
 Before we can talk about other aspects of Mitopia®, we must first explain various aspects of Mitopia’s compiler/interpreter abstractions that enable them. In an earlier post I introduced Mitopia’s unique lexical analysis technology. In todays post, I’d like to provide a brief introduction to Mitopia’s parser abstraction and to the limitations in current compiler theory that it seeks to overcome.
Before we can talk about other aspects of Mitopia®, we must first explain various aspects of Mitopia’s compiler/interpreter abstractions that enable them. In an earlier post I introduced Mitopia’s unique lexical analysis technology. In todays post, I’d like to provide a brief introduction to Mitopia’s parser abstraction and to the limitations in current compiler theory that it seeks to overcome.Parsing is the process of analyzing a text, made of a sequence of tokens (for example, words), to determine its grammatical structure with respect to a given (more or less) formal grammar. A Parser is one of the components in an interpreter or compiler, which checks for correct data structure often some kind of parser tree, abstract syntax tree, or other hierarchical structure) implicit in the input tokens. The parser often uses a separate lexical analyzer to create tokens from the sequence of input characters. Parsers may be programmed by hand or may be (semi-)automatically generated (in some programming languages) by a tool.
The most common use of a parser is as a component of a compiler or interpreter. This parses the source code of a computer programming language to create some form of internal representation. Programming languages tend to be specified in terms of a context-free grammar (CFG) because fast and efficient parsers can be written for them. Parsers are written by hand or generated by parser generators.
 Context-free grammars are limited in the extent to which they can express all of the requirements of a language. Informally, the reason is that the memory of such a language is limited. The grammar cannot remember the presence of a construct over an arbitrarily long input; this is necessary for a language in which, for example, a name must be declared before it may be referenced. More powerful grammars that can express this constraint, however, cannot be parsed efficiently. Parsers can be either top-down or bottom-up, depending on the basic approach taken to comparing the input with the defined grammar. Common examples of of top-down parsers include LL parsers and recursive-descent parsers. The most common form of bottom-up parsing is the LR parser approach. Each of these approaches has advantages and limitations and the grammars they can accept vary slightly, but all fall far short of the goal of handling a broad range or real world, possibly context sensitive languages. Unfortunately those are exactly the kind of languages that a system such as Mitopia® must be able to handle if it is to process real-world data sources, in multiple human languages, and intended for human readability (as opposed to formal and rigid programming language).
Context-free grammars are limited in the extent to which they can express all of the requirements of a language. Informally, the reason is that the memory of such a language is limited. The grammar cannot remember the presence of a construct over an arbitrarily long input; this is necessary for a language in which, for example, a name must be declared before it may be referenced. More powerful grammars that can express this constraint, however, cannot be parsed efficiently. Parsers can be either top-down or bottom-up, depending on the basic approach taken to comparing the input with the defined grammar. Common examples of of top-down parsers include LL parsers and recursive-descent parsers. The most common form of bottom-up parsing is the LR parser approach. Each of these approaches has advantages and limitations and the grammars they can accept vary slightly, but all fall far short of the goal of handling a broad range or real world, possibly context sensitive languages. Unfortunately those are exactly the kind of languages that a system such as Mitopia® must be able to handle if it is to process real-world data sources, in multiple human languages, and intended for human readability (as opposed to formal and rigid programming language).
 As for current lexical analyzer generators, the main problem with current parser generators is that they produce code as output (usually C) which must be compiled in order to create the actual parser (see previous section). This code can be extremely complex and often required hand tweaking. For example the ANTLR parser generator which is LL(*) produced 129,000 lines of code for one Oracle grammar. This code-based output obviously rules out the use of these conventional parser generators within Mitopia® which must be able to dynamically generate parsers for new languages without recompilation.
