
To a large extent, the decision to specify a data flow (also see here and here) based Mitopia® system as opposed to a control-flow based one was driven by a common higher level “adaptability” goal that also led to identifying and addressing the “Software Bermuda Triangle” issue (see earlier post here). In particular, for complex systems, such as those designed for multimedia intelligence and knowledge management applications, there is a fundamental problem with current ‘control flow’ based design methods that renders them totally unsuited for these kinds of systems. Once the purpose of a system is broadened to acquisition of unstructured, non-tagged, time-variant, multimedia information (much of which is designed specifically to prevent easy capture and normalization by non-recipient systems), a totally different approach is required. In this arena, many entrenched notions of information science and database methodology must be discarded to permit the problem to be addressed. We will call systems that attempt to address this level of problem ‘Unconstrained Systems’ (UCS). A UCS is one in which the source(s) of data have no explicit or implicit knowledge of, or interest in, facilitating the capture and subsequent processing of that data by the system. To summarize the principal issues that lead one to seek a new paradigm to address unconstrained systems, they are as follows:
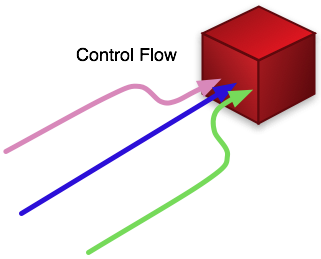 Change is the norm. The incoming data formats and content will change. The needs and requirements of the users of the data will change, and this will be reflected not only in their demands of the UI to the system, but also in the data model and field set that is to be captured and stored by the system.
Change is the norm. The incoming data formats and content will change. The needs and requirements of the users of the data will change, and this will be reflected not only in their demands of the UI to the system, but also in the data model and field set that is to be captured and stored by the system.- An unconstrained system can only sample from the flow going through the pipe that is our digital world. It is neither the source nor the destination for that flow, but simply a monitoring station attached to the pipe capable of selectively extracting data from the pipe as it passes by.
- The system cannot ‘control’ the data that impinges on it. Indeed, we must give up any idea that it is possible to ‘control’ the system that the data represents. All we can do is monitor and react to it. This step of giving up the idea of control is one of the hardest for most people, especially software engineers, to take. After all, we have all grown up learning that software consists of a ‘controlling’ program which takes in inputs, performs certain predefined computations, and produces outputs. Almost every installed system we see out there complies with this world view, and yet it is obvious from the discussion above that this model can only hold true on a very localized level in a UCS. The flow of data through the system is really in control. It must trigger execution of code as appropriate depending on the nature of the data itself. That code must be localized and autonomous. It cannot cause or rely upon tendrils of dependency without eventually clogging up the pipe. The concept of data initiating control (or program) execution rather than the other way is alien to most programmers, and yet it becomes fundamental to addressing unconstrained systems.
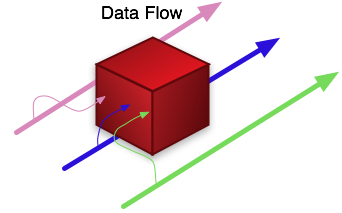 We cannot in general predict what algorithms or approaches are appropriate to solving the problem of ‘understanding the world’. The problem is simply too complex. Once again we are forced away from our conventional approach of defining processing and interface requirements, and then breaking down the problem into successively smaller and smaller sub-problems. Again, it appears that this uncertainly forces us away from any idea of a control-based system and into a model where we must create a substrate through which data can flow and within which localized areas of control flow can be triggered by the presence of certain data. The only practical approach to addressing such a system is to focus on the requirements and design of the substrate and trust that by facilitating the easy incorporation of new plug-in control flow based ‘widgets’ and their interface to data flowing through the data-flow based substrate, it will be possible for those using the system to develop and ‘evolve’ it towards their needs. In essence, the users, knowingly or otherwise, must teach the system how they do what they do as a side effect of expressing their needs to it. Experience shows that any more direct attempt to extract knowledge from users or analysts to achieve computability, is difficult, imprecise, and in the end contradictory and unworkable. No two analysts will agree completely on the meaning of a set of data, nor will they concur on the correct approach to extracting meaning from data in the first place. Because all such perspectives and techniques may have merit, the system must allow all to co-exist side by side, and to contribute, through a formalized substrate and protocol, to the meta-analysis that is the eventual system output. It is illustrative to note that the only successful example of a truly massive software environment is the Internet itself. This success was achieved by defining a rigid set of protocols (IP, HTML etc.) and then allowing Darwinian-like and unplanned development of autonomous but compliant systems to develop on top of the substrate. A similar approach is required in the design of unconstrained systems. Loosely coupled data-flow based approaches facilitate this.
