

Definition: A stacked deck is one that allows you to perform a magic trick.
In this post I want to provide an overview of the Mitopia® patent stack that underpins virtually all the ideas discussed in other posts on this site. In earlier posts we have examined a few of the major issues/hurdles that must be overcome in order to create and deploy a global Knowledge Level (KL) system, and briefly described how Mitopia® has solved these issues. In future posts we will examine many more such issues. The reasoning behind presenting the technology through this patent-based approach, is that the patents themselves give an effective mechanism to boil the technology down to its essentials. This list should serve as a reference point as we explore more complex technologies in future posts. However, in this post, we will simply look at each Mitopia® patent (US patents only) in the context of the KL problem it is designed to solve.
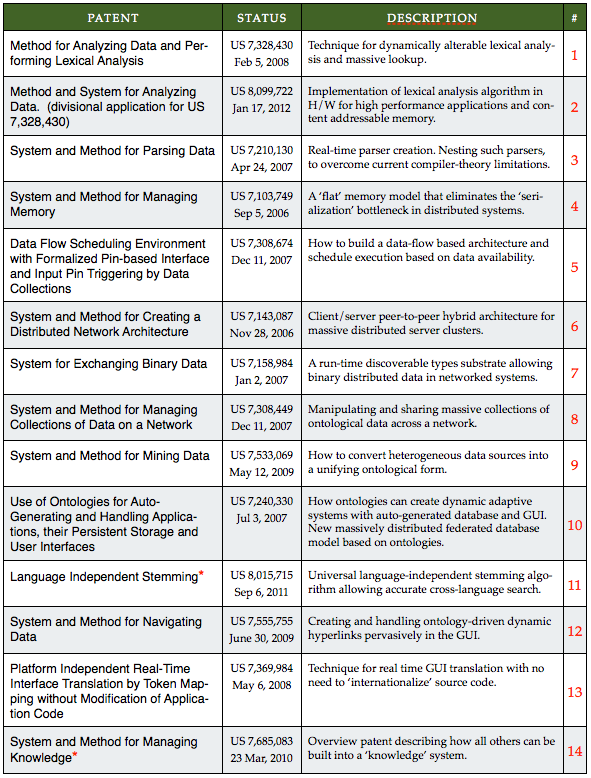 |
| Mitopia® – U.S. Patent Stack (Issued Patents Only) |
#1 & #2 – Dynamic Tokenization & Content Addressable Memory (7,328,430 and 8,099,722)
The Problem(s)
- The single most fundamental operation for a KL system is lookup by name or other identifying tag string. In a general sense this requires “Content Addressable Memory” (CAM). Current approaches use hashing schemes, but these provide no means to get ‘close’, say if a name is slightly misspelt. Nor can hashes directly handle ‘paths’ and hierarchies which are fundamental to organizing ontological data. If the hash lookup fails, you are back where you started. Inverted file indexes that are the basis of the internet, are a form of CAM lookup. The vast majority of all CPU time in KL servers both during search and ingest, is spent in CAM lookup. The situation is similar in KL client code. We need a CAM approach that is as fast as hashing, and preferably one that can also be implemented in hardware for extremely high performance applications.
- Any system attempting to ingest multiple structured and unstructured sources into a unifying ontology is going to have to provide parsers capable of processing each source. Clearly if a system is to be adaptive, these parsers must be created on-the-fly as needed by each source, that is they cannot require a ‘compilation’ in order to support a new source/language. This means that both the parser and the lexical analyzer must be dynamically created and table driven. Current lexical analyzer generators (e.g., LEX) require recompilation and are thus unsuitable for adaptive KL use. We need a dynamic yet fast lexical analyzer. We also need a flexible lexical analyzer for the many other languages that make up a KL system, since the best way to let data drive the code is to create a custom tailored language for each situation. Lexical analysis of all human languages (in UTF-8) must be possible.
The Solution
#3 – Dynamic Parser Creation and Handling Language Ambiguities (7,210,130)
The Problem(s)
- As described above, a KL system requires real-time, compilation-free, dynamic creation and execution of parsers and interpreters, in virtually every operation performed. This is neccesary to allow data to dictate program execution, rather than the other way round. Current parser generators (e.g., YACC) cannot support this. Many sources are ‘binary’ data, not text based, and these too must be parsed, including handling ‘endian’ differences.
