
In earlier posts I have introduced the Mitopia®-unique related topics of heteromorphic languages and of the MitoMine™ approach to data mining and integration. In this post we will go a little deeper into the MitoMine™ language itself in order to provide a background for discussing MitoMine™ application examples.
As with all heteromorphic language suites, MitoMine™ wraps the parser abstraction with its own API functions in order to register custom behaviors as required. The primary registrations for MitoMine™ are a custom ‘resolver’ function and custom ‘plugin’ function (plugin 1) which implements the five meta-symbols or plugin operators (i.e., <@1:n>) that make up the MitoMine™ functionality. The sole inner or endomorphic parser for MitoMine™ is Carmot-E, since this language provides Mitopia’s primary means of symbolically accessing data described by the system ontology and held within a collection(s). In the case of MitoMine™, Carmot-E is invoked via the <@1:5> meta-symbol, and the collection node designation within the ‘temporary’ collection (see CT_SetPrimaryNode) is controlled by the <@1:4> and <@1:3> meta-symbols. With the exception of <@1:5>, all other implemented meta-symbols are sufficiently simple that a dedicated nested parser is not required, and the functionality is implemented directly by MitoMine’s registered plugin one.
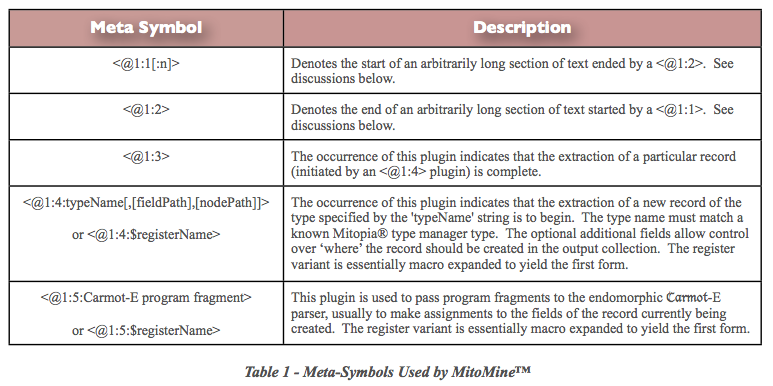
MitoMine™ Meta-Symbols (Plugin – 1)
The MitoMine™ language registers a single custom ‘plugin’ function 1. The meta-symbols or function selector values (i.e., <@1:n> where ‘n’ is the selector value) supported by this plugin are given in the table below:
Matching Text Sequences (<@1:1> and <@1:2>)
There are a number of issues that must be considered when creating a script to extract an arbitrary block of text, possibly spanning many lines and the MitoMine™ meta-symbols <@1:1> and <@1:2> are provided to simplify the problem. These two plugins delimit the start and end of an arbitrary and possibly multi-lined string which will be assigned to the current value register ( $ ) and usually from there to a field/register designated by the following <@1:5> call (e.g., <@1:5:fieldPath = $>). This is the method used to extract large arbitrary text fields. The token sequence for these plugins is always of the form <@1:1> <1:String> <@1:2>, that is any text occurring after the appearance of the <@1:1> plugin on the top of the parsing stack will be converted into a single string token (token # 1) which can be assigned by a subsequent <@1:5> plugin call. The arbitrary text will be terminated by the occurrence of any terminal in the language (defined in the .LXS file) whose value is above 128, or which explicitly follows the sequence in the BNF specified. Thus the following snatch of BNF will cause the field ‘pubName‘ to be assigned whatever text occurs between the token <PUBLICATION> and <VOLUME/ISSUE> in the input file:
<PUBLICATION> <@1:1> <1:String> <@1:2> <@1:5:pubName = $>
<VOLUME/ISSUE> <3:DecInt> <@1:5:volume = $>
When extracting these arbitrary text fields, all trailing and leading white space is removed from the string before assignment and all occurrences of LINE_FEED are removed to yield a valid Macintosh [multi-line] text string where lines are ended by CR_RETURN.
