
According to the US Government’s AI R&D Strategic Plan (Oct 2016):
——————————-
Since its beginnings, AI research has advanced in three technology waves. The first wave focused on handcrafted knowledge, with a strong focus in the 1980s on rule-based expert systems in well-defined domains, in which knowledge was collected from a human expert, expressed in “if-then” rules, and thenimplemented in hardware. Such systems-enabled reasoning was applied successfully to narrowly defined problems, but it had no ability to learn or to deal with uncertainty. Nevertheless, they still led to important solutions, and the development of techniques that are still actively used today.
The second wave of AI research from the 2000s to the present is characterized by the ascent of machine learning. The availability of significantly larger amounts of digital data, relatively inexpensive massively parallel computational capabilities, and improved learning techniques have brought significant advances in AI when applied to tasks such as image and writing recognition, speech understanding, and human language translation. The fruits of these advances are everywhere: smartphones perform speech recognition, ATMs perform handwriting recognition on written checks, email applications perform spam filtering, and free online services perform machine translation. Key to some of these successes was the development of deep learning.
Despite progress, AI systems still have their limitations. Virtually all progress has been in “narrow AI” that performs well on specialized tasks; little progress has been made in “general AI” that functions well across a variety of cognitive domains. Even within narrow AI, progress has been uneven. AI systems for image recognition rely on significant human effort to label the answers to thousands of examples. In contrast, most humans are capable of “one-shot” learning from only a few examples. While most machine vision systems are easily confused by complex scenes with overlapping objects, children can easily perform “scene parsing.” Scene understanding that is easy for a human is still often difficult for a machine.
The AI field is now in the beginning stages of a possible third wave, which focuses on explanatory and general AI technologies. The goals of these approaches are to enhance learned models with an explanation and correction interface, to clarify the basis for and reliability of outputs, to operate with a high degree of transparency, and to move beyond narrow AI to capabilities that can generalize across broader task domains. If successful, engineers could create systems that construct explanatory models for classes of real world phenomena, engage in natural communication with people, learn and reason as they encounter new tasks and situations, and solve novel problems by generalizing from past experience. Explanatory models for these AI systems might be constructed automatically through advanced methods. These models could enable rapid learning in AI systems. They may supply “meaning” or “understanding” to the AI system, which could then enable the AI systems to achieve more general capabilities.
AI approaches can be divided into “narrow AI (ANI)” and “general AI (AGI).” Narrow AI systems perform individual tasks in specialized, well-defined domains, such as speech recognition, image recognition, and translation. Several recent, highly-visible, narrow AI systems, including IBM Watson and DeepMind’s AlphaGo, have achieved major feats. Indeed, these particular systems have been labeled “superhuman” because they have outperformed the best human players in Jeopardy and Go, respectively. But these systems exemplify narrow AI, since they can only be applied to the tasks for which they are specifically designed. Using these systems on a wider range of problems requires a significant re-engineering effort.
In contrast, the long-term goal of general AI is to create systems that exhibit the flexibility and versatility of human intelligence in a broad range of cognitive domains… Broad learning capabilities would provide general AI systems the ability to transfer knowledge from one domain to another and to interactively learn from experience and from humans. General AI has been an ambition of researchers since the advent of AI, but current systems are still far from achieving this goal. The relationship between narrow and general AI is currently being explored; it is possible that lessons from one can be applied to improve the other and vice versa.
——————————-
While there is no general consensus, most AI researchers believe that general AI (AGI) is still decades away, requiring a long-term, sustained research effort to achieve. A published survey of AI experts yielded an average estimate for a 50/50 chance of broad AGI (also known as High Level Machine Intelligence or HLMI i.e., matching a human professional at a given task) happening as 2081. That is a long way off!
It is clear therefore that when talking about AI, we must be very careful not to confuse the huge progress being made in 2nd wave ANI systems with the challenge still before us in developing 3rd wave AGI systems. Most non-experts conflate the two and thus expect the truly ‘smart’ systems of the future to be right around the corner. They are not.