As for current lexical analyzer generators, the main problem with current parser generators is that they produce code as output (usually C) which must be compiled in order to create the actual parser (see previous section). This code can be extremely complex and often required hand tweaking. For example the ANTLR parser generator which is LL(*) produced 129,000 lines of code for one Oracle grammar. This code-based output obviously rules out the use of these conventional parser generators within Mitopia® which must be able to dynamically generate parsers for new languages without recompilation.
Another major shortcoming of current parser generators is that for most generators, the languages supported are restricted to deterministic context-free grammars that are either LL(1) or LALR(1). As discussed earlier LL(1) and LALR(1) grammars may be suitable for simple programming languages but they are hopelessly inadequate for generating parsers to process real world formats for virtually all data sources (except perhaps XML). If we look at the Wikipedia parser generator comparison table, we see that eliminating these simple languages leaves us with around 15 choices that are either LALR(k/*) or LL(k/*), all of which we can eliminate based on the fact that they generate code to be compiled as output.
So, while we could enumerate many other problems with classical parsing techniques such as their exponential run-time and storage behavior for ambiguous CFGs, there is little point, because we have already eliminated all current parser generators since they cannot meet the Mitopia® requirements.
The Mitopia® Parser Package
 The basic Mitopia parser abstraction is built on top of a classical LL(1) table driven approach, but adds a number of techniques to extend this to handle LL(n) and beyond. In particular the base layer defines a standard set of registered ‘plugin‘ functions together with an API they can use for manipulating all aspects of parser state. This allows a completely table driven approach, while allowing custom code to be registered at standard points, in order to handle the details of language implementation without having to worry about implementing the actual parsing process itself. This layer is then itself extended to support nested entangled parsers in order to broaden the languages supported still further. Finally, the nested parsers are encapsulated within a parsing context that is interfaced directly to data stored within Mitopia’s Carmot ontology and combined with a rich variety of predefined functions (e.g., MitoMine™ – see later posts) in order to trivially handle highly ambiguous context sensitive languages/grammars of virtually any complexity (up to and including processing binary data).
The basic Mitopia parser abstraction is built on top of a classical LL(1) table driven approach, but adds a number of techniques to extend this to handle LL(n) and beyond. In particular the base layer defines a standard set of registered ‘plugin‘ functions together with an API they can use for manipulating all aspects of parser state. This allows a completely table driven approach, while allowing custom code to be registered at standard points, in order to handle the details of language implementation without having to worry about implementing the actual parsing process itself. This layer is then itself extended to support nested entangled parsers in order to broaden the languages supported still further. Finally, the nested parsers are encapsulated within a parsing context that is interfaced directly to data stored within Mitopia’s Carmot ontology and combined with a rich variety of predefined functions (e.g., MitoMine™ – see later posts) in order to trivially handle highly ambiguous context sensitive languages/grammars of virtually any complexity (up to and including processing binary data).
All this without resorting to generating any code out of the parser generator, just parsing tables. The power of this Mitopia® parsing stack is difficult to over stress, however, because it is built up of so many layers, it must be presented in a series of graduated steps if it is to be fully understood. In this post we will present just a few basic concepts. Future posts will discuss parsers in more detail, and ultimately MitoMine™, MitoPlex™, and other technologies built on top of these lower layers.
Ultimately, the entire stack allows, among other things, processing and mining of virtually unlimited and even unstructured and highly context sensitive data formats and grammars. The original version of the Mitopia® parsing technology was developed in the mid 1980’s, and it has been evolving along its own path (independent from standard approaches) ever since. As a result, there is very little common ground this far down the line.
The figure below shows how the major components of a custom parser are assembled using Mitopia’s parser abstraction. The majority of the work is done within the custom parser creation routine, which is responsible for loading and creating both the lexical analyzer and parser databases, making the parser itself (using PS_MakeDB), and then registering any custom ‘plugin’ functions required for the application involved. The result is a fully configured parser database which can then be used by PS_Parse() to parse input compatible with the language defined. The parser ‘handle’ created during this process can optionally be registered (using PS_RegisterParser) so that future invocations can avoid repeating these steps and simply clone the registered parser (using PS_CloneDB).