The fact that tokens below 128 will not terminate the arbitrary text sequence is important in certain situations where a particular string is a terminal in the language, and yet might also occur within such an arbitrary text sequence where it should not be considered to have any special significance. All such tokens can be assigned token numbers below 128 in the .LXS file thus ensuring that no confusion arises. There is of course an exception made if the string sequence is explicitly followed (i.e., if the terminating token is in FOLLOW of <1:String> in this case – see here for details) by a token number below 128 in the BNF. In this case the following token number below will terminate the extracted string as expected. The occurrence of another <@1:1> or a <@1:4> plugin causes any previous <1:String> text accumulated to be discarded.
If it is known that the string to be extracted will never contain any line endings (i.e., newline or linefeed characters) then there is generally no need to use the dedicated meta-symbols, and in the example above it would be sufficient to write:
<PUBLICATION> <1:String> <@1:5:pubName = $>
If a ‘plugin’ hint (see here) consisting of a decimal number follows the <@1:1> as in <@1:1:4>, that number specifies the maximum number of lines of input that will be consumed by the plugin (four in this example). This is a useful means to handle input where the line number or count is significant.
The reason that the <@1:1>/<@1:2> meta-symbol pair is required around potentially multi-line text sequences, is that without this logic, the underlying parser (which is line-based), would return token 1 for the first line of the input and then, most likely, additional token 1 values for each subsequent line. This would require the script to know before hand how many lines are present in each case. The effect of the meta-symbol wrapping is to cause all extracted text regardless of the number of lines, to appear to the parser/script as a single <1:String> token.
It is possible to accidentally specify in your BNF that one <@1:1>/<@1:2> meta-symbol pair immediately follow another. This is obviously an undefined condition at runtime since the parser has no way to determine where the first <1:String> token should end, and the second one should start. For this reason it is considered an error to do this in a script, and the error ‘kNoInterveningToken’ will be reported at run time if this condition is detected. Note however that it is permitted to follow an <@1:1:n>/<@1:2> pair by a subsequent <@1:1> because in that case the parser does have a way to determine where the first pair ends in the source text.
The actual implementation of these meta-symbols involves not only the MitoMine™ plugin, but also considerable complexity within the registered ‘resolver’ as well as the registration and use of a custom ‘acceptor’ function (see here). Examples of the complexities include handling the following conditions:
- The string sequence could start with a numeric value, a token between 64 and 128, or an invalid token returned as -1 or -2 by the lexical analyzer. The recognizer must ensure that the parser does not see these tokens but instead enters a mode to accumulate and return a single string token. Of course if one of these tokens begins an alternate production for the current top of the parser stack, then that token should be returned and the alternate production selection rather than the production beginning with the <@1:1>.
- The resolver must keep track of the number of lines ‘gobbled’ and terminate the mode when appropriate if the form <@1:1:n> was used.
- Token numbers between 64 and 128 may or may not terminate the ‘gobble’ mode depending on if they are in FOLLOW(parser TOF).
- The string sequence is ended by a token in FOLLOW of the current production, at which time token 1 must be returned, ‘gobble’ mode ended, and then the ‘resolver’ backed up so that the trailing token is returned on the next call.
All this logic is distributed between the ‘plugin’ and ‘resolver’ functions, and these kinds of issues are examples of the need for parser API functions like PS_IsLegalToken(), PS_WillPopParseStack(), etc.
When the <@1:1> meta-symbol is processed by the ‘plugin’, the content of the current value register ‘$’ is initially set empty so that scripts can handle the case of an empty string correctly and so that ‘$’ always reflects just the currently processed token.
Designating the Current Output Record (<@1:3> and <@1:4>)
When an assignment is made to a field of a typed collection element in Carmot-E, it is necessary that the element node be designated before that assignment occurs. Different heteromorphic language suites that incorporate Carmot-E as the endomorphic component take different approaches to how this node designation occurs. In the case of MitoMine™, the language is designed to create a series of records that represent the extracted and transformed content of the mined source file. This means that logically within MitoMine™, the node being assigned is almost always the node that is currently being created. For this reason the MitoMine™ language uses dedicated meta-symbols to begin (<@1:4>) and end (<@1:3>) the process of creating a new record within the Carmot-E ‘primary’ collection (which is referred to as the ‘temporary’ collection in a MitoMine™ context). If any read/write to/from a field of the designated Carmot-E ‘primary’ collection node (i.e., the assignment is not surrounded by ‘[[‘ and ‘]]’ delimiters) occurs at a time when no node has been designated, a ‘kBadAssignment’ error will occur. This means that all occurrences of the <@1:5> meta-symbol containing field assignments must happen between an earlier <@1:4> meta-symbol and a later <@1:3>. The exception to this rule is if the ‘kPermitEmptyAssignments’ parser option is specified in which case such assignments are silently ignored.