We now have some understanding of why ANI systems and neural nets in general are able to recognize patterns in seemingly complex, but narrowly limited sets of data. Ultimately it ties back to the fact that despite the apparent complexity, simple physical theories with very few ‘terms’ in their descriptive equations underly those patterns, and neural nets are thus capable of recognizing the patterns without too many ’terms’ in their abstract and utterly inscrutable representation of them. This likely explains ANI’s success. But AGI precludes narrow limitations and more so inscrutability. For the near term, the road to AGI is not paved with more layers of neurons or more sophisticated feedback architectures. For AGI to ‘reason’, the ‘patterns’ recognized by ANI ‘components’ (in a biological context these correspond to the sensory system), must be categorized and placed into an internal digital ‘ontology’ detailing the things that may exist in the world and how they interrelate. Once this is done, reasoning using the knowledge held in that formalized ontological substrate becomes possible. Knowledge needs to be stored, accessed, and reasoned on directly in binary form as described by the formal ontology, it can’t be some kind of detached ‘graph’ bolted on top of raw data.
So if the ultimate goal is broad domain AGI or HLMI, we need to find a way to create this ontological reasoning substrate, and it is apparent that neural nets are not going to get us there any time soon, we need another way. Regrettably most current AGI research focussed either on full brain emulation (hence the long expert time predictions), or on just the ‘reasoning’ aspect, not on the more practical question of “what would it take to create the substrate and to integrate/combine filtered outputs from all those ANI ‘feeds’ in order to make sense of the real world in real time”.
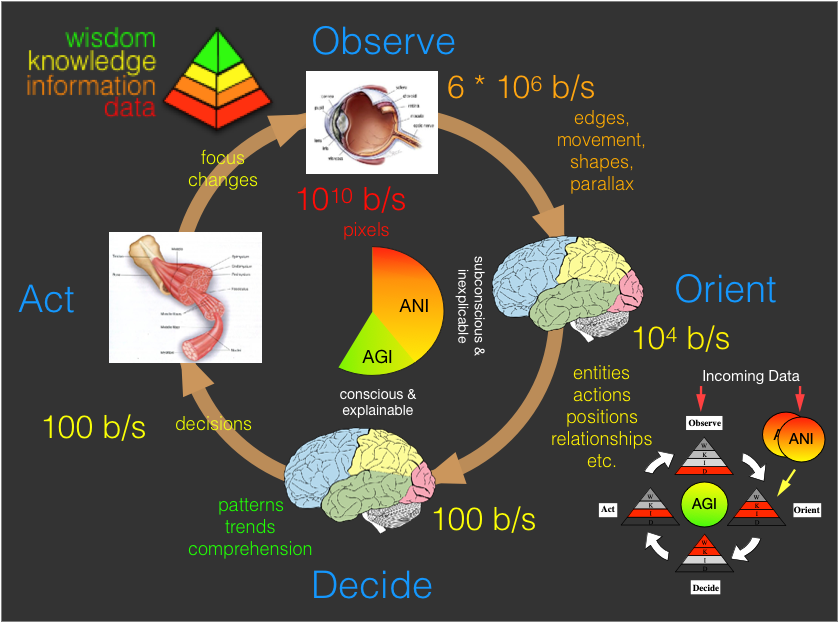
Take for example the human visual sensory system & decision cycle (depicted above). Note that I’ve organized this data as a cycle (or Observe Orient Decide Act – OODA) loop (see earlier post). Being ‘smart’ and operating effectively in the real world (i.e., AGI) requires constant re-evaluation and adapting as the situation unfolds hence unlike ANI, real-world AGI is intimately tied to decision cycles. Note also that the descriptive text around the loop is colored to match the ‘level’ of the data being transmitted at that point in the knowledge pyramid – more on this later. Most importantly, when discussing the role of ANI ‘components’, note that the data rates and ‘level’ differ significantly as we go around the loop. Raw ‘data’ is refined to ‘information’ and then ‘knowledge’ before being presented for decision making (i.e., conscious thought/reasoning) in the ‘Decide’ step. The data rates are taken from the pivotal paper “Two views of brain function” by Marcus E. Raichle (2010). His findings were as follows:
- 1010 bits/s of data hit retina (4K 30fps video = 1.2 x 1010)
- 6 x 106 bits/s leave retina (compressed 4K video = 2 x 107)
- 104 bits/s make it to layer IV of V1 in the cortex
- Similar pattern for other senses.
- Human consciousness bandwidth = 100 bits/s
The problem that must be overcome is that high resolution raw sensory data is needed about our surrounds, but this requires around 10 billion bits per second and which must be reduced to around 100 bits per second before it can be ‘reasoned’ on by our conscious mind. In other words virtually everything we experience must be thrown away if we are to be able to keep up consciously. Initially this seems like a job for compression, but lossless compression will only get us at most a factor of 10, and classic lossy compression maybe another order of magnitude or two, we would still be a factor of around 100,000 short of what we need to feed into the hundred-baud modem that is our conscious mind. So the fact is that we can passively stare at the world around us and experience it in glorious hi-def, but as soon as we need to think consciously about anything we see, a whole different pathway and process kicks in, and hi-def it is not.
