
 In an earlier post we introduced Mitopia’s parser abstraction and the associated tools to allow rapid creation of custom languages and parsers capable of handling grammars far beyond the LL(1) grammars associated with conventional parser generators and programming languages. A key ability of the Mitopia® parser abstraction is the dynamic nature of the generated parsers, that is they are generated as needed on the fly to solve a given situation. Such rapid dynamic generation of arbitrary language parsers is simply not possible with current parser generators. One key aspect of Mitopia’s extended BNF is the provision for including ‘plugin’ meta-symbols (of the form <@n:m>) within the BNF, and for executing the corresponding registered ‘plugin’ function whenever the corresponding meta-symbol is exposed on the top of the parser stack. In discussing ‘plugin’ operation earlier, we alluded to the fact that the full syntax of a ‘plugin’ meta-symbol includes an optional ‘hint text’ value that follows the basic “@n:m” portion as in <@n:m:Arbitrary Text>. While we explained how the ‘hint’ is passed to the ‘plugin’ function as an additional parameter to describe the context of the invocation, we essentially glossed over the full potential of this ‘hint’ text parameter to unleash an expressive power far beyond current programming language metaphors (see “Shuffling the deck chairs” post). Among other things, this parser technology underlies the operation of Mitopia’s data integration/mining technology MitoMine™ which we introduced in the previous post. And accordingly, we must now explore this programming language revolution in more detail before further discussing other Mitopia® abstractions built upon in.
In an earlier post we introduced Mitopia’s parser abstraction and the associated tools to allow rapid creation of custom languages and parsers capable of handling grammars far beyond the LL(1) grammars associated with conventional parser generators and programming languages. A key ability of the Mitopia® parser abstraction is the dynamic nature of the generated parsers, that is they are generated as needed on the fly to solve a given situation. Such rapid dynamic generation of arbitrary language parsers is simply not possible with current parser generators. One key aspect of Mitopia’s extended BNF is the provision for including ‘plugin’ meta-symbols (of the form <@n:m>) within the BNF, and for executing the corresponding registered ‘plugin’ function whenever the corresponding meta-symbol is exposed on the top of the parser stack. In discussing ‘plugin’ operation earlier, we alluded to the fact that the full syntax of a ‘plugin’ meta-symbol includes an optional ‘hint text’ value that follows the basic “@n:m” portion as in <@n:m:Arbitrary Text>. While we explained how the ‘hint’ is passed to the ‘plugin’ function as an additional parameter to describe the context of the invocation, we essentially glossed over the full potential of this ‘hint’ text parameter to unleash an expressive power far beyond current programming language metaphors (see “Shuffling the deck chairs” post). Among other things, this parser technology underlies the operation of Mitopia’s data integration/mining technology MitoMine™ which we introduced in the previous post. And accordingly, we must now explore this programming language revolution in more detail before further discussing other Mitopia® abstractions built upon in.
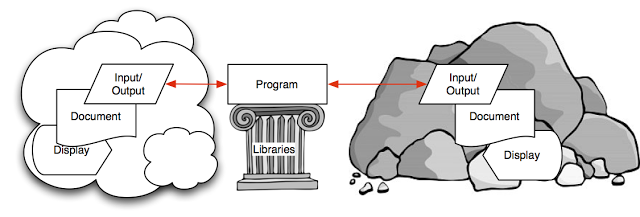 When seeking to replace Mitopia’s earlier data ingestion front end with a more dynamic and efficient method based on Mitopia’s parser abstraction, it became clear that by using this plugin ‘hint’ text as a series of program statements to be executed within an inner nested parser having a language tied intimately to the system’s ontology (i.e., the Carmot-E language), it would become relatively simple, comparatively speaking, to make the mapping from the taxonomy of external sources to/from Mitopia’s internal ontology. This technique rapidly evolved into the MitoMine™ technology which may be the ultimate expression of this concept, but, once started down this path, it also became clear that the same technique of nested parsers and using the ‘plugin’ meta-symbols to pass information and instructions from the outer parser to the inner parser, could be used to solve a wide variety of ‘impedance mismatch’ type problems all over the Mitopia® code base. Moreover, it transpired that it is not necessary that the nested parser language be tied to the system ontology, it could be tied directly to any other language, perhaps one that is not part of Mitopia® such as an existing programming language. What followed was a multi-year process of converting all such problem areas over to the new technique. In all such cases the result was a great simplification of the code base, and an even greater increase in capabilities and adaptability. The fact that parsers are so easy to create, and that it is a trivial matter to nest one parser within another (to any number of levels!) through the ‘plugin’ architecture, makes Mitopia’s parser abstraction a key component in creating what we now refer to as heteromorphic languages. Heteromorphic languages have an expressive power and a productivity benefit that is unprecedented compared to any programming metaphor to date. After exposure to and use of this technique, people often begin to question why one would ever do things any other way. The diagram above is a generalized picture of what most programmers spend their time doing, the problem is always one of matching impedance between building blocks and a particular application. The patented Mitopia® concept of heteromorphic languages directly address this in a way other programming metaphors cannot.