The basic format of an <@1:4> plugin call utilizes the ‘hint’ text to specify the type name of the node to be created in the temporary collection (thereafter referred to as the ‘current’ node). For example the meta-symbol <@1:4:Country> will create a new initially empty node of the type ‘Country’ as defined by the current system Carmot ontology. Because the temporary collection is created and organized based on the system ontology, there is generally no need to specify the ‘path’ to the node being created since it is fully defined by the type name given. Thus in our ‘Country’ example, the path to the node (below the root of the collection which is equivalent to the abstract type ‘struct’) within the temporary collection will be:

If these ancestral collection nodes do not yet exist, they are created and named as a by-product of creating the new node. The behavior of the MitoMine™ suite is such that as soon as a the count of <@1:3> meta-symbols encountered matches the count of <@1:4> meta-symbols, the entire content of the ‘temporary’ collection is merged into the ‘output’ collection, count totals are reset, and the temporary collection is re-created from scratch. This means that one and only root descendant node is explicitly created in the temporary collection before each merge with the output collection. However, calls to <@1:4> (and the corresponding calls to <@1:3>) can be nested up to 256 levels if desired in order to allow scripts to explicitly create sub-collections within an ‘@@’ field of a root descendant node using the extended form <@1:4:typeName:,[fieldPath],[nodePath]> so that the sub-collection node becomes the ‘current’ node until the matching <@1:3> is encountered at which time the current node state is ‘popped’ and once again becomes the owning record of the sub-collection.
Perhaps 99% of all MitoMine™ scripts do not need to nest node creation calls, and do not use the extended form of <@1:4>. Other methods are provided to create ‘@@’ sub-collection records (using the ‘;;’ assignment convention).
The occurrence of an <@1:4> plugin indicates that the extraction of a new record of the type specified by the ‘typeName‘ string is to begin. The type name must match a known Mitopia® type manager type either defined elsewhere (e.g., in A.DEF to K.DEF), or within the type definitions supplied within the .TPS file associated with the script. The optional field and node path elements of the <@1:4> plugin are generally used when creating relative ‘@@‘ sub-collections within outer collection nodes. If these components are omitted, the record is created at the outer level of the collection and is organized into the hierarchy determined by the ontology. In this case, the occurrence of another <@1:4:typeName> plugin (without the ‘@@‘ elements) before the terminating <@1:3> for the previous record will cause an error and abort the parse. Do not use the extended form of <@1:4> for creating ‘##‘ sub-collections, this is accomplished in other ways described later.
If however the optional <@1:4> modifiers are present, and the closing <@1:3> of the current node has not yet occurred, this is taken as an indication to create nodes within the ‘@@‘ field specified by “fieldPath” organized according to the paths specified in “nodePath“. If “nodePath” is omitted (the normal case) the new node is created as a child of the current node being constructed, and the old node is pushed onto a stack from where it is restored as soon as the corresponding <@1:3> occurs. To create nested nodes in the sub-collection, you should use the form <@1:4:typeName,,> before the <@1:3> for the prior sub-node which simply nests the node stack one level, and creates the new node as a child. Nodes can be nested in this manner up to 256 levels. If the ‘nodePath‘ parameter is present, it is taken to be the path relative to the current node (or if ‘fieldPath‘ is present, to the root of the ‘@@‘ collection for ‘fieldPath‘). If ‘nodePath‘ ends in an ‘:‘ character, the new node is created immediately within the path specified. If ‘nodePath‘ does not end in an ‘:‘ character, it is taken to specify the entire path to the new node.
One example of more complex use of nested <@1:4> plugin calls can be found in the GenesisXML script which is used by Mitopia® to mine the specification for all windows layouts within the Universal renderer from the XML form used by the earlier Genesis renderer. The relevant portions of this script are shown below: We can see from the first production that each XML file specifies a single window layout where the type Canvas (see K.DEF) is the ontological type equivalent to the window object. The fact that the script immediately issues an <@1:4:Canvas> call and does not call the matching <@1:3> until the end of the input XML file means that all subsequent Control nodes are created within the ‘@@controls’ sub-collection of the outer Canvas record (first <@1:4:Control,controls,> call within ‘nestNode’), thereafter any controls nested within the outermost window ‘view’ control will be simply created as sub-nodes within the valued node corresponding to their containing control (this is the <@1:4:Control,,> call in the script). The end result is extraction of the entire XML tree including all the nested controls into the ‘@@controls’ sub-collection of the Canvas record. This extracted structure can then be used to create a matching window layout using non-Genesis renderers within the Universal renderer framework.
