
 Formally speaking, data integration involves combining data residing in different sources and providing users with a unified view of these data.
Formally speaking, data integration involves combining data residing in different sources and providing users with a unified view of these data.This process becomes significant in a variety of situations, which include both commercial (when two similar companies need to merge their databases) and scientific (combining research results from different bioinformatics repositories, for example) domains. Data integration appears with increasing frequency as the volume and the need to share existing data explodes. It has become the focus of extensive theoretical work, and numerous open problems remain unsolved. In management circles, people frequently refer to data integration as “Enterprise Information Integration“.
Background
Data Integration is normally distinct from Data Mining which formally is the process of scanning the ‘integrated’ data looking for new patterns and presenting/visualizing them for human interpretation.
The historically distinct concepts of data integration and data mining were defined in terms of systems operating at the information level only (i.e., built upon relational databases). However, in the Mitopia® context, because the data being ingested is simultaneously being transformed from the various data/information level source formats/taxonomies into the underlying knowledge-level system ontology, thus moving to a whole new tier of the knowledge pyramid, we tend to use the term data mining interchangeably with data integration to signify the extraction of ‘useful’ nuggets of knowledge from the low grade data/information level substrate/ore in which they reside. This refinement/extraction process is more akin to what one would term ‘mining’ than it is to ‘integration’, even though both processes are occurring simultaneously. Transformation from diverse taxonomies into a single unifying and integrating ontology in and of itself reveals new patterns and relationships without any additional steps being required beyond display.
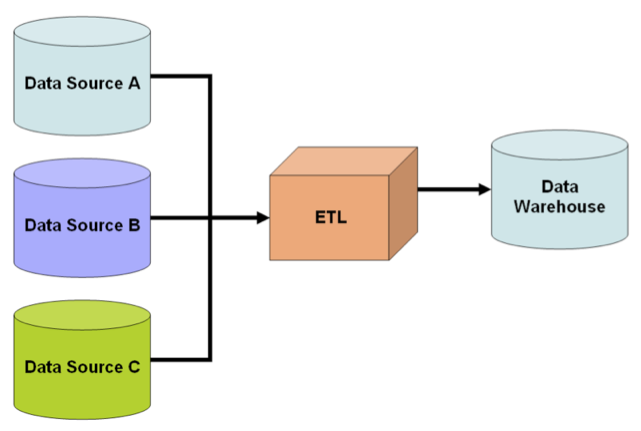 Issues with combining heterogeneous data sources under a single query interface have existed for some time. The rapid adoption of databases after the 1960s naturally led to the need to share or to merge existing repositories. This merging can take place at several levels in the database architecture. One popular solution is implemented based on data warehousing. The warehouse system extracts, transforms, and loads data from heterogeneous sources into a single common query-able schema so data becomes compatible with each other. This approach offers a tightly coupled architecture because the data is already physically reconciled in a single repository at query-time, so it usually takes little time to resolve queries. However, problems arise with the “freshness” of data, which means information in warehouse is not always up-to-date. Therefore, when an original data source gets updated, the warehouse still retains outdated data and the ETL process needs re-execution for synchronization. Difficulties also arise in constructing data warehouses when one has only a query interface to summary data sources and no access to the full data. This problem frequently emerges when integrating several commercial query services like travel or classified advertisement web applications.
