In an earlier post (here) we introduced the knowledge pyramid and defined the various levels within it. Current software systems operate almost exclusively at the ‘Information Level’ (IL). The more sophisticated of those use what is called a ‘taxonomy‘ (from the Greek ‘taxis’ meaning to arrange or order) to organize database tables. Many (if not most) IL systems are simply ad hoc and do not use a formal taxonomy, indeed the use of taxonomies is currently considered a ‘forefront’ in database circles (see here).

Earlier posts have alluded to Mitopia’s use of an ontology (from the Greek ‘ont’ meaning to be). Ontologies are a higher level of organization than taxonomies and refer not only to the content of records, but more particularly to the nature of the relationships that can exist between records. A system based on ontologies operates at the ‘Knowledge Level’ (KL) rather than the IL like today’s systems. KL systems hold the potential to answer classes of questions that cannot be addressed by IL systems. In this post we will discuss some of the fundamental differences between Mitopia’s ontological approach and today’s bland taxonomic approach.
 As has been stated above, current generation software systems, databases, and design methodologies, are all based on an information level or taxonomic approach. Mathematically, a taxonomy is a tree structure (or containment hierarchy) of classifications for a given set of objects. Taxonomies are constrained to this tree form, and any references between one node in the tree and another that is not either a parent, a sibling, or a child is ‘out of scope’ for a pure taxonomic system. Of course it is these arbitrary connections that contain most of the interesting information in the real world, not just the contents of record fields.
As has been stated above, current generation software systems, databases, and design methodologies, are all based on an information level or taxonomic approach. Mathematically, a taxonomy is a tree structure (or containment hierarchy) of classifications for a given set of objects. Taxonomies are constrained to this tree form, and any references between one node in the tree and another that is not either a parent, a sibling, or a child is ‘out of scope’ for a pure taxonomic system. Of course it is these arbitrary connections that contain most of the interesting information in the real world, not just the contents of record fields.
If we look at the technological underpinnings of today’s information systems, at the base level we can identify just two technologies that are fundamental to virtually all that we do in these systems, namely object oriented programming, and relational databases. Object oriented programming (OOP) languages are frame-based and taxonomic in nature, that is, the focus is on creating classes and sub-classes with which to inherit functionality and fields. The OOP programming languages themselves provide no support for creating connections between instances other than the basic pointer mechanism which means that there is no systematic support for knowledge level operations. Even the pointer mechanism can only be used within the current process, and so to persist any relationship beyond the current program run, the problem must generally be offloaded to the database using an entirely different and incompatible programming model (SQL). See the previous post (here) for more on this issue.
 A relational database (see here) can be visualized as a collection of tables, each of which comprises a number of columns and a number of rows. The tables are called relations, and the rows are called tuples. Each relation records data about a particular type of thing such as customers, products, or orders, and each tuple in a relation records data about one individual instance of the appropriate type. The names of each relation’s columns must be set up by a database administrator before the database is first set up. Thereafter, new tuples can be added and existing tuples can be altered or deleted to reflect changes in the data. The SQL language provides the interface between code in an application program and the operations or searches that it wishes to do on the tuples of the database. In every relation, one or more columns together are designated as the primary key which can be used elsewhere to reference individual tuples. There must be exactly one primary key, no more, no less. A relation may also contain one or more foreign keys, which are basically references to the primary key of some other relation and it is through this mechanism that it is possible to link one table with others thus creating a complete cross-referenced database.
A relational database (see here) can be visualized as a collection of tables, each of which comprises a number of columns and a number of rows. The tables are called relations, and the rows are called tuples. Each relation records data about a particular type of thing such as customers, products, or orders, and each tuple in a relation records data about one individual instance of the appropriate type. The names of each relation’s columns must be set up by a database administrator before the database is first set up. Thereafter, new tuples can be added and existing tuples can be altered or deleted to reflect changes in the data. The SQL language provides the interface between code in an application program and the operations or searches that it wishes to do on the tuples of the database. In every relation, one or more columns together are designated as the primary key which can be used elsewhere to reference individual tuples. There must be exactly one primary key, no more, no less. A relation may also contain one or more foreign keys, which are basically references to the primary key of some other relation and it is through this mechanism that it is possible to link one table with others thus creating a complete cross-referenced database.