We can see from the first production that each XML file specifies a single window layout where the type Canvas (see K.DEF) is the ontological type equivalent to the window object. The fact that the script immediately issues an <@1:4:Canvas> call and does not call the matching <@1:3> until the end of the input XML file means that all subsequent Control nodes are created within the ‘@@controls’ sub-collection of the outer Canvas record (first <@1:4:Control,controls,> call within ‘nestNode’), thereafter any controls nested within the outermost window ‘view’ control will be simply created as sub-nodes within the valued node corresponding to their containing control (this is the <@1:4:Control,,> call in the script). The end result is extraction of the entire XML tree including all the nested controls into the ‘@@controls’ sub-collection of the Canvas record. This extracted structure can then be used to create a matching window layout using non-Genesis renderers within the Universal renderer framework.
This example shows MitoMine™ being used transparently within normal operations of Mitopia’s GUI framework to solve the discrepancy between the original Genesis renderer (which used its own non-ontological method to parse and load the window specification) and the pure ontology driven form of all subsequent renderers based on the Universal renderer layer. This is what heteromorphic languages do best, and also shows that MitoMine™ itself can be used as an abstraction on which to build even higher level abstraction layers. While there are a number of such examples within Mitopia®, the main purpose of MitoMine™ is to mine ontological data from external sources. For this reason we will refer to these ‘embedded’ MitoMine™ uses only tangentially.
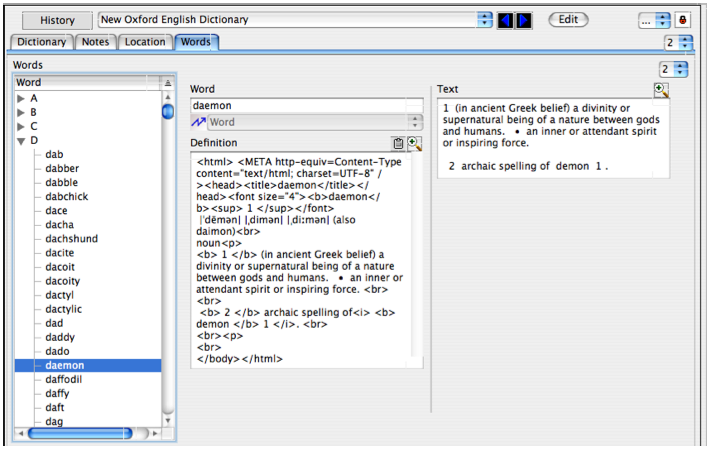
The listing below shows another example of the use of the extended form of the <@1:4> meta-symbol, in this case taken from the DictionaryXML MitoMine™ script. In this script we are mining the content of the New Oxford English dictionary to extract the dictionary content into the ontology as a set of Word records referenced from a Dictionary via the ‘DictionaryEntry @@words’ sub-collection within the Dictionary record. Because there are so many words in the Dictionary, we want to organize the ‘@@’ sub-collection by the first letter of the word so that entries appear under nodes named ‘A’ to ‘Z’ within ‘@@words’. This makes the GUI easier to use and allows easier navigation.

The script accomplishes this by dynamically constructing the required <@1:4> content (first red highlighted production) based on the the word involved so that if the word were “dog” for example, the result of this first production would be that the register ‘$pg’ contained the string “DictionaryEntry,words,D:”. The script then actually issues the <@1:4> meta symbol using the ‘macro expanded’ register variant <@1:4:$pg> which after expansion is seen by the MitoMine™ plugin-1 function as <@1:4:DictionaryEntry,words,D:>. This form makes use of all three fields of the extended meta-symbol form including the final ‘nodePath’ field (see Table 1), which in this case causes the creation of a nested ‘DictionaryEntry’ node named “dog” within the sub-collection path “D”. The result is that the extracted dictionary is now organized by letter of the alphabet as shown in the screen shot below.