Issues with combining heterogeneous data sources under a single query interface have existed for some time. The rapid adoption of databases after the 1960s naturally led to the need to share or to merge existing repositories. This merging can take place at several levels in the database architecture. One popular solution is implemented based on data warehousing. The warehouse system extracts, transforms, and loads data from heterogeneous sources into a single common query-able schema so data becomes compatible with each other. This approach offers a tightly coupled architecture because the data is already physically reconciled in a single repository at query-time, so it usually takes little time to resolve queries. However, problems arise with the “freshness” of data, which means information in warehouse is not always up-to-date. Therefore, when an original data source gets updated, the warehouse still retains outdated data and the ETL process needs re-execution for synchronization. Difficulties also arise in constructing data warehouses when one has only a query interface to summary data sources and no access to the full data. This problem frequently emerges when integrating several commercial query services like travel or classified advertisement web applications.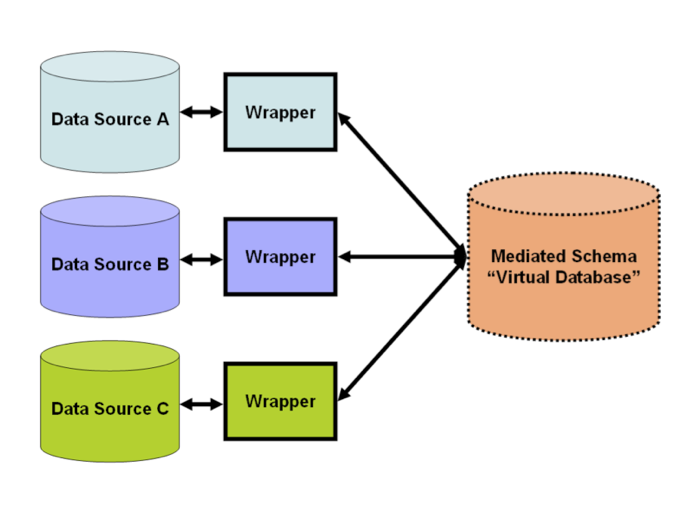 As of 2009 the trend in data integration has favored loosening the coupling between data and providing a unified query-interface to access real time data over a mediated schema, which means information can be retrieved directly from original databases. This approach may need to specify mappings between the mediated schema and the schema of original sources, and transform a query into specialized queries to match the schema of the original databases. Therefore, this middleware architecture is also termed as “view-based query-answering” because each data source is represented as a view over the (nonexistent) mediated schema. Formally, computer scientists term such an approach “Local As View” (LAV) — where “Local” refers to the local sources/databases. An alternate model of integration has the mediated schema functioning as a view over the sources. This approach, called “Global As View” (GAV) — where “Global” refers to the global (mediated) schema — has attractions owing to the simplicity of answering queries by means of the mediated schema. However, it is necessary to reconstitute the view for the mediated schema whenever a new source gets integrated and/or an already integrated source modifies its schema.
As of 2009 the trend in data integration has favored loosening the coupling between data and providing a unified query-interface to access real time data over a mediated schema, which means information can be retrieved directly from original databases. This approach may need to specify mappings between the mediated schema and the schema of original sources, and transform a query into specialized queries to match the schema of the original databases. Therefore, this middleware architecture is also termed as “view-based query-answering” because each data source is represented as a view over the (nonexistent) mediated schema. Formally, computer scientists term such an approach “Local As View” (LAV) — where “Local” refers to the local sources/databases. An alternate model of integration has the mediated schema functioning as a view over the sources. This approach, called “Global As View” (GAV) — where “Global” refers to the global (mediated) schema — has attractions owing to the simplicity of answering queries by means of the mediated schema. However, it is necessary to reconstitute the view for the mediated schema whenever a new source gets integrated and/or an already integrated source modifies its schema.As of 2010 some of the work in data integration research concerns the semantic integration problem. This problem addresses not the structuring of the architecture of the integration, but how to resolve semantic conflicts between heterogeneous data sources. For example if two companies merge their databases, certain concepts and definitions in their respective schemas like “earnings” inevitably have different meanings. In one database it may mean profits in dollars (a floating-point number), while in the other it might represent the number of sales (an integer). A common strategy for the resolution of such problems involves the use of ontologies which explicitly define schema terms and thus help to resolve semantic conflicts. This approach represents conventional ontology-based data integration.
Although it represents the current trend in classical data integration, we can ignore the mediated schema approach henceforth because it is predicated on the fact that the information remains in the original sources/repositories, which in turn implies that it remains limited in its expressiveness to the ‘information level’. The creation of connections across distinct sources, which is of course the fundamental operation of a knowledge level system, is difficult or impossible in this architecture and even if achieved, resultant performance tends to be very disappointing. Such systems are also very difficult to adapt in the face of change which is of course pervasive for any non-trivial system integrating external ‘unconstrained’ sources.