- Current parsing technology is limited to LL(1) or LALR(1) languages such as programming languages. To parse real world KL data sources like the web, published CD-ROMs, etc. for conversion into a unifying ontology, requires parsing techniques for semi-structured and unstructured languages that are LL(n) and beyond . Moreover real world sources are context sensitive, which violates a base assumption underlying current compiler theory. Publishers are aware of these limitations, and take advantage of them to prevent loss of their intellectual property through automated mining. Yet these are the sources a KL system needs to ‘learn’ in order to understand others. For these reasons, data mining today is an ad-hoc affair, not based on any formal theory, and so is limited, inflexible, and easily broken by the slightest change in source format. Unfortunately, real world source format formats tend to change on a virtually continuous basis. Unifying divergent sources to extract meaningful content is perhaps the greatest challenge faced today by intelligence agencies. To our knowledge, no system other than Mitopia® has fully solved this problem.
- Many KL sources require the ability to alter or edit the token stream seen by the parser as a direct result of parser operation, but based on logic that may be specific to the source format or current situation. These sources also require dynamic creation of, and subsequent nesting of, dissimilar parsers to handle embedded items within the source (e.g., a mail enclosure) and any mapping from source to target data models. ‘Entanglement’ of these nested parsers, that is where evolution of the ‘inner’ parser can alter the state of the ‘outer’ parser, is essential to handle KL parsing problems. None of these abilities are provided for in current parsing or lexical techniques.
The Solution
#4 – Overcoming the Serialization Bottleneck (7,103,749)
The Problem(s)
- To create complex interlinked structures in support of program logic requires the use of many ‘pointers’ to reference/link one structure to/from the next in memory. Pointers are only valid within a single run of a program, and so complex binary data cannot be sent between processes without first flattening or ‘serializing’ it, and then ‘de-serializing’ into memory at the other end to recreate the equivalent links. Most systems nowadays serialize through XML as the intermediate textual form. Passing through an intermediate textual form represents a huge processing load (approx. 300 times a straight binary exchange) and additional network bandwidth demands as the data expands by a factor of five or more. The serialization load eventually swamps all other CPU usage in a large network of small nodes exchanging lots of complex data, and the expanded textual form can stress network limits. The result is that architectures are forced towards large monolithic servers, exchanging data infrequently via batch processes, combined with completely dissimilar client applications, that must first convert server data before it can be used. Put simply, this problem places an upper limit on the scale of any highly networked system, and the richness of the interconnecting data web. This is the situation in virtually all distributed applications today.
- All complex applications require storage of information to persist beyond the current run of the program. To solve this, the same kind of mapping must occur when data goes between memory and a relational database (‘swizzling’) or file. By many estimates, this conversion glue forms the majority of program code for data-rich applications, and is the principle impediment to changing program logic. The programmer must ‘glue’ the in-memory data model with that of the relational DB (via SQL) or the file-based storage, the bulk of the programming workload. In a large distributed, adaptive system, we must eliminate these serialization transformations caused by differences in memory and file/database programming data models.
- Yet another transformation process must be managed by the programmer between data in memory and it’s visual representation in the GUI. If we are to create a truly adaptive system, we require a powerful and flexible ‘flat’ memory model (i.e., no pointers!), for which it is identical for the programmer to access data in memory, file, database, and to/from the GUI. Links must be valid in all nodes without any data conversion, and such links must be persisted, searched in place, and retrieved, again without any conversion. By eliminating all glue code, and avoiding the huge processing overhead of serialization, we can move to architectures of many smaller, homogeneous nodes, that are simultaneously clients and servers, and which can frequently and pervasively directly exchange complex ‘linked’ binary data as and when required. Only such a substrate could support our technical end goals.