When seeking to replace Mitopia’s earlier data ingestion front end with a more dynamic and efficient method based on Mitopia’s parser abstraction, it became clear that by using this plugin ‘hint’ text as a series of program statements to be executed within an inner nested parser having a language tied intimately to the system’s ontology (i.e., the Carmot-E language), it would become relatively simple, comparatively speaking, to make the mapping from the taxonomy of external sources to/from Mitopia’s internal ontology. This technique rapidly evolved into the MitoMine™ technology which may be the ultimate expression of this concept, but, once started down this path, it also became clear that the same technique of nested parsers and using the ‘plugin’ meta-symbols to pass information and instructions from the outer parser to the inner parser, could be used to solve a wide variety of ‘impedance mismatch’ type problems all over the Mitopia® code base. Moreover, it transpired that it is not necessary that the nested parser language be tied to the system ontology, it could be tied directly to any other language, perhaps one that is not part of Mitopia® such as an existing programming language. What followed was a multi-year process of converting all such problem areas over to the new technique. In all such cases the result was a great simplification of the code base, and an even greater increase in capabilities and adaptability. The fact that parsers are so easy to create, and that it is a trivial matter to nest one parser within another (to any number of levels!) through the ‘plugin’ architecture, makes Mitopia’s parser abstraction a key component in creating what we now refer to as heteromorphic languages. Heteromorphic languages have an expressive power and a productivity benefit that is unprecedented compared to any programming metaphor to date. After exposure to and use of this technique, people often begin to question why one would ever do things any other way. The diagram above is a generalized picture of what most programmers spend their time doing, the problem is always one of matching impedance between building blocks and a particular application. The patented Mitopia® concept of heteromorphic languages directly address this in a way other programming metaphors cannot.

 In any abstraction built on Mitopia’s heteromorphic language architecture, nested parsers are required. The outer parser language is configured to exactly match and parse the syntax of the left hand side of our programming diagram above, the inner parser invoked through the plugin ‘hint’ instructions/programs is tied intimately to the paradigm and/or syntax of the right hand side of our diagram. This creates a ‘two-level’ or heteromorphic language in which the evolution of the outer parser state results in the execution of statements in a different language within an inner parser, such that the order of execution of the statements in the inner parser is determined by the outer parser ‘flow’, and not by the order in which the statements are written. We refer to the outer language as the ectomorphic language while the inner parser language is referred to as the endomorphic language. The combination of the two languages within nested parsers becomes a heteromorphic language. We can now give definitions of a homomorphic and heteromorphic languages as follows:
In any abstraction built on Mitopia’s heteromorphic language architecture, nested parsers are required. The outer parser language is configured to exactly match and parse the syntax of the left hand side of our programming diagram above, the inner parser invoked through the plugin ‘hint’ instructions/programs is tied intimately to the paradigm and/or syntax of the right hand side of our diagram. This creates a ‘two-level’ or heteromorphic language in which the evolution of the outer parser state results in the execution of statements in a different language within an inner parser, such that the order of execution of the statements in the inner parser is determined by the outer parser ‘flow’, and not by the order in which the statements are written. We refer to the outer language as the ectomorphic language while the inner parser language is referred to as the endomorphic language. The combination of the two languages within nested parsers becomes a heteromorphic language. We can now give definitions of a homomorphic and heteromorphic languages as follows:
A Homomorphic Language is one having a single fixed language grammar such that the order of execution of statements in that grammar is determined solely by the arrangement and order of statements for any given program written in that grammar.