Extract Transform Load (ETL)
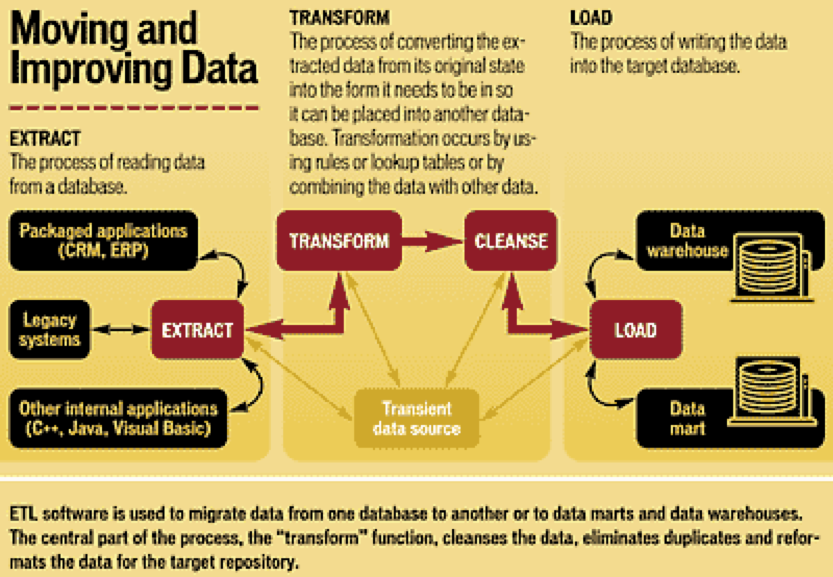
The term ETL which stands for extract, transform, and load, is a three-stage process in database usage and data warehousing. It enables integration and analysis of the data stored in different databases and heterogeneous formats. After it is collected from multiple sources (extraction), the data is reformatted and cleansed for operational needs (transformation). Finally, it is loaded into a target database, data warehouse or a data mart to be analyzed. Most of numerous extraction and transformation tools also enable loading of the data into the end target. Except for data warehousing and business intelligence, ETL tools can also be used to move data from one operational system to another.
Extract – The purpose of the extraction process is to reach to the source systems and collect the data needed for the data warehouse. Usually data is consolidated from different source systems that may use a different data organization or format so the extraction must convert the data into a format suitable for transformation processing. The complexity of the extraction process may vary and it depends on the type of source data. The extraction process also includes selection of the data as the source usually contains redundant data or data of little interest. For the ETL extraction to be successful, it requires an understanding of the data layout. A good ETL tool additionally enables a storage of an intermediate version of data being extracted. This is called “staging area” and makes reloading raw data possible in case of further loading problem, without re-extraction. The raw data should also be backed up and archived.
Sources may be structured (e.g., relational databases) or unstructured (e.g., documents). Typical unstructured data sources include web pages, emails, documents, PDFs, scanned text, mainframe reports, spool files etc. Extracting data from these unstructured sources has grown into a considerable technical challenge. Whereas historically data extraction has had to deal with changes in physical hardware formats, the majority of current data extraction deals with extracting data from these unstructured data sources, and from different software formats. This growing process of data extraction from the web is referred to as Web scraping.
The act of adding structure to unstructured data takes a number of forms.
- Using text pattern matching such as regular expressions to identify small or large-scale structure e.g. records in a report and their associated data from headers and footers;
- Using a table-based approach to identify common sections within a limited domain e.g. in emailed resumes, identifying skills, previous work experience, qualifications etc using a standard set of commonly used headings (these would differ from language to language), e.g., Education might be found under Education/Qualification/Courses;
- Using text analytics to attempt to understand the text and link it to other information
Transform – The transform stage of an ETL process involves application of a series of rules or functions to the extracted data. It includes validation of records and their rejection if they are not acceptable as well as an integration part. The amount of manipulation needed for the transformation process depends on the data. Good data sources will require little transformation, whereas others may require one or more transformation techniques to meet the business and technical requirements of the target database or the data warehouse. The most common processes used for transformation are conversion, clearing duplicates, standardizing, filtering, sorting, translating and looking up or verifying if the data sources are inconsistent. A good ETL tool must enable building up of complex processes and extending of a tool library so custom user’s functions can be added.