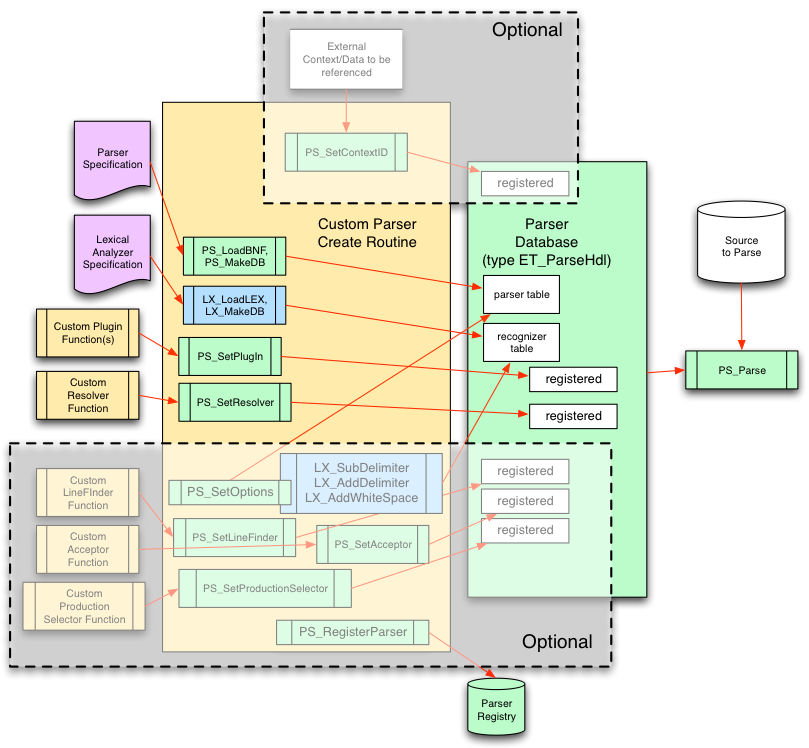 |
| Components of a Custom Parser |
Mitopia’s Extended BNF Format
Before we proceed, we need to introduce the basics of language grammar definition. Mitopia® does this using its own extended BNF format. For a background in standard BNF, refer to a compiler theory book such as “Compilers: Principles, Techniques and Tools” by Alfred V. Aho, Ravi Sethi, and Jeffrey D. Ullman (ISBN 0-201-10088-6). Also known as “The Dragon Book”.
The ‘bnf’ parameter passed to PS_MakeDB() contains a series of lines that specify the BNF for the grammar in the form:
non_terminal ::= production_1 production_2 …
production_1 ::= …
…
Where production_1 and production_2 are themselves defined using any sequence of ‘terminal’ symbols (described in lexical analyzer passed in to PS_MakeDB()), non-terminal grammar symbols (alphanumeric strings including ‘_’ appearing in the BNF but otherwise un-defined – for example production_1), and specialized meta-symbols that are part of Mitopia’s extended BNF (EBNF) language itself. Productions may continue onto the next line if required, but any time a non-white character is encountered in the first column position of the line, it is assumed to start the definition of a new production. The table below lists the set of meta-symbols that are recognized as part of Mitopia’s EBNF specification language itself. You will note that within Mitopia’s EBNF, the normal BNF convention of enclosing non-terminal production names within ‘<‘ and ‘>’ delimiters is reversed such that reserved meta-symbols of the EBNF tend to be between these delimiters. There are a number of reasons for this reversal from the standard form. Note however, that this does not preclude using language defined symbols (e.g., XML tags such as <Person>) directly within the BNF since they are highly unlikely to conflict with the EBNF meta-symbol formats.
 |
| Reserved Meta-Symbols Used in Mitopia’s Extended BNF |
Future posts will elaborate on these basic concepts to describe the various abstractions that are layered on the parser abstraction.