 |
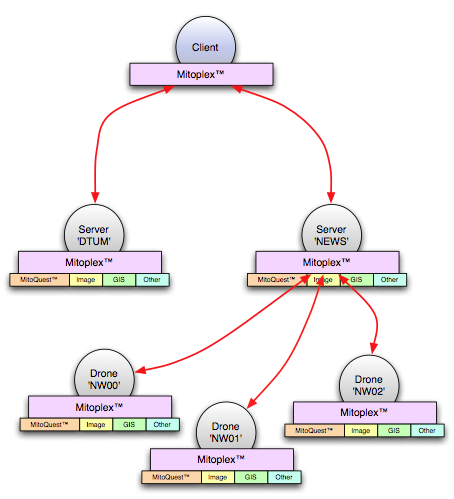
| Fig. 1 – A simple MitoPlex™ federated database/server network |
In this post I want to discuss how Mitopia’s federated database/server architecture, known as MitoPlex™ is tied to and driven off the Carmot ontology for the system and introduce some of the resultant benefits. The figure above illustrates the basic form of a simple networked MitoPlex™ federated database/server network. Every machine in the network is running an identical and complete copy of the Mitopia® application. This includes both the clients and the servers which are thus indistinguishable from an executable perspective. The MitoPlex™ abstraction allows a number of container specific plugins to be registered. Primary among these registered plugins in MitoQuest™ which is responsible for implementing the bulk of actual server logic and queries. We will discuss MitoQuest™ in later posts. Each container plugin generally handles a unique storage file format on the server disk(s), for example specialized knowledge is required to interpret and search images and this might be encapsulated within the ‘Image‘ plugin. This allows easy substitution and modification of any plugin without impacting the overall architecture. Any server may be comprised of a hierarchical tree of ‘drones’ (as in the ‘NEWS‘ case above) in order to form a cluster. Clusters may be physically distributed, perhaps globally since members communicate through IP traffic.
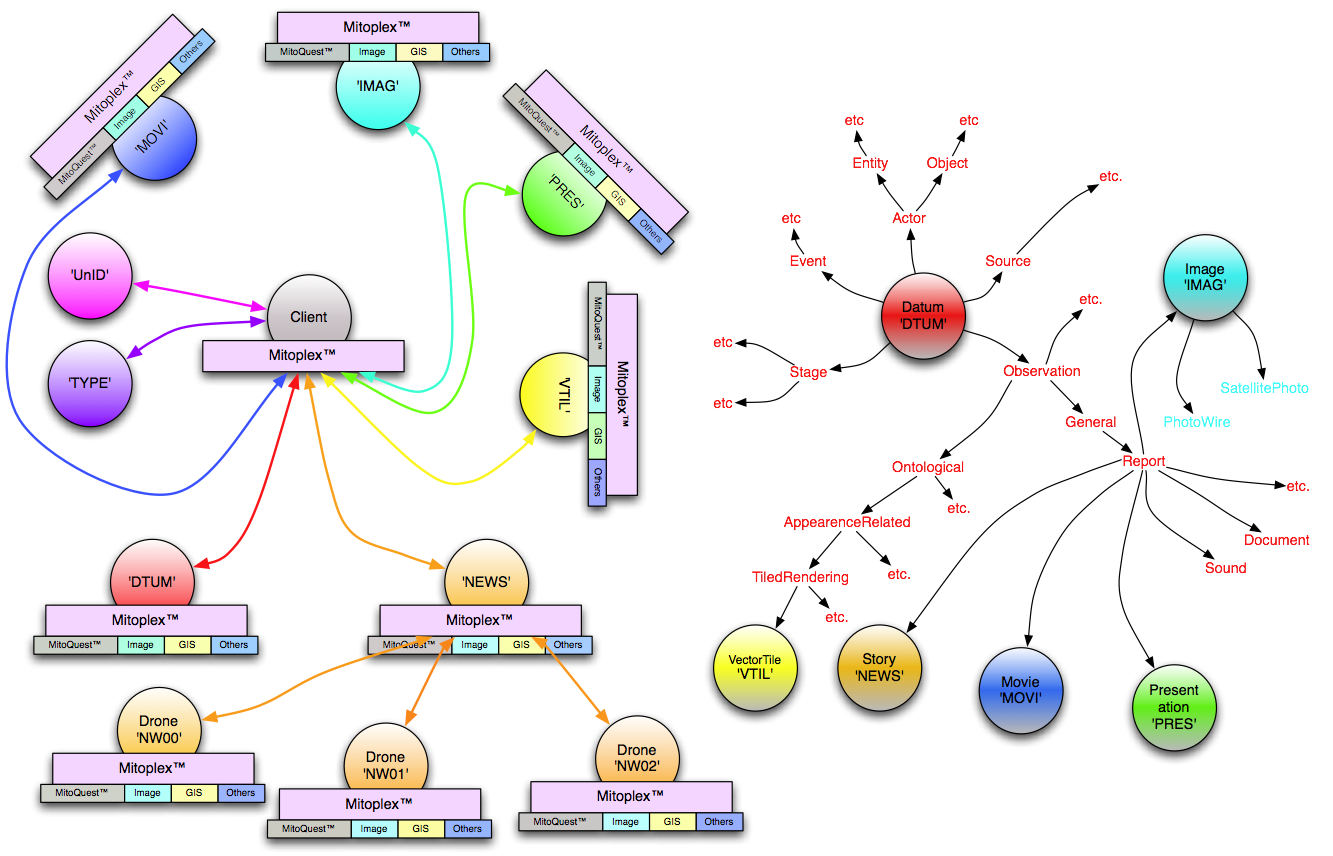 |
| Fig. 2 – MitoPlex™ federation relationship to type hierarchy (click to enlarge) |
The MitoPlex™ abstraction layer is responsible for providing all communications between clients and servers, as well as within and between servers and server clusters. The topology of the server arrangement on the network is determined by MitoPlex™ at runtime and is tied to the
Carmot ontology (i.e., type hierarchy) for the system itself. In fact in any realistic configuration, there are a number of additional multimedia-related servers required in order for the system to provide full functionality. Figure 2 above shows the complete server topology for the simple case, alongside a high level view of the relevant portions of the ontology. Both areas of the diagram are color coded to illustrate the communications paths and ontological types that relate to (i.e., are persisted in and handled by) each of the servers present in the system concerned. This kind of topology is not uncommon where system server arrangement is driven by the need for specialized multimedia behaviors. As you can see from the figure, the overwhelming bulk of the types in the ontology do not involve multimedia data and are handled directly by the