Within the <@1:3> plugin call, the logic examines the current nesting level and if the <@1:3> applies to a ‘nested’ node, then all that happens is the node stack is popped and operation continues with the restored ‘designated’ node. If the <@1:3> invocation is not a nested one (the normal case), then the following occurs:
- The code empties the parsing evaluation stack for the ectomorphic parser. This ensures that the evaluation stack does not build up with extracted token values that are no longer needed.
- The registered ‘record adder’ function is invoked in order to expand the designated ‘primary’ node references and then merge the ‘primary’ collection into the ‘output’ collection. Most mining processes do not register a custom ‘record adder’ and so the default internal ‘record adder’ for MitoMine™ is used. This function (MN_DefaultRecAdd) implements the following basic behaviors:
- if the record does not have a unique ID, a temporary ID is assigned
- If the record is descended from ‘Source’, the ‘source’ field is zapped. This prevents infinite loops in source dependencies.
- If the record’s ‘name’ field is empty, a ‘kEmptyNameField’ error is reported. This does not apply for records that are not descended from Datum and do not contain a name field. If you do not know the record name, your script should set it to the general form “Unknown – typeName [other stuff]” where ‘typeName’ is the type of the record involved. This convention ensures correct updating of the record name when it is finally determined and persisted into the servers. See later discussions on merging.
- The $GenerateLinks() type script is invoked for the record. See later discussions. This script (which is defaulted, but can be overridden) expands any non-empty reference fields to create the additional records they refer to, still within the ‘temporary’ collection.
- All valued nodes now in the ‘temporary’ collection, including those that were added by the $GenerateLinks() type script are walked, and for each node:
- If ( the node is descendant from ‘Source’ or the ‘kItemsAreUnique’ parser option is not in effect ), OR the node was created by the $GenerateLinks() script call above:
- Search the ‘output’ collection for a matching node using TC_FindMatchingElement() – use the ‘kMatchByNameOnly’ option if the parser ‘kMatchElementsByNameOnly’ option is in effect.
- If no matching node in the ‘output’ collection has been found, add a new empty one.
- Merge the temporary node into the corresponding new/added node in the ‘output’ collection (again for merged reference fields the ‘kMatchElementsByNameOnly’ option applies.
- If ( the node is descendant from ‘Source’ or the ‘kItemsAreUnique’ parser option is not in effect ), OR the node was created by the $GenerateLinks() script call above:
- If the ‘record adder’ call fails, report a ‘kFailedRecordAcquisition’ error, otherwise bump the count of records added.
- The ‘temporary’ collection is zapped/disposed. It is recreated as needed on the next <@1:4> invocation.
- If a maximum number of records was specified for this mining run and the record count equals or exceeds that, abort the parse without error.
- If running within a ‘batch command file’ (i.e., this does not occur if directly invoked from the GUI), AND there was a specification in the ‘custom string’ for “WriteToStorage” that gave a file path ending in “.COL”, AND the ‘output’ collection size now exceeds 16 MB:
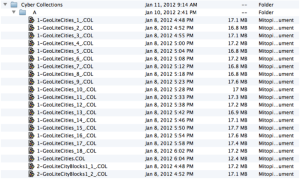 Save the output collection file so far to a file of the same name but ending with _n_.COL where ‘n’ is incremented. Dispose the output collection and form a new empty one. This logic is designed to ensure that massive ‘batch’ mining runs output a set of collections of manageable size and do not produce massive collections that cause memory issues or clog up the servers during persisting. The figure of 16MB for the collection ‘chunk’ size represents a reasonable size such that this logic does not kick in except for the largest of sources. Note that there will be no problem caused by this behavior as far as the integrity of the final data in the servers is concerned, since subsequent mined records will fill new output collection(s) and these will be merged during the server persisting process in order to unify all the records from the various ‘chunks’ as they should be. The screen shot above illustrates the appearance of the mined output folder as a result of this collection ‘chunking’ behavior. The final collection file (1-GeoLiteCities.COL in the screen shot) containing any additional records mined after the last ‘chunk’, is flushed out using the unmodified name specified in the “WriteToStorage” custom string entry at the time the mining run completes.