The Solution
#5 – Building a Data-Flow Based Environment & Scheduler (7,308,674)
The Problem(s)
- Software programs today operate on a Control Flow (CF) rather than a Data Flow (DF) paradigm. In CF systems, a program is ‘run’ (directly or indirectly) by a user, it reads input data from one or more sources, performs calculations and/or analysis, and produces new data as output. The ‘code’ is in control, there must be a Master Control Program (MCP) as in the movie ‘Tron‘, to act as traffic cop. In DF systems, programs register with the substrate, and declare to that substrate the ‘kinds’ of data they are interested in, but do not immediately run. It is up to the substrate to cause data to ‘flow’ through the network, and to trigger any programs that are relevant to run as required. Once run, such programs output their data into the same ‘flow’ (where it may become inputs to other programs), and then stop until re-triggered. The ‘data’ and its flow are in control, there is no MCP. In DF the data simply and automatically adapts to whatever network and computing resources are available to it. There are massive benefits to adopting a DF rather than CF approach including adaptability, scaling, reliability, simplicity, modularity, generality, and cost. Unfortunately, implementing true DF systems requires solving most of the problems described in this document, as well as formalizing the ‘laws’ of data flow in a manner that allows the substrate to operate efficiently. Moreover, DF and data-driven approaches are the antithesis of classic Object Oriented Programming (OOP), which now holds center stage in the programming world. For these and other reasons, and despite much interest and hope within academia over the years, few true DF systems have ever been implemented, and so none of the vital benefits of DF have been realized. Programming has advanced very little since the 1960’s as compared with any other ‘technology’. Yet only a DF-based solution can realistically form and scale to be the base of a next generation knowledge-based internet, and so truly “empower” the data.
- Current scheduling techniques are either ad-hoc on a per-application basis, event based, or left to the OS through preemptive or cooperative threading schemes. Unfortunately, none of these techniques is efficient for a system where data flow directly ‘triggers’ appropriate program execution, rather than vice versa. Formalizing the laws of data flow is complex since it is easy to create embraces or other hidden dependency chains that cause compound flow networks to lock up. A theoretically ‘pure’ DF approach cannot be made to work at scale and over a network as there are many subtle accommodations that must be made to keep things rolling robustly.
- Building and programming systems using DF requires a dedicated graphical programming language that embodies and enforces the necessary ‘laws’, and which exposes them to programmer control in order to create links and networks of flow for a given purpose, and to compound those networks to create ever more complex solutions. It is not practical to program DF systems using a conventional text-based programming language. A parallel graphical debugging environment is needed to track and debug network data flow.
The Solution
#6 – Scaleable, Dynamic, Clustered Peer-to-Peer Servers (7,143,087)
The Problem(s)
- Distributed architectures today fall into two main classes: Client/Server (C/S) and Peer-to-Peer (P2P). In C/S approaches a large centralized server, often associated with a relational database, supports queries from a cloud of smaller and dissimilar client machines. In P2P approaches, all nodes tend to be similar, and there is no distinction between client and server. P2P approaches work best in situations without significant query aspects, but where a large volume multimedia data must be shared or many live ‘sources’ must be acquired/streamed. C/S approaches on the other hand work best where there is a formal query ‘language’ and a lot of client query activity, but where there is little or no multimedia involvement or continuous non-query server workload. P2P networks can scale to the very large but have limited application domains. C/S approaches do not scale well as the central server performance becomes the limiting factor. The ability to ‘cluster’ the central server to improve performance is severely hampered by the the relational database paradigm that underlies it, and is difficult or impossible to customize the low level operation of the server.
- To support a global distributed KL system we will need an architecture that combines aspects of both P2P and C/S approaches, and adds additional capabilities that neither supports. The architecture must scale to arbitrary levels both in size of the server clusters and data sets, as well as the number of clients and level of client demands. It must be built from inexpensive non-specialized machines, as in the P2P approach, and yet must support very high levels of query activity from a large client cloud, while also acquiring new data at the servers on a continuous basis. The architecture must support continuous complex monitoring of incoming data to match ‘interest profiles’, and the immediate triggering of interested ‘programs’, wherever they might be on the network (client or server). The architecture must allow dynamic hierarchical server clustering to arbitrary levels, and the automatic migration of server data across the cluster to allow improved query response. It must be capable of handling and streaming large amounts of multimedia data, and must directly support distributed robotic mass storage and automatic archive migration in the petabytes and above range. It must be based only on run-time discovered and binary distributed data, and must allow continuous dynamic reconfiguration of the network topology without a restart. Finally, the architecture must allow plug-in customization/extension of every aspect of both client and server operation through a published API so that system capabilities can be continuously adapted and upgraded.