Datum server which is the root/catchall server for all persistent data (illustrated in red in the diagram). The bulk of the other servers can be found below the type
Report which is itself derived from
Observation. This is common in that many systems have vastly more bulky data in the
Observation path of the ontology than they do in the other branches, and multimedia is by its nature located somewhere within the
Observation branch of the ontology tree. Note that the drone types of the ‘
NEWS’ server are not visible from or represented in the types hierarchy, they are an artifact of MitoPlex™ clustering and discoverable only through internal MitoPlex™ logic from the ontological type
Story’s master server key data-type ‘
NEWS’.
Referring to Figure 2, we can now explain how MitoPlex™ routes commands, queries, and new data to be persisted. When a user issues a query for a given type ‘A’, the MitoPlex™ layer computes the closest ancestral type for which there is a key data-type defined in the Carmot ontology, and which has a server defined in the server topology ‘X’ (which might of course be the same as ‘A’). As you can see in the illustrated topology/ontology, queries for most types in the ontology will finish up getting routed to the ‘DTUM’ server. If however the user were to issue a query on the type Story, the MitoPlex™ layer will route the query to the ‘NEWS’ server to execute. Because this particular configuration has defined the ‘NEWS’ server to be a cluster, the MitoPlex™ layer in that server automatically sends a copy of the query to each drone in the cluster. The result would be that the MitoPlex™ layer in the ‘NEWS’ server receives three replies, each containing different query hit lists to reflect the results obtained in each drone (whose news story content is of course distinct from each of the other drones). The MitoPlex™ layer then combines the three hit lists as necessary to obtain the final result which is then returned to the client. In the case of a non-clustered server (e.g., ‘IMAG’ in this example), the master server directly executes the query and returns the resultant hit list to the client. The reception and reassembly of hit lists in the master happens in parallel, and does not significantly burden the master server, which must remain maximally responsive to new query requests. From the client query perspective, the fact that a server is clustered is invisible.