Load – Loading is the last stage of the ETL process and it loads extracted and transformed data into a target repository. There are various ways in which ETL tools load the data. Some of them physically insert each record as a new row into the table of the target warehouse involving SQL insert statement build-in, whereas others link the extraction, transformation, and loading processes for each record from the source. The loading part is usually a bottleneck of the whole process. To increase efficiency with larger volumes of data it may be necessary to skip SQL and data recovery or apply external high-performance sort that additionally improves performance.
Any flaws in this complicated process transform into massive delays, which is why pre-extraction data profiling is vital. Growth of the database could be exponential – powerful central processing unit, vast disk space and huge memory bandwidth must be ensured.
Semantic Integration (from Wikipedia)
Semantic integration is the process of interrelating information from diverse sources, for example calendars and to do lists; email archives; physical, psychological, and social presence information; documents of all sorts; contacts (including social graphs); search results; and advertising and marketing relevance derived from them. In this regard, semantics focuses on the organization of and action upon information by acting as a mediary between heterogeneous data sources which may conflict not only by structure but also context or value.
In Enterprise Application Integration, semantic integration will facilitate or potentially automate the communication between computer systems using metadata publishing. Metadata publishing potentially offers the ability to automatically link ontologies. One approach to (semi-)automated ontology mapping requires the definition of a semantic distance or its inverse, semantic similarity and appropriate rules. Other approaches include so-called lexical methods, as well as methodologies that rely on exploiting the structures of the ontologies. For explicitly stating similarity/equality, there exist special properties or relationships in most ontology languages. OWL, for example has “sameIndividualAs” or “same-ClassAs”.
Ontology based Data Integration (a branch of semantic integration) involves the use of ontologies to effectively combine data or information from multiple heterogeneous sources . It is one of the multiple data integration approaches and may be classified as Local-As-View (LAV). The effectiveness of ontology based data integration is closely tied to the consistency and expressivity of the ontology used in the integration process.
Data from multiple sources are characterized by multiple types of heterogeneity. The following hierarchy is often used:
- Syntactic Heterogeneity: is a result of differences in representation format of data
- Schematic or Structural Heterogeneity: the native model or structure to store data differ in data sources leading to structural heterogeneity. Schematic heterogeneity that particularly appears in structured databases is also an aspect of structural heterogeneity.
- Semantic Heterogeneity: differences in interpretation of the ‘meaning’ of data are source of semantic heterogeneity
- System Heterogeneity: use of different operating system, hardware platforms lead to system heterogeneity
Ontologies, as formal models of representation with explicitly defined concepts and named relationships linking them, are used to address the issue of semantic heterogeneity in data sources. In domains like bioinformatics and biomedicine, the rapid development, adoption and public availability of ontologies has made it possible for the data integration community to leverage them for semantic integration of data and information.
Semantic integration, and the fact that it uses semantic ontologies should not be confused with the process of transforming data and its representation from the information level to the knowledge level (i.e., actually transferring the data into an ontology). The semantic approach is merely being used to try to ‘understand’ the labels on the data so that one taxonomy can be more accurately mapped into another taxonomy. The output of the process is still a good old fashioned ‘relational’ information-level database. This ‘semantic’ use of ontologies often causes confusion with Mitopia’s use of ontology which is far more fundamental and actually transforms the various unstructured or taxonomic sources into a unifying ontology, a fundamentally different, and far more powerful process where the output is totally stored, related, and accessed ontologically in a way that ‘relational databases’ cannot support, no matter how many layers of wrapping are applied.