Remember also that this is just our visual sensory system, at the same time all our other sensory systems are passively delivering hi-def representations of the world around us, some critical aspects of which may need to be processed consciously. Clearly something completely different from classic compression must be happening going round these loops. All our senses must compete for limited slots of our mind’s focus, and to get those slots they must present input not in raw form, but in a form that can be rapidly ‘understood’ and prioritized otherwise it will lose its ‘slot’. This means that sensory input must be converted as it goes around the decision cycle to just its most relevant content as refined up the knowledge pyramid to the Knowledge Level (KL) so that it is able to participate in the ruthless conscious ‘slot’ allocation fight. The diagram below illustrates for the visual case the fundamentals of how we do this and how this translates from the analog to the digital world.
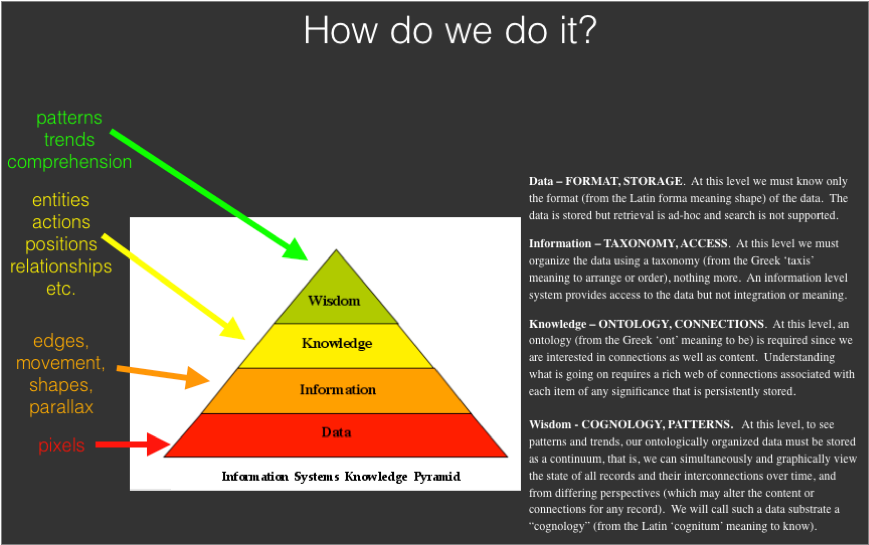
One of the first posts on this site was about exactly this subject. In a sense today’s post simply brings that early post up to date using today’s more refined AI terminology, nothing has really changed from a Mitopia perspective. This should be no surprise since the practical AGI question mentioned above of “what would it take to create the substrate and to integrate/combine filtered outputs from all those ANI ‘feeds’ in order to make sense of the real world in real time” and Mitopia’s original design requirement (back in the early 90’s) of “what would it take to understand everything going on in the world and make sense of it to augment human decisions within an intelligence system” are fundamentally the same.
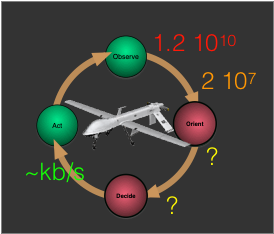
To see the parallels with today’s technical ‘smart’ system frontiers, consider the current intense focus on making drones wholly or partially autonomous (i.e., .smart’) in order to create next generation capabilities and markets. Currently such systems (like most ‘smart’ technologies) are stalled waiting for AGI to close the loop. The OODA loop for such a drone (and the data rates involved) might look as shown to the right. Note that the incoming data rates for a 4K video camera are roughly identical to those for the human visual system. To be ‘smart’, the drone has the same problem we do.
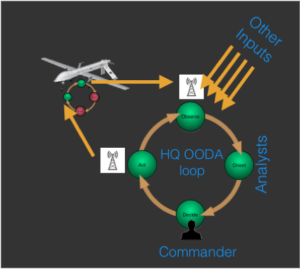
Because right now such systems have no underlying unifying substrate to which the existing ANI systems attached to the cameras (e.g., systems for recognizing vehicles, people, explosions, gunshots, etc. below) can feed their outputs for reasoning, none can internally fully close the ‘Orient’ and ‘Decide’ part of the loop in the real world with the result that 3rd wave AGI enabled systems are not currently possible. Instead we get intermediate human in the loop type approaches as illustrated to the left for a military drone application. Such a loop suffers from a number of obvious shortcomings, not the least being inability to keep up with the evolving situation on the ground because the loop cannot be closed on-board.