The query routing description above was predicated on the fact that the user’s query concerned a single ontological type (e.g, Story), however as we will see later, queries by default apply to the type specified and all descendant types. Indeed with the simple Query Builder interface, there is no way in the GUI to specify a non-recursive query. This means that if for example the user were to specify a query such as “Find all items of type Report (and descendants) where the name contains ‘Iraq’”, we can see that the MitoPlex™ layer in the client must issue the query not only to ‘DTUM’, but also ‘NEWS’, ‘IMAG’, ‘MOVI’ and ‘PRES’ in the topology of the example. The server ‘VTIL’ is not involved in this query because it belongs on another branch of the ontological tree. The client MitoPlex™ layer code in this case will receive separate replies from each master server type. In this case, the Client side MitoPlex™ layer is responsible for receiving (in parallel) and combining the replies from all servers involved and returning the combined results to the higher level calling code.
The same strategy of re-assembling results of other command types (e.g., fetch records corresponding to a hit list) is used for most command types within clustered servers. An exception to this rule occurs when the results for a given command come entirely from one drone of the cluster (e.g., fetch associated multimedia file). In this case the command is routed by the master to the drone, and the reply address is set up to be the client. This results in the response coming directly from the drone to the client MitoPlex™ layer. This approach significantly reduces the burden of multimedia data handling on the master which is critical to ensure that it is maximally responsive to new client requests should they arrive.
The next issue is: what happens to newly ingested heterogeneous collections of ontological items resulting from ingest processes such as MitoMine™ or manual data entry?
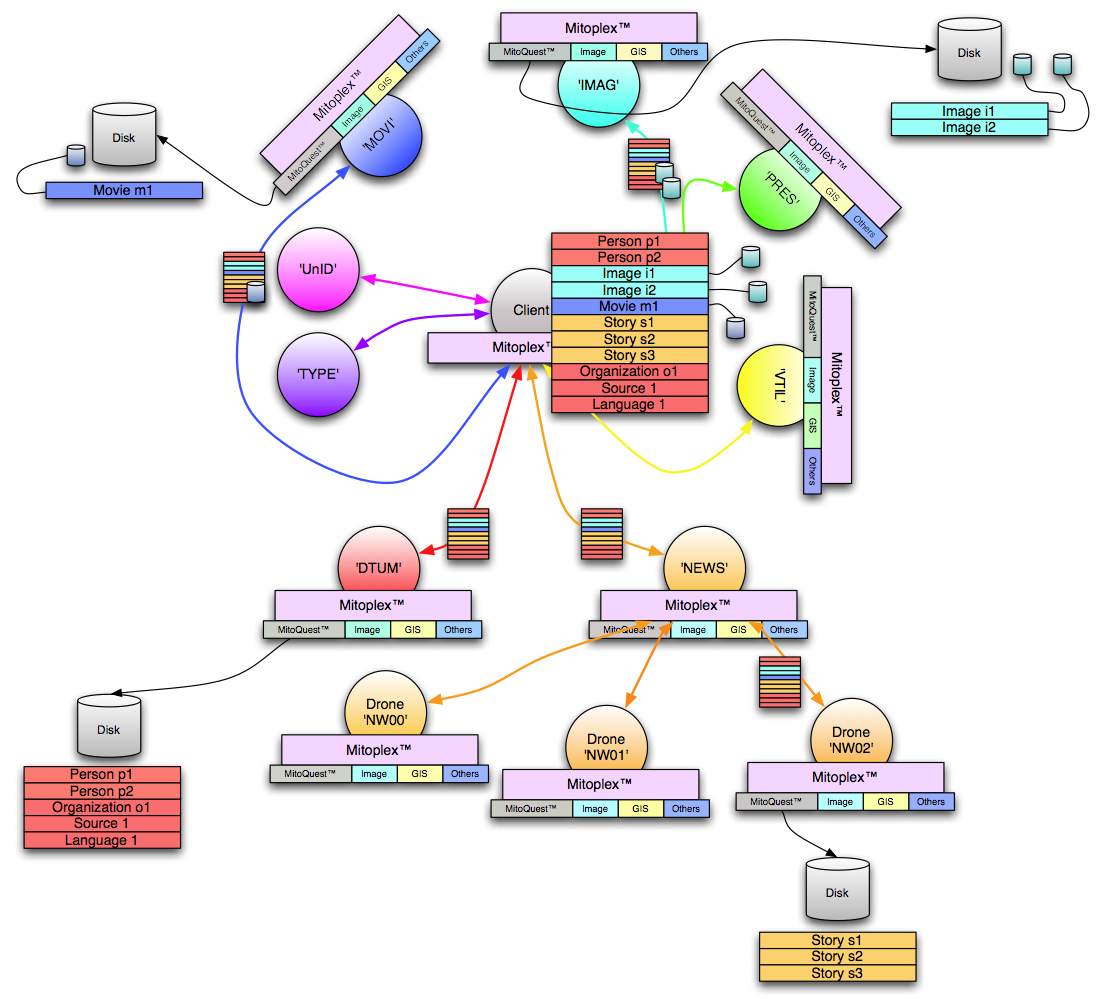 |
| Fig. 3 – Persisting a collection in a MitoPlex™ federation (Click to enlarge) |
Figure 3 above illustrates the process of persisting a single collection of various different types as mined by the user. The different record types in the collection are color coded in the same manner as the topology and type hierarchy of the previous figure. When the MitoPlex™ layer in the client is asked to persist a collection, it examines every record at the outer level in the collection to determine its type and then builds up a list of all servers that are in any way involved based on the types found. The identical collection is then sent by the MitoPlex™ layer to every server in turn. If there are multimedia files associated with particular records in the collection, these are also sent to the appropriate server (but not other servers) as the collection is sent. The smaller collection icons in the Figure 3 illustrate these communications paths.