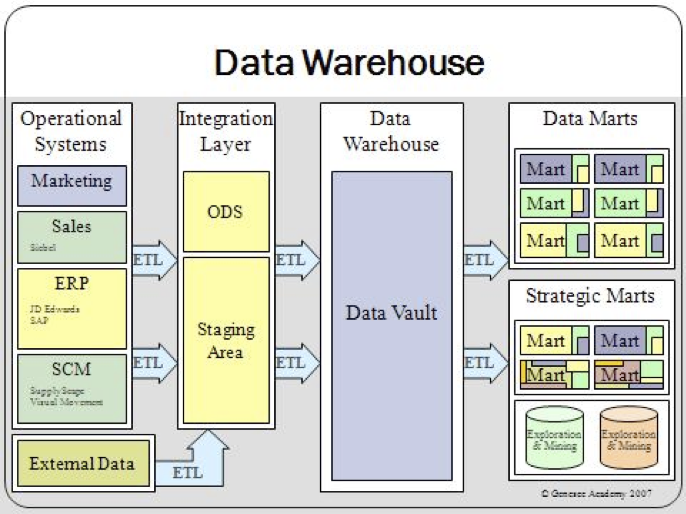 Data warehouses are optimized for speed of data analysis. Frequently data in data warehouses are de-normalized via a dimension-based model. Also, to speed data retrieval, data warehouse data are often stored multiple times—in their most granular form and in summarized forms called aggregates. Data warehouse data are gathered from the operational systems and held in the data warehouse even after the data has been purged from the operational systems.
Data warehouses are optimized for speed of data analysis. Frequently data in data warehouses are de-normalized via a dimension-based model. Also, to speed data retrieval, data warehouse data are often stored multiple times—in their most granular form and in summarized forms called aggregates. Data warehouse data are gathered from the operational systems and held in the data warehouse even after the data has been purged from the operational systems.
The diagram to the left shows the November 2010 Gartner ‘magic quadrant’ for the data integration tools market. Gartner estimates a market of approximately $2.1 billion by 2014. Leaders in the field include Oracle, SAP, IBM and Informatica. This entire market is based on relational (or object relational) databases, that is information-level systems, there is as yet no sign of tools for the much harder task of transforming and integrating taxonomic and/or unstructured data directly into an ontology (as is the case for MitoMine™). This is unsurprising since, other than Mitopia®, there exists as yet no database technology that is directly built on ontologies, despite the existence of the misleading term “ontology-based databases” (which actually means systems where conventional databases contain both the ontology definitions and the data).
Before we look at MitoMine™ itself, we will first examine the earlier ETL technology it replaced within the Mitopia® architecture which was known as the ‘Populator’. The Populator was a classical approach to the ETL problem and was in most regards very similar (though simpler) to the commercial ETL tools available today. Like them, the Populator was based on the premise that a conventional database (at the time Oracle RDBMS) is the ultimate repository for persistent data. By looking at the Populator capabilities we can simultaneously illustrate the approach of conventional ETL tools and the problems with these approaches, as well as show how radically the current Carmot/MitoMine™ heteromorphic language approach differs from conventional ETL.
The Classical ETL Solution – The Populator
 |
| Data Integration – Solving the problem the old way |
The Populator program was part of the Mitopia® Database Subsystem architecture prior to the wholesale replacement of the entire database subsystem by the MitoPlex™/MitoQuest™ layers. In those days, the architecture of the database subsystem looked roughly as shown below.