The Solution
#7 – Run-time Discoverable Types & Binary Data Exchange (7,158,984)
The Problem(s)
- Virtually all software is written in languages where type information is specified and frozen at compile time. This has the advantage of allowing improved error checking by the compiler, but the disadvantage of making the code dramatically less adaptable, generic, and flexible. To change such programs in any way requires a re-compile & build cycle. In a globally distributed KL system engaged in pervasive exchange of binary data, it is difficult or impossible to update the system in a controlled manner, since every node on the network must be updated at essentially the same time. We can therefore rule out the use of compile-time languages as the underpinnings of data discovery or data processing in KL systems, since the data flowing through the system will change format on a continuous basis. We therefore need a run-time discoverable and dynamically alterable type language. This language must be capable of expressing everything possible with a compile-time language (e.g., C) regarding types and structure definitions, and should be binary equivalent; that is a structure definition in C and one in our run-time language should result in identical memory layout. This ensures that data can easily be passed to/from the underlying platform(s) to the system. Since underlying processor architectures use varying byte ordering schemes, this must be transparently handled to allow global binary data exchange. The language must include extensions to describe arbitrary collections of data held in a ‘flat’ data model (see 7,103,749) so that large networks of data and the necessary type definitions can be exchanged without serialization.
- To support KL type discovery and ontology definition, the language must be an Ontology Definition Language (ODL), that is it must provide extensions to describe persistent and non-persistent relationships between the fields of one item and those of another, not just the ‘in-memory’ connections (e.g., pointers) provided by all conventional programming languages. Persistent links can be anything from one-to-one to many-to-many, and the language extensions must support this. Links may have ‘echo’ links in the opposite direction, and this too must be specifiable in the ODL. An ODL must clearly provide inheritance of type fields from ancestral types, as well as allowing arbitrary scripts, annotations, and behaviors to be associated with types and fields.
The Solution
#8 – Manipulating & Sharing Interlinked Binary Data Collections (7,308,449)
The Problem(s)
- Given a mechanism for run-time discovery and manipulation of binary types (7,158,984), a means to ‘flatten’ interlinked collections of data described by those types to avoid serialization (7,103,749), and a means to distribute and retrieve such data from scaleable servers (7,143,087), the next problem we must overcome to create a distributed KL system is: how to describe, access, sort, and search, arbitrary arrangements of such data within trees, stacks, rings, lists, queues, multi-dimensional arrays, etc. while still held and distributed in ‘flat’ form.
- The fields of any data type within a KL system described via the ODL may make both persistent and non-persistent references to other types and records in the local collection or anywhere else within the network. Our aggregation metaphor needs to support this transparently within the single ‘flat’ model that is invariant between memory, file, or server. Data collections in the servers may run into the petabyte or above range, and yet their content (or at least a part thereof) must still be accessible globally across the network even though it cannot be loaded completely into available memory or transmitted over the network.
- The aggregation metaphor must support nesting of data collections within each other either directly or as referenced via a field of a higher level structure. This nesting must be repeatable to arbitrary levels, all while preserving the ‘flat’ memory model allowing direct binary exchange without serialization. Our aggregation metaphor must support arbitrary ‘tagging’ of nodes in collections at any level for various essential purposes, and as with all KL problems, it must be possible through public APIs to modify the behavior of these processes at any level through registered plug-ins and scripts.
- Collaboration on large data sets by multiple users will require a ‘publish’ and ‘subscribe’ mechanism to be built into the aggregation metaphor so that data does not need to be replicated. This will allow different users to simultaneously interact with and view a given data set, either through a shared common UI, or more often through different UIs/portals at the same time.
The Solution
#9 – Adaptive Auto-Generated Data-Driven GUIs, DBs and Query (7,240,330)
The Problem(s)
- All the technologies discussed previously are prerequisites for tackling the ultimate goal of any architecture that is targeted at becoming the underpinnings of next generation knowledge exchange and exploitation, that is how to make such a system rapidly adaptive WITHOUT RE-COMPILE. This must be true despite the inevitability of continuous changes to the system itself, to the ontology(s) that underly it, to the topology of the network it runs on, to the needs and demands of the users, the nature of the data it contains, the evolving standards and formats in the world at large, and many other similar sources of the normally erosive change that eventually bring all systems designed using current approaches to a standstill. To do this, we must at a minimum create an architecture where all data and types are discovered dynamically at run-time, where all GUI is created dynamically and automatically based on the data types to be displayed (i.e., there is no need for the programmer to create a GUI), and where all database storage, querying, indexing, federation, referential integrity, backup and recovery, and topology is handled dynamically and automatically based purely on the data types discovered at run-time. Most importantly, when the describing ontology changes, as it will frequently, all such aspects must automatically update without re-compile, and all persistent data must automatically and transparently migrate to the new format as soon as it is accessed, if not before. Only such a ideal architecture could hope to provide a robust, scaleable, and lasting global KL substrate.