In the case of a clustered server (as for ‘NEWS’ in the diagram), the master server picks which drone of the cluster to route the collection (and any multimedia files) to based on a variety of heuristics designed to create a load and data balanced cluster over a period of time. In the case illustrated, it has chosen to send the collection to ‘NW02’. Within ‘NW02’, as the collection is processed, a temporary collection copy is first sent to the other drones in the cluster to ask them if they already contain a record of any of the data items within the collection. If they do, they are responsible for merging any new information regarding that item into their existing collection storage. If not, they reply to the original requesting drone (‘NW02’) indicating this fact. If ‘NW02’ receives a negative response from all the other cluster members for a given item in the incoming collection, it goes ahead and creates a new record in its own collections folder for that item. In the case illustrated in the diagram, none of the news stories pre-existed in other drones and so all were persisted in ‘NW02’. In reality, the process of persisting rapidly and accurately within a cluster is extremely complex and a full description is beyond the scope of this post, however, the pertinent point is that the process ensures that every record of a given type anywhere in the cluster represents a unique item in the real-world, there is no redundant creation of records in different drones but instead new data on existing records is merged as necessary while entirely new records create new entries in the server databases. Literally years of work have gone into the problem of ensuring that this process happens rapidly and reliably regardless of the topology of the cluster and while ensuring that delays in one drone do not unduly slow down progress in others.
Any given server’s collections folder hierarchy is organized to directly match the Carmot ontology for the system and the server data collections (.COL) in each folder contain only records of the type corresponding to that folder, not any other type. Thus the set of records that are created in the ‘
DTUM’ server in the illustration are actually distributed across four distinct types and thus four separate .COL collection files. What this means is that the original heterogeneous collection sent by the client is shredded into distinct records for each type which are routed to and persisted by the various servers and server clusters on the network based on the ontology. Of course any
persistent (‘#’) or
collection (‘##’) references that were represented in the original contiguous collection must be preserved in this distributed form. In the original collection, these references would have been resolved within the
ET_PersistentRef and
ET_CollectionRef records to relative references within the collection via the ‘
elementRef’ (for a persistent reference) and “
_reference” (for an
ET_Hit that is part of a collection reference) fields. Clearly if the reference contains a permanent unique ID, then this is sufficient to resolve and re-establish the reference whenever the record is later fetched by a client, however, if the records in the collection have not been fully resolved (the normal case), then the unique IDs in the collection are temporary IDs, and a great deal of care and complexity is involved in ensuring data and referential integrity across the entire network. How MitoPlex™ accomplishes this is discussed in more detail in the following section.
Preserving Referential Integrity
As we have said, when a heterogeneous collection containing temporary unique IDs is persisted by the client MitoPlex™ layer, an identical copy of the collection is sent to all servers involved in any record within that collection. The fact that each server that is either the source or the destination of an as-yet unresolved reference receives a complete collection copy is the key to allowing us to ensure referential integrity despite the temporary unique IDs involved, and without introducing a bottleneck in the ingestion phase by requiring records to be pre-resolved before they are persisted. This patented use of a temporary ID scheme is one of the unique and powerful features of the MitoPlex™ abstraction and is a key to high performance distributed data ingestion.