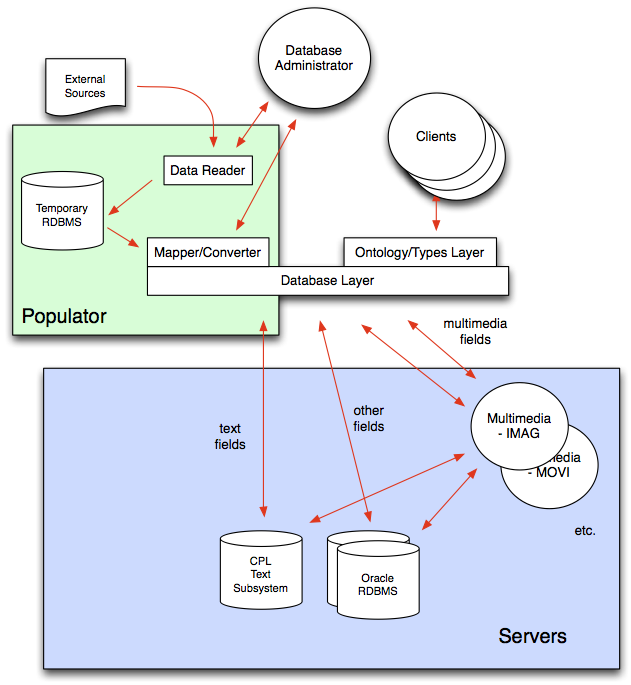
The client code accessed and manipulated data through the ontology/types layer just as it does today, however, because the ontology had to be translated into the needs of existing database technologies, immediately below the types layer, the database subsystem code was responsible for routing all text fields to/from the Callable Personal Librarian (CPL) text server, all multimedia fields to/from the appropriate Mitopia® multimedia server(s), and all other fields to/from the Oracle RDBMS. In other words, this arrangement was a classic systems integration approach to providing a ‘federated’ database so that the limitations of the RDBMS could be overcome by handling those areas through custom servers. This type of arrangement has many problems with scaling, not the least being the ‘join’ problem caused by combining the hits from the various container types. In this arrangement, the Populator (like today’s classical ETL approaches) sat directly on the database layer, that is it circumvented the ontology layer in order to directly access knowledge of database tables etc.
The Populator was split into two phases, both used solely by the system Database Administrator (DBA). The first phase, called the Data Reader (DR) read from external sources and saved its output into intermediate storage (a temporary relational database). This is much the same as the ‘Extract’ phase of today’s ETL tools. The second phase was called the Mapper/Converter (M/C) and functioned in a manner exactly analogous to the Translate and Load phases of a classical ETL tool, resulting in the final data passing through the database layer and into the final system servers where it could be accessed and searched by client code.
According to the old Populator manual:
Data reading from source data files may take up to three hours; population by the Mapper Converter may take up to two days. Population time is a function of the size and format of the raw data and of the complexity of the mapping/conversions and data destination structures, all of which can be very different for each population process.
The Data Reader
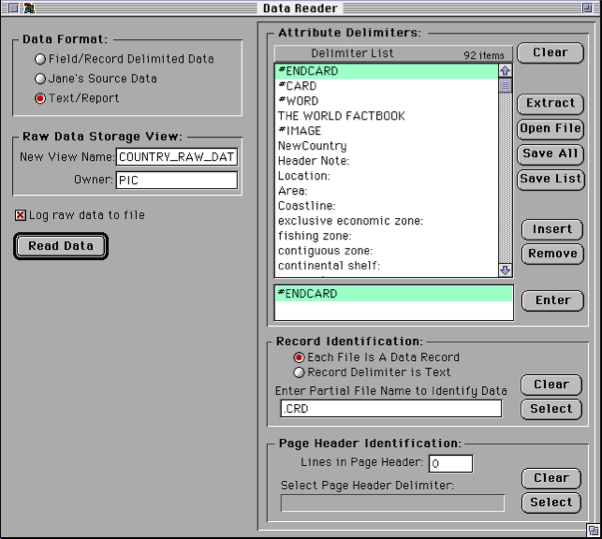
The data reader was capable of interpreting data in just three basic format classes:
- Field/Record Delimited Data
- Jane’s Source Data
- Text/Report
Right here we see a problem! Firstly, there are only three basic supported format groups (despite over 5 years of continuous Populator development at the time), and one of them is “Jane’s Source Data” which is an incredibly narrow source format (actually at the time the Jane’s data was delivered formatted using an SGML markup language). What this basically means is that under the hood in the DR, there was a lot of custom source-specific code to interpret the various complexities of the Jane’s data. This is a serious shortcoming as it means that when the source changes, the Populator code must change to match. Indeed at the time, new Jane’s data would come out each year and the Populator development team would spend much of their time each year extending the code base so that it could correctly handle the new format. This is clearly a bad approach for any system that hopes to be rapidly adaptive in the face of change. This design failing was the main reason for the demise of the original Populator approach. The other two selectable source formats were more generalized and capable of handling a fairly wide range of simple data formats.