Save the output collection file so far to a file of the same name but ending with _n_.COL where ‘n’ is incremented. Dispose the output collection and form a new empty one. This logic is designed to ensure that massive ‘batch’ mining runs output a set of collections of manageable size and do not produce massive collections that cause memory issues or clog up the servers during persisting. The figure of 16MB for the collection ‘chunk’ size represents a reasonable size such that this logic does not kick in except for the largest of sources. Note that there will be no problem caused by this behavior as far as the integrity of the final data in the servers is concerned, since subsequent mined records will fill new output collection(s) and these will be merged during the server persisting process in order to unify all the records from the various ‘chunks’ as they should be. The screen shot above illustrates the appearance of the mined output folder as a result of this collection ‘chunking’ behavior. The final collection file (1-GeoLiteCities.COL in the screen shot) containing any additional records mined after the last ‘chunk’, is flushed out using the unmodified name specified in the “WriteToStorage” custom string entry at the time the mining run completes.
The logic described above determines how each record mined by the script and created using the <@1:4> meta-symbol is expanded and merged into the ‘output’ collection. This ‘output’ collection(s) is then itself merged with the existing content of persistent storage. See the later discussions on the merging process for more details, particularly regarding the behavior of the $GenerateLinks() script and the operation of TC_FindMatchingElement().
The routine MN_DefaultRecAdd() is public so that mining processes with specialized needs as far as merging into the ‘output’ collection can register custom ‘record adder’ processes while still being able to invoke all the behaviors within MN_DefaultRecAdd() as part of the full ‘record adder’ logic. An example of where this capability is used is the logic associated with the automatic ontology mapping that occurs when Mitopia® encounters a collection held in an ‘old’ version of the ontology. In this case a custom ‘record adder’ is needed to process the ontology mapped records correctly.
Invoking Nested Carmot-E Programs (<@1:5>)
Within the MitoMine™ heteromorphic language suite, Carmot-E endomorphic programs are invoked through the <@1:5> meta-symbol. Other than the grammar productions themselves, these <@1:5> meta-symbols form the bulk of any MitoMine™ script. Carmot-E is Mitopia’s preferred endomorphic language for accessing data held according to the system ontology within the collection abstraction. In the case of MitoMine™, the designated node in the collection to be read/written is set by a preceding call to the <@1:4> plugin which creates a new record of a specified type into which data extracted from the source text can be written or referenced from. Completion of the designated node is indicated in the MitoMine™ script by a <@1:3> meta-symbol. The Carmot-E language and run-time environment is described here, and the reader is assumed to be familiar with the content of that description which will not be repeated herein.
The MitoMine™ plugin-1 code adds the <@1:5:$registerName> form (as discussed for <@1:4> above) to allow the string content of the specified register to be macro expanded in order to obtain the actual Carmot-E program statements to be executed. This capability essentially allows self modifying code, that is code that can construct in a register a program to be executed, and then do so. This is a very powerful technique and can solve a number of complex problems in script writing. Self modification is generally frowned upon as a programming technique, but in the context of a heteromorphic language it can be a perfectly valid and effective strategy. The macro expansion behavior occurs only if a <@1:5> meta symbol contains nothing but a valid register name (including ‘$’) within it as in <@1:5:$aa> or <@1:5:$>. If the register specified contains a string value then that string value is taken to be the meta-symbol ‘hint’, that is the Carmot-E program to execute. If the register specified does not contain a string, a syntax error will be reported. Examples of possible uses include loading nested MitoMine™ scripts from file and executing them, executing Carmot-E instructions in source text being mined, dynamically constructing and executing code, etc. All that having been said, 99% of all MitoMine™ scripts will never need to use this macro expansion form and thus the content of the <@1:5> meta-symbols will simply be a standard sequence of Carmot-E statements.
The only other unique activity performed by MitoMine’s <@1:5> meta-symbol prior to invoking the function CT_Parse() to interpret the Carmot-E statements within, is to set up the value of the ‘current value’ register if not already done prior to making the CT_Parse() call. This logic is made somewhat more complex by the effect of the <@1:1>/<@1:2> meta-symbol pair. When CT_Parse() completes, the ectomorphic parser’s evaluation stack is cleared out except for the top element of the stack. This avoids an ectomorphic evaluation stack overflow while preserving just the top of stack in case it is required.
We will continue to delve into the workings of the MitoMine™ language in future posts.