As any given MitoPlex™ server processes the records within a collection that relate to it during a distributed persist, if it encounters a persistent or collection reference to a temporary ID for a type that is handled by another server on the network, it adds the referenced type, the referenced name, the reference location in the referencing collection, and the temporary ID to the file ‘typeName.TID’ (which is actually a collection also) in the same folder as the referencing type whose fields are being processed (where ‘typeName’ is the type name of the referencing type), i.e., alongside the server’s .COL file for the referencing type in the collections folder. The complete set of all “.TID” files containing currently unresolved temporary IDs is maintained by the MitoPlex™ layer. Similarly, if any server decides upon a permanent unique ID to replace the temporary ID for a record that the server is persisting (either due to a merge with an existing record or as a result of creating a new record), the server adds not only the permanent unique ID, but also the temporary unique ID to the lexical lookup file associated with the .COL collection which has the same file name but a .LEC extension. The .LEC files are primarily used to rapidly look up records in .COL collections by unique ID.
At regular intervals (every few minutes) when otherwise not busy, all MitoPlex™ servers examine the list of outstanding unresolved temporary IDs in their .TID files and issue requests to the other servers involved asking for the list of permanent unique IDs that correspond to the finally resolved temporaries. For any temporary IDs that have already been resolved in the other servers, the requesting server will receive a reply giving the new unique ID assigned which is then used by the requester to update the referencing fields in its own collections. As temporaries are fully resolved in this manner, they are deleted from the corresponding .TID files and when no unresolved temporaries remain, the .TID files themselves are deleted. Because each server repeats the requests to resolve temporaries until the resolution succeeds, it does not matter which order servers complete the persisting of data, eventually all temporaries will be resolved. Note that even prior to temporary IDs being resolved, they can still be used to reference and fetch the item involved. Temporary ID resolution even for a large persisted collection is usually over in seconds or minutes, however, the system servers have up to one week to resolve any outstanding temporaries between them before the temporary ID allocation scheme rolls over and the potential for temporary ID duplication exists. In practice this situation never occurs.
Another situation that threatens referential integrity is when a record is deleted from a given server or when two records are combined into one as a result of a user determining that they do in fact refer to the same real-world item. This is handled automatically in MitoPlex™ by ensuring that on any record deletion (or migration), the MitoPlex™ layer in the server involved broadcasts a notification of the deleted item(s) unique IDs to all servers in the system. Each server is then responsible for scanning any references within its data collections to see if they match the item deleted (or remapped) and if so to update the reference(s) involved. This global broadcast and update can take a while to complete and so deleting records unnecessarily should be avoided if possible.
Federated Database Containers in MitoPlex™
The various database containers that are to become members of a MitoPlex™ federation are registered with the MitoPlex™ layer during startup through the API function PX_DefineContainer(). This routine requires as parameters the name of the container (usually the type name in the Carmot ontology), and the container prefix string, for example:
PX_DefineContainer(“MitoQuest”,”MQ:”);
PX_DefineContainer(“Image”,”IM:”);
PX_DefineContainer(“Video”,”VI:”);
Once the container has been defined, custom plugins to handle various type-specific operations can be registered with MitoPlex™ using the API function PX_DefinePluginFunction(). Table 1 below presents the various possible plug-in routines and their purpose. Creating a new MitoPlex™ container type is a specialized undertaking and beyond the scope of this post, however, we will briefly discuss the purpose of some of the functions listed in Table 1. The key point about the MitoPlex™ approach to federation versus the standard systems integration approach is that MitoPlex™ uses a tightly-coupled vertical federation approach with identical network nodes whereas the standard approach uses loosely-coupled horizontal federation between heterogeneous network nodes. If you look at the figures above, you will see that every machine that is part of the server set is running identical software and that the containers that make up the federation are hard-linked (though symbolically registered) to (and within!) the MitoPlex™ federation layer through well defined calling interfaces. By contrast, a conventional systems integration approach to federation might appear as shown in Figure 4 below.