A Heteromorphic Language exists within two or more nested parsers where the outer parser language (the Ectomorphic Language) matches and parses the syntax of a specific external ‘source’ so that at points designated by the ectomorphic language specification, the outer parser grammar invokes one or more inner parsers conforming to the syntax of an Endomorphic Language(s), passing it program statements written in the endomorphic language(s), such that the order of execution of statements in the endomorphic language(s) is determined predominantly by the ‘flow’ of the outer parser (as determined by the external ‘source’ content and the ectomorphic language specification). Endomorphic language statements may obtain that portion of the ‘source’ text just ‘accepted’ by the ectomorphic parser as a parameter. The endomorphic language(s) is tied to a specific functional environment and/or purpose (in order to do something useful) through custom code registered with, and wrapping, the parsers. It is this combination that creates a heteromorphic language ‘suite’. Either the ectomorphic or the endomorphic language may take multiple distinct forms depending on the required functionality. These pairings of many variants of one language with a single form of the other(s) form a ‘suite’. All such pairings are deemed instances or variants of a given heteromorphic language suite.
 So homomorphic languages basically include all existing programming languages regardless of ‘paradigm’. By contrast, heteromorphic languages embed the endomorphic language statements directly within the ectomorphic grammar so that they execute in an order determined by the outer parser evolution. Lets pause for a bit to think about what we have just said here. We have just defined a programming language where the order of execution of statements is determined by the actual data content of an external ‘source’ and not by the program itself! Such a thing is heresy! It goes against the most fundamental assumption of computer programming which is that the program is in control, and it alone determines the statements it executes in response to its input. For programmers that have many years of experience with conventional programming languages, this leap of giving up control flow to the external data can be too much to swallow. Experience over the years at MitoSystems has shown that the more programming experience people have, the harder it is for them to adapt to this new paradigm.
So homomorphic languages basically include all existing programming languages regardless of ‘paradigm’. By contrast, heteromorphic languages embed the endomorphic language statements directly within the ectomorphic grammar so that they execute in an order determined by the outer parser evolution. Lets pause for a bit to think about what we have just said here. We have just defined a programming language where the order of execution of statements is determined by the actual data content of an external ‘source’ and not by the program itself! Such a thing is heresy! It goes against the most fundamental assumption of computer programming which is that the program is in control, and it alone determines the statements it executes in response to its input. For programmers that have many years of experience with conventional programming languages, this leap of giving up control flow to the external data can be too much to swallow. Experience over the years at MitoSystems has shown that the more programming experience people have, the harder it is for them to adapt to this new paradigm.
We use the word ‘source’ here in the generic sense to mean whatever is on the left side of our generic programming diagram given above. The ‘source’ need not be a document, it could be a user or indeed any external system or set of systems. Also, this new concept of heteromorphic languages is not predicated on the fact that the right hand side of our programming diagram is Mitopia®. The heteromorphic language approach is a general technique requiring only a parsing abstraction similar to that detailed in this document. Either the endomorphic or ectomorphic languages could be any existing standard programming language, so that this technique can bring huge advantages in productivity and expressiveness even to existing programming languages. A number of Mitopia® patents cover the heteromorphic language concept.
The power of the heteromorphic technique comes from the fact that because the outer parser ‘state’ is driving the execution of statements in the inner parser, there is little need for the ‘program’ involved in making the mapping between the two dissimilar formats on either side to maintain any concept of the current state of what it is doing. The program is told what to do by the ‘source’ content and all the ‘state’ information is implicitly stored in the outer parser state, so that a statement in the endomorphic language will only execute when it is appropriate for it to execute given the source content. The endomorphic program statements become ‘stateless’, their state is determined by the parser production in the ectomorphic language where they reside.
 Any programmer that has tried to bridge a gap between two ‘formats’ knows that most of the programming work involved is simply keeping track of where one is within the source, and what has gone before, in order to know what the ‘state’ is and what should be done next. With the heteromorphic language technique virtually all of the housekeeping work (and the associated conditional logic it implies) fades away (into the outer parser state) leaving a simple set of statements that execute only when the source content dictates that they should. This simplification that this yields for the programmer is difficult to over-stress. The price that must be paid for this simplification is the need to understand compiler theory (see here and here), and a willingness to abandon a fundamental tenet of computer programming that is ‘a program has control of its own program flow’.