The Solution
#10 – Unifying Data from Diverse Sources by Use of an Ontology (7,533,069)
The Problem(s)
- In a current generation data-extraction script, code works its way through the text trying to recognize delimiting tokens, and once having done so, to extract any text within the delimiters and then assign it to an output data structure. When there is a one-to-one match between source data and target representation, this is a simple and effective strategy, however, as we widen the gap between the two, introduce multiple inconsistent sources, increase the complexity of the source, nest information in the source to multiple levels, cross reference arbitrarily to other items within the source, and distribute and intersperse the information necessary to determine an output item within a source with descriptions of other items, in other words we attempt to ingest an ordinary document intended for a human audience, the situation rapidly becomes completely unmanageable, and vulnerable to the slightest change in source format or target data model. This mismatch is at the heart of all problems involving the need for multiple different systems to intercommunicate meaningful information, and makes conventional attempts to mine such information prohibitively expensive to create and maintain. Much of the most valuable information that might be used to create true KL systems comes from publishers who are not in the least bit interested in making such information available in a form that is susceptible to standard data mining techniques. Publishers deliberately introduce inconsistencies and errors into their data in order both to detect intellectual property rights violations by others, and to make automated extraction virtually impossible.
- The basic issue is that the control-flow based extractor program has no connection to the data itself (which is simply input), and must therefore invest huge amounts of effort extracting and keeping track of ‘state’ in order to know what it should do with information at any given time. The program is intimately tied to a given source. The vast majority useful data is formatted for human understanding, not for computer ingest. When we extend this scenario to hundreds or thousands of dissimilar sources that may contain information about the same people or things, and attempt to ‘understand’ what the totality is telling us by unifying all sources into a single consistent picture, conventional techniques fail completely. Moreover source formats are subject to continuous change, so that no organization has the resources to maintain and update a large set of ‘ingest’ programs. This is the biggest challenge faced by intelligence agencies today, they have spent billions trying to solve it, and have thus far failed utterly. The same challenge is faced by anyone trying to understand some aspect of the world from available ‘reports’, in all cases our only solution today is to have human ‘experts’ read everything and tell us what it means.
The Solution
#11 – Universal Fast, Consistent and Accurate Multilingual Search (8,015,715)
The Problem(s)
- The key problem in text searching and retrieval systems is to maximize the relevance and accuracy of the hits returned in response to a query. This problem is made difficult by the fact that in essentially all languages, words are made up by modifying root words to indicate such things as plurals, tense, verbs, nouns and various other parts of speech. This is most often done by attaching suffixes (e.g., ‘s’ for plural) however languages also use prefixes (e.g., un- as in untrue). Additionally many languages combine words, optionally with connecting infix sequences, to create compound words (e.g., accelerometer – infix ‘o’ which actually means ‘accelerate’ ‘meter’). Stemmers attempt to strip off the affix sequences to obtain the correct root word. Stemming is used pervasively in text search in order to try to improve search accuracy (i.e, a search for teachers should also return hits for teaching, teach, etc.). Current stemming techniques are largely limited to suffix stripping only, and are totally language specific. No existing stemmer can handle irregular forms that are not affix based (e.g., teach and taught). English is the most developed language for stemming purposes with the “Porter” suffix stemmer being the dominant algorithm. Despite this fact, comparison of stemmer results with human ‘meaning’ stemming reveal that the THEORETICAL MAXIMUM ACCURACY of existing suffix stemmers is no more than 35%. For virtually all other languages this figure drops dramatically due to increased use of inflection. This abysmal performance of ALL existing stemmers has led to a continuing debate as to wether they actually improve search accuracy at all.
- Any globally deployed KL system must be able to operate in any and all human languages, and must be able to make connections and query reliably across all languages. Most interesting information appears first in some language other than English, so a system that cannot process and react to this would essentially be ‘deaf’. Non-English languages are usually encoded in UTF-8 which may take a variable number of bytes (from 1 to 6) to encode each character (just one is required for English). This issue cannot be handled with existing stemming algorithms. There is no existing stemming algorithm that is universal and operates across all languages, that maps words into a consistent set of root meanings regardless of language, that has an accuracy close to 100%, that can disambiguate compound words (i.e., the English word “abetalipoproteinemia” should stem to “not beta lipid protein sick”), and is fast. Oh yes, and we want that the algorithm does not have to be re-compiled to handle new languages. If we are to build an effective global KL system, we need such an algorithm otherwise our search and conclusions will be horribly flawed.