We cannot in general predict what algorithms or approaches are appropriate to solving the problem of ‘understanding the world’. The problem is simply too complex. Once again we are forced away from our conventional approach of defining processing and interface requirements, and then breaking down the problem into successively smaller and smaller sub-problems. Again, it appears that this uncertainly forces us away from any idea of a control-based system and into a model where we must create a substrate through which data can flow and within which localized areas of control flow can be triggered by the presence of certain data. The only practical approach to addressing such a system is to focus on the requirements and design of the substrate and trust that by facilitating the easy incorporation of new plug-in control flow based ‘widgets’ and their interface to data flowing through the data-flow based substrate, it will be possible for those using the system to develop and ‘evolve’ it towards their needs. In essence, the users, knowingly or otherwise, must teach the system how they do what they do as a side effect of expressing their needs to it. Experience shows that any more direct attempt to extract knowledge from users or analysts to achieve computability, is difficult, imprecise, and in the end contradictory and unworkable. No two analysts will agree completely on the meaning of a set of data, nor will they concur on the correct approach to extracting meaning from data in the first place. Because all such perspectives and techniques may have merit, the system must allow all to co-exist side by side, and to contribute, through a formalized substrate and protocol, to the meta-analysis that is the eventual system output. It is illustrative to note that the only successful example of a truly massive software environment is the Internet itself. This success was achieved by defining a rigid set of protocols (IP, HTML etc.) and then allowing Darwinian-like and unplanned development of autonomous but compliant systems to develop on top of the substrate. A similar approach is required in the design of unconstrained systems. Loosely coupled data-flow based approaches facilitate this. The most basic change that must be made is to create an environment that operates according to data-flow rules, not those of a classic control-flow based system. At the most fundamental operating system scheduling level, we need an environment where presence of suitable data initiates program execution, not the other way round.
The most basic change that must be made is to create an environment that operates according to data-flow rules, not those of a classic control-flow based system. At the most fundamental operating system scheduling level, we need an environment where presence of suitable data initiates program execution, not the other way round.Data-flow based software design and documentation techniques have been in common usage for many years. In these techniques, the system design is broken into a number of distinct processes and the data that flows between them. This breakdown closely matches the perceptions of the actual system users/customers and thus is effective in communicating the architecture and requirements.
Unfortunately, due to the lack of any suitable data-flow based substrate (see here), even software designs created in this manner are invariably translated back into control-flow methods, or at best to message passing schemes, at implementation time. This translation begins a slippery slope that results in such software being of limited scope and largely inflexible to changes in the nature of the flow. This problem is at the root of why software systems are so expensive to create and maintain.
A critical realization when following the reasoning above, was that the islands of computation that are triggered by the presence of matching data in a functional data-flow based system must express their data needs to the outside world through some kind of formalized pin-based interface such that the ‘types’ of the data that is required to cause an arriving ‘token’ to appear on any given pin must be discovered at run-time by the system substrate responsible for triggering the code island when suitable data arrives. This clearly means that such a system will require a run-time discoverable types system as opposed to a compile-time types system as found in common programming languages including OOP.
Since we might want to pass any type whatsoever to a given code island (‘widget’ in Mitopia® parlance), this implies that the run-time type system must be capable of compiling all the C header files for the underlying OS in addition to any additional types that might be specific to any given application of the system (i.e., the system ontology). The bottom line then is that such a system must implement a full C type compiler together with a type manager API that is capable of describing, discovering, and manipulating the type of any data occurring within system data flows. The result being that compiled structure types defined using C itself would be identical and interchangeable in binary form to those generated by the type manager. If such a system were to be created, and if all system code were to access data through the type manager, rather than by direct compiled access in the code, then one would have a substrate for which it were possible to have ZERO compiled types in the code that had anything to do with the actual application (or its ontology) and which would thus be completely generic and highly adaptive. Moreover, such a substrate is a necessary precursor to building a data-flow based system capable of dynamic run-time wiring and adaptability mediated by the underlying architecture without any need for individual widgets to know or care what they are connected to in the larger system.