Any programmer that has tried to bridge a gap between two ‘formats’ knows that most of the programming work involved is simply keeping track of where one is within the source, and what has gone before, in order to know what the ‘state’ is and what should be done next. With the heteromorphic language technique virtually all of the housekeeping work (and the associated conditional logic it implies) fades away (into the outer parser state) leaving a simple set of statements that execute only when the source content dictates that they should. This simplification that this yields for the programmer is difficult to over-stress. The price that must be paid for this simplification is the need to understand compiler theory (see here and here), and a willingness to abandon a fundamental tenet of computer programming that is ‘a program has control of its own program flow’.
In retrospect, arriving at the heteromorphic language approach was perhaps inevitable since it is entirely consistent with the fundamental Mitopia® philosophy which is based on letting data express itself, rather than forcing it into submission through code and control flow. This same philosophy lead to the fact that Mitopia® is a data-flow based system so that code executes when matching data arrives, not the other way round. Similarly, Mitopia® is based on the run-time discovery of the system ontology which is then leveraged to dynamically create and manage the system ‘database’, to perform analysis, and to construct and drive the user interface. Once again the data drives the code, not the other way round. Looked at in this context then, heteromorphic languages are simply one more example of yielding up ‘control’ to the data in order to gain the massive benefits that this abdication of ‘control’ can yield.
 In a 2004 paper entitled “What is Killing the Intelligence Dinosaurs?” I addressed this programmer productivity issue in great detail, and the gave the reasons why rigid and non-adaptive systems and poor programmer productivity are crippling the decision cycles (or OODA loops) of any organization tasked with ‘understanding’ what is going on in the outside world, given that the outside world and its formats and assumptions are changing continuously. Intelligence agencies are of course the most afflicted by this problem, and yet to this date they have still failed to come to terms with the underlying causes of their problems. In this document I calculated the programming effort required just to keep track of on-going changes to existing public formats such as those governed by the ISO standards (approximately 1 changed standard every 1.7 days). The analysis showed that using current programming techniques, keeping up with these changes is a practical impossibility regardless of resources, whereas using heteromorphic language techniques (like MitoMine™) it is quite manageable. This clearly illustrates on the largest scale the significance of the techniques we are discussing here. However, we will not repeat all this analysis herein.
In a 2004 paper entitled “What is Killing the Intelligence Dinosaurs?” I addressed this programmer productivity issue in great detail, and the gave the reasons why rigid and non-adaptive systems and poor programmer productivity are crippling the decision cycles (or OODA loops) of any organization tasked with ‘understanding’ what is going on in the outside world, given that the outside world and its formats and assumptions are changing continuously. Intelligence agencies are of course the most afflicted by this problem, and yet to this date they have still failed to come to terms with the underlying causes of their problems. In this document I calculated the programming effort required just to keep track of on-going changes to existing public formats such as those governed by the ISO standards (approximately 1 changed standard every 1.7 days). The analysis showed that using current programming techniques, keeping up with these changes is a practical impossibility regardless of resources, whereas using heteromorphic language techniques (like MitoMine™) it is quite manageable. This clearly illustrates on the largest scale the significance of the techniques we are discussing here. However, we will not repeat all this analysis herein.
To illustrate how a heteromorphic language works, we will use a series of trivial examples using MitoMine™ which is just one of the Mitopia® built-in heteromorphic language suites that use Carmot-E (see below) as the endomorphic language and environment. First let us assume we want to create a program to count the number of occurrences of a specific person’s name within any document. Short of ‘hello world’, one of the simplest non-trivial programs to write in any language. Note that this is a problem that is totally independent of the current ontology or any need to convert to it, and so serves to illustrate the power and simplification conferred for ANY programming task (over homomorphic languages), simply by using ectomorphic parser state to track program ‘state’, and execute just the code required in the endomorphic language. In a standard homomorphic language (e.g., C) a solution to this might look something like the following (excluding the code it takes to load up the file etc.):

The function StrstrNC() is needed because we want to recognize the name regardless of case (see kNoCaseKeywords for the heterogeneous version below), otherwise we could use the standard library function strstr(). The function CountOccurences() simply calls NextOccurrence() in a loop passing it the current pointer within the file string (which it updates on exit to point past any match found), and the name string to be matched. A very simple program to be sure, and yet it still required 30-40 lines of code because of the case insensitive requirement and the need to track state after each call.
