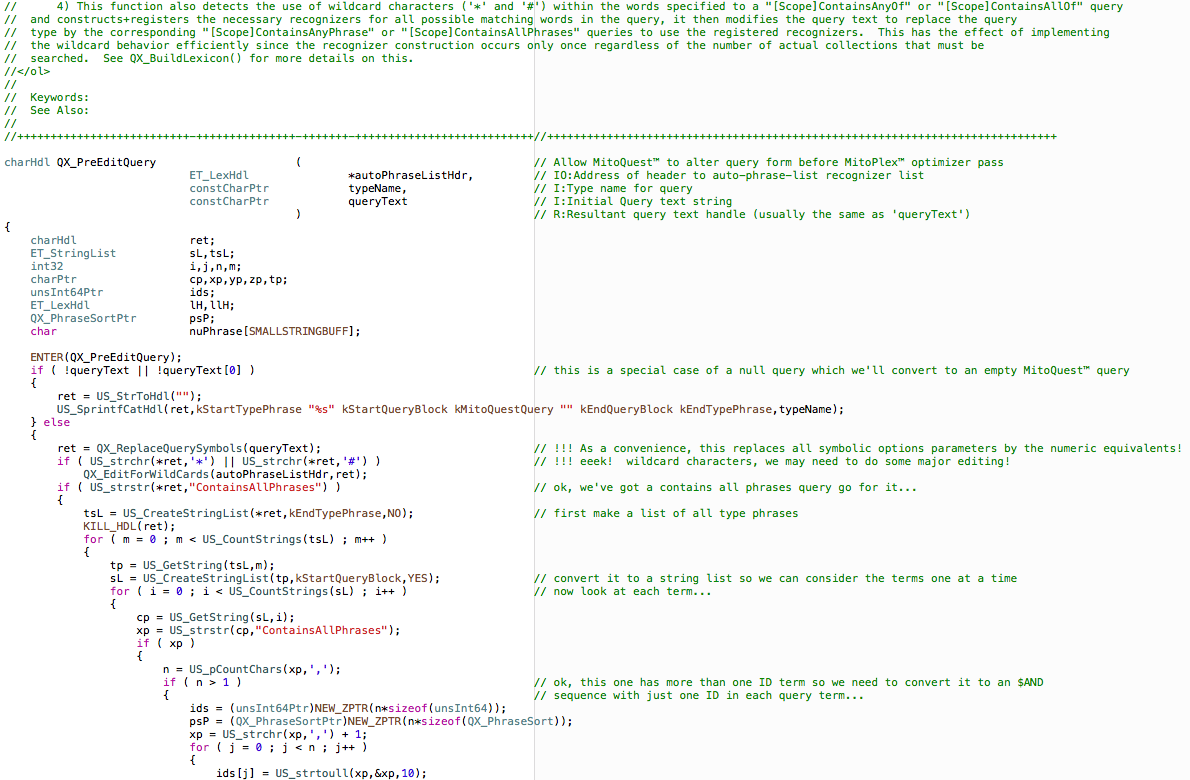
As can be seen the code utilizes abstraction functions from a variety of packages to do virtually everything, there is generally very little actual complex manipulation done locally. The function above is part of the implementation of the MitoQuest database server and is running within the servers, however, because even Mitopia’s database abstraction is built on the same fundamental underpinnings, the code looks identical to what a client side function might be doing and calls all the same kinds of packages. When combined with the other coding standards above, this tends to make all Mitopia® code look similar and instantly recognizable as to its purpose. This in turn makes all code easy to comprehend and maintain in a way that I would argue is far more effective than the kinds of ‘placebo’ organizing metaphors offered by standard programming languages.