The screen shot above shows the opening DR window which allows selection of the source type followed by setup of the basic criteria depending on the source type. In the case shown, the “Text/Report” type allows specification of a set of ‘delimiter’ patterns that can isolate chunks of the text within a document that are associated with the pattern.
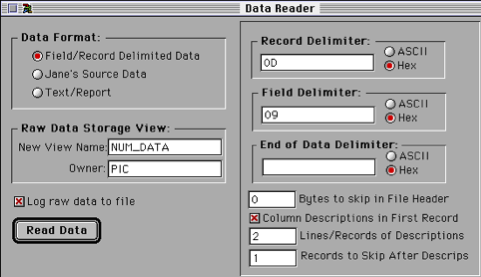 Other detailed tools were provided to handle file/record delimited data as illustrated to the left. The result of all the selections made within the DR dialogs was to initiate an extraction run that resulted in the creation of a temporary database where the table names were driven from the extracted raw data ‘chunks’. This temporary database formed the input source for the Mapper/Converter (M/C) phase.
Other detailed tools were provided to handle file/record delimited data as illustrated to the left. The result of all the selections made within the DR dialogs was to initiate an extraction run that resulted in the creation of a temporary database where the table names were driven from the extracted raw data ‘chunks’. This temporary database formed the input source for the Mapper/Converter (M/C) phase.The Mapper/Converter
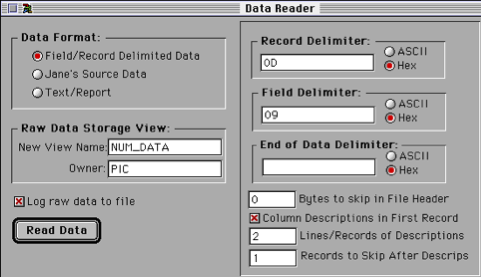
The M/C phase essentially allowed the user to map the contents of the various fields in the extracted raw temporary database to the final database fields while choosing one or more operations to perform on the text/data as the mapping took place. This direct approach circumvented the ontology/types layer at the time. As one can imagine, the process of setting up a complete M/C specification was time intensive for any non-trivial source, and in operation the M/C was extremely slow since each atomic operation performed on any ‘chunk’ involved communications with two distinct databases. Thus the multi-day run time quoted for any (at the time) complex source such as the World Fact Book. By contrast now, the end-to-end MitoMine™ ingestion and persisting for the latest WFB takes a matter of a few minutes, while providing infinitely more fine grain control, being easily adaptive to change, and without violating the ontology abstraction layer.
 Despite having an elaborate GUI with large numbers of controls and processing options (the Populator screen shots are from the classic MacOS version of Mitopia®, they pre-date OS-X), the truth of the matter was that the Populator was difficult to use and learn, slow and error prone, and required constant maintenance and upgrades in order to handle the continuous stream of issues that come up as any new source is added or as old sources change format. Eventually the program fell into disuse and was for a while replaced by a set of custom strategies each targeted at converting a particular source to some simple form that could be ingested directly. These custom strategies themselves proved un-maintainable and just as fragile as things changed. In the end, it was the huge and on-going effort required to ingest data into the Mitopia® system that lead to the decision to replace the entire ingestion path with a new approach tied intimately to the ontology and independent of the existence of a relational database.
Despite having an elaborate GUI with large numbers of controls and processing options (the Populator screen shots are from the classic MacOS version of Mitopia®, they pre-date OS-X), the truth of the matter was that the Populator was difficult to use and learn, slow and error prone, and required constant maintenance and upgrades in order to handle the continuous stream of issues that come up as any new source is added or as old sources change format. Eventually the program fell into disuse and was for a while replaced by a set of custom strategies each targeted at converting a particular source to some simple form that could be ingested directly. These custom strategies themselves proved un-maintainable and just as fragile as things changed. In the end, it was the huge and on-going effort required to ingest data into the Mitopia® system that lead to the decision to replace the entire ingestion path with a new approach tied intimately to the ontology and independent of the existence of a relational database.We will begin to examine that new approach in future posts.