In a heterogeneous language (e.g, MitoMine™) the program is just 7 lines as follows (see here for explanation of the BNF, here for the lexical spec.):


The lexical analyzer specification above is trivial (see here for more explanation) and contains one line defining the name we’re looking for (token 128 in the ectomorphic language) and a range specifier that will accept anything else as a mere string (token 1 in the ectomorphic language). Now to parse the file and count occurrences of a name, we see that the grammar simply treats the file as a series of ‘chunks’ which can either be:
- The name we’re looking for – which triggers the ‘is_a_name‘ production which invokes the endomorphic statement “$a = $a + 1” to increment our occurrence count register $a.
- Any other text – which is simply ignored (endomorphically – see the text_sequence production).
When the program reaches the end of file, the total occurrences of the name of interest is printed using the $ConsoleMessage() function. That is it, the entire program! Note that even in such a trivial example, the need to track our state (which we did in the C example using the ‘state‘ variable and our NextWord() subroutine) is gone completely – if we are supposed to increment our counter because there has been a match, we know that the appropriate endomorphic statement will be popped off the ectomorphic parser stack and executed, there is absolutely no need for the endomorphic program to concern itself with state. The ectomorphic parser does all the work for us; the endomorphic code does nothing but bump a counter! Note also that unlike the homomorphic implementation, we do not need to use any library function in the heteromorphic case to do the actual counting operations.
But the real test of programmer productivity comes when we change the requirements on the program and see what the impact is. First lets add the very logical next requirement that the program must be able to recognize all of the names in a list of different names. In the heterogeneous case, this makes no difference whatsoever to the BNF, we simply modify the lex specification to add additional names, all of which are mapped to the same token (128) viz:

In the homogeneous case, we have two choices:
We could (1) modify CountOccurrences() to scan the text multiple times, each time using the next name in a list of comma separated names passed as a parameter. Alternatively we could (2) pass the comma separated list down into NextOccurrence() and add logic in there to iterate through the list calling StrstrNC() for each name using the saved previous state and track which name (if any) returns the earliest match in the string, once complete, the earliest match (if any) is used to update the state for the next pass through the outer loop. In either case the amount of code in our homogeneous program would blossom considerably and the opportunity for bugs would grow proportionally.
Now lets mix it up a bit. Lets add the simple requirement that we have two lists of names, one for the good guys and one for the bad guys and we want to see for any given document if more good guys than bad are mentioned.
In the homogeneous case, if we’d picked option (2), now we’d add a loop within CountOccurrences() over the good guy list and then again over to bad guy list and compare the totals for each loop to determine the answer. If we’d picked option (1), we’d probably have to re-write our code to use option (2) and then modify it in the same way – a lot of work, maybe up around 50-60 lines by now. Realize also that we are now looping calling strstr() many times on what could potentially be a very large document. Performance of such a simplistic approach is likely to be very poor. In the heterogeneous case, we now need to modify our BNF and LXS specifications slightly as follows:


Our heterogeneous ‘program’ is now just 9 lines long because once again we have used the ectomorphic parser state to do all the heavy lifting. We make all good guy names be token 128, and all bad guy names (i.e., the Flintstones) be token 129, then we simply bump the counter in the is_a_goodguy production and decrement it in the is_a_badguy one. Thats it!
Ok, lets keep going with this example and suppose we now want to get a simple measure of how ‘relevant’ a document is as far as good guys and/or bad guys. We could parametrize this by dividing the number of good guy/bad guy occurrences by total number of other words in the document. If we were scanning many documents, we could then sort by this (real number) measure to arrange them by our simple ‘relevance’.
However we implemented the homogeneous program we are now stuffed! There was a basic assumption in our implementation that the program could ignore the text in between matches and that we could leverage the standard library strstr() approach to simplify things. That is no longer true, we must now convert our program to scanning word by word, and counting as we go, while simultaneously mixing in our logic for checking at each and every extracted word boundary if we have a match (and remember a match involves multiple words for a person’s name). That is going to be a very messy and complicated piece of code, probably a hundred or so lines long, and even if possible in less, it would be totally rewritten from our previous version to meet this new requirement.