This then set the stage for the first radical departure in Mitopia’s type manager (i.e., ontology system), which is that the ontology description language (ODL) must manipulate binary data through run-time type discovery, and must include and extend the C language itself. This is unlike any other ontology language in existence.
C headers specifying C binary structures can be handled natively by type manager based code, that is, there is no need for any intermediate textual forms associated with the ontology or the data it describes. All operations, including textual operations, operate on data held natively in its binary form. This of course provides massive performance benefits at the cost of introducing considerable complexity into the substrate, including the need to be aware of tricky issues such as alignment and byte ordering (e.g., big endian vs. little endian – see here) when operating in a heterogeneous data-flow based network.
Conventional semantic markup ontology languages, as stated previously, do not address actual storage or implementation of data, but instead allocate “attributes” to a “class”, where these attribute are textual and have no relation to any existing programming language, or any means of actually storing them in a binary form. Thus Mitopia’s type manager is not a markup language, it is instead a run-time typed interpreted language that includes and extends upon the C programming language.
Initial experimentation on this concept of data-flow in 1989 and 1990 using a transputer-based co-processor card led to additional realizations regarding the needs of such a data-flow system that further focused the evolution of Mitopia’s type system and ODL. The primary realization was that in any large scale data-flow based system, there is a need to pass not only isolated structures, but also whole collections of structures all cross referencing each other in various ways. Conventionally, this would require the duplication of any complex collection by following all the pointers buried within it and duplicating them while updating the references, so that the passed copy of the collection would be functionally identical though completely separate from the original (i.e., pass by value not reference). It rapidly became clear that this duplication and replication process becomes the dominant constituent of CPU load in any data-flow system passing significant numbers of such compound structures across its flows. The problem is exacerbated dramatically as the data is passed from one CPU/address space to another, since this requires that the data be serialized into an intermediate textual form and then de-serialized and re-assembled in the new address space. This issue is faced to a much lesser degree by conventional systems that share data, and is usually addressed by serializing to/from XML as the textual intermediate. Unfortunately the timing overhead for this is unacceptable for a data-flow based system.
To see why this is so consider that the incredible performance of today’s processors, software systems and databases, is driven primarily by their ability to rapidly manipulate binary data representing the problem domain, we can see that a text-based semantic ontology approach is going to introduce all kinds of performance limitations and bottlenecks. This occurs as the textual representation of the data (e.g., “3.14159”) is continually and pervasively converted back and forth to/from the appropriate binary forms, in order to get anything done (including of course sharing any data with other systems). To see the impact of this, consider the timing for the two C code snippets shown below which represent the direct addition of two numbers held either directly or in textual form (an operation that at the lowest level represents the performance difference between the two approaches):

The second code snippet takes 275 times longer than the first to execute, so we can anticipate a similar performance problem will strike any semantic ontology-based system when we attempt to scale it. In the semantic ontology world, the intermediate textual form is XML. Slapping a text-based semantic ontology onto a system that represents and manipulates data at the binary level (i.e., all systems!) is unlikely to scale in a data-flow environment. Instead such a system would be forced to accomplish things using a slower ‘batch’ strategy, which is in fact exactly what we see out there now. Indeed the quote below is taken from a DrDobbs article on the problem of using XML as a textual intermediate for data exchange:
 As a result of thinking about this issue in the early 90’s, Mitopia’s unique memory model as embodied most visibly in the “Type Collections” technology eventually emerged. The basic technique was to discourage the use of pointers and replace them with ‘relative’ references so that all data in a collection, including all the cross references, could be contained and manipulated within a single variable sized memory allocation using the “type collections” abstraction. Nodes within such a collection have associated types as discovered and defined by the type manager. This allows the entire binary collection to be passed across data flows (local or remote) without any modification whatsoever, while still being completely functional at the destination thereby eliminating the performance bottleneck.
As a result of thinking about this issue in the early 90’s, Mitopia’s unique memory model as embodied most visibly in the “Type Collections” technology eventually emerged. The basic technique was to discourage the use of pointers and replace them with ‘relative’ references so that all data in a collection, including all the cross references, could be contained and manipulated within a single variable sized memory allocation using the “type collections” abstraction. Nodes within such a collection have associated types as discovered and defined by the type manager. This allows the entire binary collection to be passed across data flows (local or remote) without any modification whatsoever, while still being completely functional at the destination thereby eliminating the performance bottleneck.We will discuss this concept further in later posts.