The Solution
#12 – Creating a User-Centric Pervasive Hyperlink Environment (7,555,755)
The Problem(s)
- Hyperlinks today are static URL references that are placed there by the creator of a web page in order to direct the users attention to some other page or site, often the motive for the hyperlink has less to do with improving understanding than it does to furthering the objectives of the site’s owners. This phenomenon is responsible for the well known problem of setting out to find some answer on the web and being derailed or loosing track, so that after a while the user cannot even remember what they were originally looking for. The problem is that hyperlinks should also be dynamically created by the KL knowledge base of the user (or his/her organization) in any text anywhere that appears in the user’s GUI, without the need to alter the site or text source to do so. Of course this should apply in all world languages. In this way, the user can browse information while carrying around and referencing his/her own context. This enhances and annotates what is seen, improves the ability to remain focussed, and provides an essential cross check to confirm truth and accuracy.
The Solution
 |
|
GUI element with ‘Country’ hyperlinking turned on
|
#13 – Implementing a Multilingual GUI without Code Localization (7,369,984)
The Problem(s)
- The process of ‘localizing’ a software application (i.e., changing it to display its user interface in another language other than English) has historically been a very expensive and time-consuming business. So much so that the majority of software programs are never localized to any other language. An industry has sprung up to try to help companies localize their software by providing localization experts and target language speakers. These services too are expensive, and require release of company source code to others. In the last few years, the operating system manufacturers and programming language designers have made some steps towards trying to alleviate these problems. In all such cases, the basic approach is to have all user interface strings come from a ‘resource’ that is loaded from a different location depending on what language is being used by the program. In this way, as long as the programmer always obtains text from this source through the mechanism provided, the code written should operate equally well in another language providing all the corresponding resources are available in that language. This approach, while an improvement over the previous situation, still has many shortcomings. Firstly it forces all code to be written from the outset with localization in mind, the programmer is no longer free to simply add or alter the text content of the user interface and certainly cannot use a string constant (e.g., “Hello World”) in the program source though this is the natural tendency, and will in fact happen regardless of localization policies. The result of this approach to localization is that the program becomes unreadable, since it is very difficult to see by examining the code what is being ‘said’. Another problem with this approach is its inability to handle variable strings (i.e, those where a portion of the string, the time for example, varies while the rest is constant) smoothly. Yet another negative in this approach, regardless of the particular flavor (since all are basically similar), is that when strings are read back from the user interface elements (e.g., the name of a button), they can not longer be assumed to be in English and thus code that manipulates the UI cannot perform simple operations like checking if the button name is “OK” but must instead find a localization agnostic way to achieve this simple operation. The end result of all these shortcomings is that designing a program for localization takes a lot of work and discipline, makes the code base obscure, non-adaptive, and highly dependent on the localization metaphor, and denies to programmers the simplifying model that their application is running only in English. What is needed then is another approach to localization that does not require any special calls from the programmer, does not deny the use of simple English string constants, is platform and language independent, and maintains the ability to read back English from the elements of the UI
The Solution
#14 – Assembling all the Components into a Knowledge Level System (7,685,083)
The Problem(s)
- There are of course a large number of other problems that must be solved to create a working KL system, not the least being how to assemble all the fundamentally necessary technologies described above into a unified KL system. There are simply too many issues to list here.
The Solution
 |
|
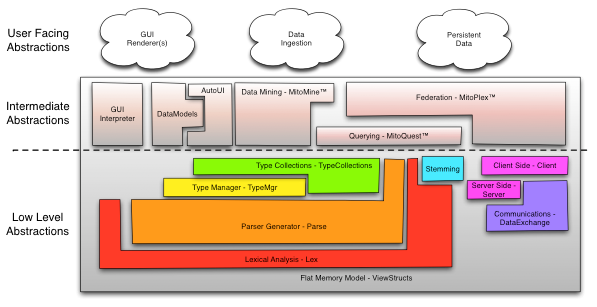
A portion of the Mitopia® software architecture showing key patented technologies
|