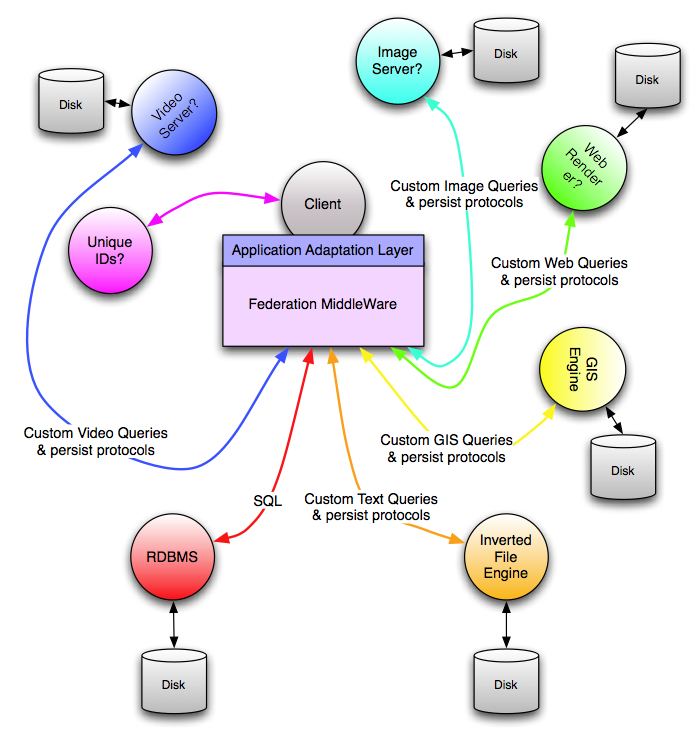 |
| Figure 4 – The standard approach to creating a federated database |
Each unique multimedia type and query capability is handled by a different server process with unique communications protocols, probably on dedicated hardware, and with performance limitations that are impedance mismatched with those of the rest of the system and hard to work around.
To make such a heterogeneous federation work, the systems integrator creates and/or builds upon a complex federation middleware layer that is designed to wrestle all the different servers into the appearance of a coordinated system, and to hide the higher level code from the complexity and fragility of all the connections involved. This is the classic appearance of a system that is ready to collapse over time due to the
Bermuda Triangle effect and the inevitability of change.
 |
| Table 1 – MitoPlex™ container plug-in function registry |
The biggest problem with the classic federated database architecture from a performance point of view is the ‘intermediate hits’ problem (or in pure RDBMS speak the ‘join’ problem). See the section below for a brief explanation. If we look again at the MitoPlex™ topology, given the discussions above it is clear that the problem does not exist within Mitopia® since the vertically integrated and heterogeneous nature of the federation in every server node means that large hit lists need never be sent across the network for resolution of different aspects of the query since all the necessary code is registered directly with each server and thus any required processing from other containers can be handled simply by function calls locally. This optimization approach is taken far further even than this however because the MitoPlex™ federation layer is responsible for combining all terms in a compound query (joined by Booleans such as OR or AND). This allows it to perform highly aggressive query optimization and a unique form of query pipelining thus eliminating any intermediate hit lists completely, even in local memory! We will discuss this in
future posts.
The Intermediate Hits Problem
Nowhere are classic federated database performance problem more obvious than in implementing combined queries that involve multiple different containers. Consider a simple query like “date is today and text contains dog”. To implement this, the middleware must issue a “text contains dog” query to the inverted file and retrieve a set of hits for matching items, it must then issue a “date is today” query to the relational container (since inverted files cannot handle this type of question). If we were in a large system, say 2 billion items per day, then the hit list resulting from the text query might contain billions of hits, all of which must be transmitted across the network to the middleware client, a process that might take hours. Similarly, the relational query will return 2 billion hits. The middleware must thus have the capacity to merge/prune all these billions of irrelevant hits using an AND operation to whittle the results down to those that match the entire criteria, perhaps no more than 10 or so. This inevitable result of such attempts at database federations leads to the massive failures in developing systems with which we are so familiar. A simple calculation on the back of an envelope should be sufficient for any such system architect to realize that these approaches can never work at scale. What we found with using this approach in Mitopia® was that system performance was limited severely and scalability to the very large became impossible, moreover the code artifices necessary to sustain this cobbled together approach to database federation became so huge and complex that system reliability was adversely impacted and the ability to adapt to changes in the environment or data was severely limited. This type of federation is essentially the integrated COTS (Commercial Off The Shelf) approach advocated by systems integrators today to address the intelligence problem. Hard won experience tells us that such an approach eventually fails. The problem is aggravated by the tendency of each distinct database vendor to change their application or worse yet, to stop supporting it. Eventually all such COTS products had to be eliminated from the Mitopia® database model which over time gave rise to the current architecture and federation set. The intermediate hits problem also exists within the relational database model itself where is is known as the ‘
join problem‘. This issue frequently also cripples
NoSQL approaches.