And this finally brings us to the differing roles of narrow and general AI and how they tie together. Put simply, narrow AI is found in the ‘components’ that do the filtering of raw data into its KL equivalents. All the amazing things we now associate with ANI such as speech recognition, image recognition, translation, Siri and Google assistant, machine learning, and even IBM Watson, can be characterized by having a limited domain with the goal of boiling complex high bandwidth data down to produce as output the significant ‘entities’ or ‘things’ that are within it. In other words ANI is the equivalent of the data rate filtering that we find in the ‘Observe’ and ‘Orient’ steps of natural sensory systems. Despite recognizing patterns within the data, which ANI is able to do so with relatively simple neural machinery (see earlier discussions), by itself it can assign no ‘meaning’ to them, it simply identifies that data matches a trained ‘pattern’ and tags it with and identifying type indicating the pattern involved (e.g., face, tank, road sign, kitten, etc.). These tags have no inherent meaning to the ANI itself, but it is these tags (along with just a reference to the backing data) that needs to get passed further round the decision cycle.
These ‘type tags’ match some type or individual instance defined in the cognitive ontology that underlies the AGI platform so allowing their instantiation into the ontological substrate which organizes and interrelates them for reasoning to begin. In this sense then the output of an ANI ‘component’, from the perspective of a system designed to facilitate decision making (either an intelligence architecture like Mitopia, or a future autonomous ‘smart’ system), is not fundamentally different from any other simple conventional external ‘source’ generated by other human beings or otherwise (e.g., a news feed, email, database query, etc.). They are all just sources to such a system, and all must be combined and integrated within a unifying ontology based on a universal Theory of Understanding (TOU) so that broad domain reasoning can take place.
In such a formalism, conventional sources (e.g., databases, web sites, publications, etc.) relating to the world at large must first be ontologically integrated to form the ‘knowledge base’ of the things that exist in the world and how they interrelate. We refer to this in Mitopia as the “Encyclopedic Knowledge”. Next ‘live’ feeds (both conventional and from ANI components) are ingested in real-time and refined into their cognitive ontological equivalents which are interconnected with the encyclopedic knowledge in order to determine which items (and connections) should be deemed important enough to send on to the decision making process. As with the natural world, digital decision making is a very compute intensive process and bandwidth constraints must be mitigated. But in this approach importance can be determined by the strength of the connections between the incoming ontological items and other existing items deemed connected (thought that same digital ontology) to any given ‘concept’ considered ‘important’ by the system. How this is done within Mitopia is the subject of numerous earlier posts and videos, so we will give only a high level overview here.
In Mitopia® each ‘Datum’ of extracted ‘knowledge’ can be thought of as analogous to a neuron, while all the ontology mediated connections to that datum/neuron are analogous to interconnecting synapses. Since all Mitopia® data is natively stored (i.e., the ontology is contiguous) and manipulated via the ontology, reasoning becomes effectively a path traversal problem executed within the system’s Carmot data set. Thus a trained Mitopia® system can be thought of as a digital brain wired not in anthropomorphic imitation of the human brain, but rather in a formalized ontological imitation of our higher conscious thinking and reasoning through use of learned internal mental models. Suffice to say that these user trained, problem-specific, weightings and connection webs determine a ‘cost’ to connect incoming observations with any ‘concept’ of interest, and thus determine priority on available decision making and reasoning resources (AGI or otherwise).
Boiled right down, the two decades of housework necessary to make Mitopia a universal Decision Support System (DSS) to filter and communicate world events with analysts in order to augment human decision making, are in fact exactly the same steps necessary to provide an AGI framework into which ANI components can be integrated to create the truly ‘smart’ systems of the future. The only real difference is how much of the ‘Decide’ part of the OODA loop is ‘closed’ by human beings.
Ignoring the huge complexity of truly integrating and interrelating in real-time all data coming from the real world in favor of investigating reasoning in constrained ‘toy’ worlds is a huge mistake and will only prolong the wait for AGI.
Given the recent explosion in ANI technologies, this is the reason we recently embarked on a multi-year project to port Mitopia in its entirety to a 32/64-bit agnostic, CPU agnostic (ARM, Intel, etc.) system capable of running on and between any Posix platform, and fundamentally dependent only on the underlying Posix core. In this ported form, Mitopia now provides a unifying underlying AGI reasoning substrate to enable truly ‘smart’ systems, both embedded and otherwise.