In the heterogenous approach, our LXS specification is unchanged, but we must modify our BNF as follows:
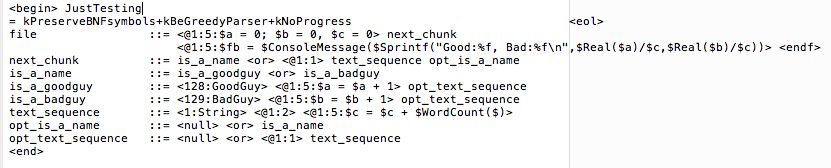
We are now up to a grand total of 10 lines! We now keep separate counters (in registers $a and $b) for good guy and bad guy matches, and a third counter in $c for the number of words in any other text encountered. Then in the text_sequence production, we no longer endomorphically ignore the non-matched text, but instead we add the word count within each chunk to our counter $c using the library function $WordCount(). The final $Sprintf() statement is modified accordingly. Once again, that is all we have to do, and remember these parsers and scripts are constructed dynamically and so no recompile and re-build of our application is necessary, we simply change the script as shown and it immediately replaces what we had before. Maybe 2 minutes to make all the changes and be running again, and our ‘application’ never stopped running in the mean time. Now that is real productivity! You might think I cherry picked my example, but actually this example leverages heteromorphic power very little as we shall see later.
 For those interested in a little computer science history, compare the approach above to that used by D.L. Parnas in his seminal work on abstraction entitled “On the criteria to be used in decomposing systems into modules” (Comms. ACM Dec. 1972). If you have not read this paper, I strongly recommend doing so (see here). You will see that while Parnas showed increased robustness and adaptability could be achieved by careful design of the homomorphic program, this new heteromorphic approach has the potential to take things to an entirely new level, particularly in light of the additional concepts introduced in my next post.
For those interested in a little computer science history, compare the approach above to that used by D.L. Parnas in his seminal work on abstraction entitled “On the criteria to be used in decomposing systems into modules” (Comms. ACM Dec. 1972). If you have not read this paper, I strongly recommend doing so (see here). You will see that while Parnas showed increased robustness and adaptability could be achieved by careful design of the homomorphic program, this new heteromorphic approach has the potential to take things to an entirely new level, particularly in light of the additional concepts introduced in my next post.
Although MitoMine™ was used in this example, do not be fooled into thinking that heteromorphic languages are limited in any way to mining data. In the examples above we didn’t even use the endomorphic ‘ontology’, this was simply a standard programming exercise, and even so, we can see improvements in productivity and adaptability for our trivial example that are orders of magnitude; a thing unheard of in any standard programming metaphor. We kept things simple like this merely to emphasize the point, that heteromorphic languages can be applied to anything, and still yield massive improvements. However, once one unleashes the full power of the technique by leveraging a tie-in to an internal endomorphic ontology, further orders of magnitude improvement result so that any comparison with standard approaches or languages becomes ridiculous. We will demonstrate this in later posts.
Within Mitopia®, heteromorphic languages are used to bridge any ‘cognitive’ gap where the assumptions on one side to not directly match those on the other. These applications include not only dealing with outside sources and systems, but also for situations completely internal to the Mitopia® code base where dissonance must be tamed. The heteromorphic approach is applicable to any dissonant situation, there does not have to be what one might think of as a conventional ‘source’ on one side, in fact in some applications (e.g., syntax driven UI), the ‘source’ for one heteromorphic suite (i.e., database queries, itself 3 or more heteromorphic suites – 1 client side, 1 server side, plus the distributed MitoPlex™/MitoQuest™ federation) is actually constructed by another heteromorphic suite (query building) by driving a third such suite (Mitopia’s GUI interpreter layer) to interact with the user.
The end result is greatly reduced ‘compiled’ code to make these kinds of internal connections since they are all mediated through parsers. The languages can be trivially changed to accommodate changing realities, and new and improved components can easily replace/coexist with other ones since the only connections occur through the parser languages, not through compiled and hard linked function calls. We can easily (and indeed dynamically) substitute alternate implementations across any parser/parser boundary without the other side being aware that it has happened. This approach makes the entire Mitopia® environment ‘adaptive’ at all levels resulting in the ability to rapidly accomplish new projects in time frames that would otherwise be inconceivable. Heteromorphic language technology plays a large part in making such adaptability possible.