It is important to note that the term “relational” is somewhat of a misnomer since it refers to the mathematical concept of a relation, it does not imply that relational databases are actually designed to represent the relationships between different things. In relational databases, relationships between things must be inferred by someone (or some code) with sufficient knowledge of the database schema. In real life situations, tables can contain thousands of columns each added by different programmers with different naming conventions and agendas, and thus it is often very difficult to determine what relationships exist within the data, and is certainly not something that can be accomplished by any generalized piece of code. Addressing this clutter is part of the motivation for database taxonomic approaches.
Contrary to its name, the relational model makes it extremely difficult to represent relationships between different things, and almost impossible to dynamically create new types of relationships as they are discovered in incoming data. Since a knowledge level system is focused primarily on the relationships between things, we can effectively rule out the use of relational databases to implement such a system.
The ontological approach applies not only to where a given item can be found and what ancestral types it derives from, but far more importantly, it determines the very nature and format of the ‘fields’ within any given record. In a taxonomic database (e.g., a relational database) or information repository, the system implementer is free to define a field in isolation from any consideration of the rest of the database structure. In an ontological database, where the focus is not only on the content, but more importantly, on the interconnections, this is no longer the case.
 For example if one had a database field for a person’s titles (e.g., Professor or President), in a classic taxonomic database or system one would simply create a text field called “titles” and rely on user’s latent understanding of such concepts to ensure that they entered the appropriate text (which would to the system have no inherent ‘meaning’). In an ontological database, where meaning and connections are the focus, one is forced to ask “what is a person’s title…what does it mean?” If one thinks about it in these terms, it is clear that a title represents a three way relationship between an individual (the incumbent holder of the title), the organization that confers that title upon that individual, and a particular title (e.g., “Professor”) which has some inherent meaning in a wider scope such that use of the title immediately conveys meaning in some larger context. Coveting and acquiring titles is fundamental to the character of many people and tells us much about them. The title explicitly defines rank and privilege within the conferring organization, but more importantly the title, size, and importance of the conferring organization strongly impacts the behavior and allegiances of the individual and his social status and interactions with others. There is much to be understood from the simple nature of the title web.
For example if one had a database field for a person’s titles (e.g., Professor or President), in a classic taxonomic database or system one would simply create a text field called “titles” and rely on user’s latent understanding of such concepts to ensure that they entered the appropriate text (which would to the system have no inherent ‘meaning’). In an ontological database, where meaning and connections are the focus, one is forced to ask “what is a person’s title…what does it mean?” If one thinks about it in these terms, it is clear that a title represents a three way relationship between an individual (the incumbent holder of the title), the organization that confers that title upon that individual, and a particular title (e.g., “Professor”) which has some inherent meaning in a wider scope such that use of the title immediately conveys meaning in some larger context. Coveting and acquiring titles is fundamental to the character of many people and tells us much about them. The title explicitly defines rank and privilege within the conferring organization, but more importantly the title, size, and importance of the conferring organization strongly impacts the behavior and allegiances of the individual and his social status and interactions with others. There is much to be understood from the simple nature of the title web.
Thus in an ontological system, a title must be represented as a three-way linking record between a conferring organization, a person, and a constrained domain of generally understood titles conveying some functional authority. Not only that, but we must consistently handle the ‘echo’ fields implied by such relationships in the other types involved. Thus it is clear that the concept of people having titles implies that organizations must have something like a ‘key personnel” field which provides the reverse connection to the incumbents through the linking record. It should be obvious that this is fundamentally a more correct and certainly a more ‘meaningful’ and thus computable representation of what a title represents, and yet few if any current systems go even this far, so such systems can never represent knowledge, only information. Thinking of information in these terms is rare, indeed software courses teach the exact opposite localized taxonomic approach, and our databases and tools provide only for such localized thinking. It is hard, very hard, to implement systems that truly operate at the knowledge level, and it requires almost a philosophy degree to think this way, which explains why we don’t see such systems out there.
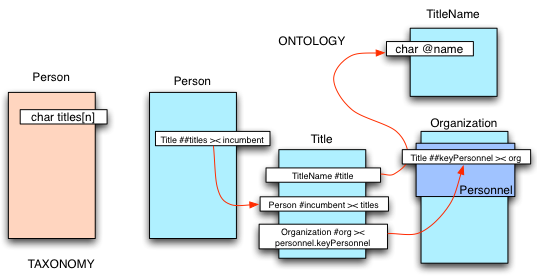 |
| Taxonomy vs. Ontology (see here for meanings of symbols) |
Clearly also, this is not the way people normally seek information, so any web site (or other digital information repository or source) externally organized in this ontological manner would certainly go out of business in short order. Many people find such an ontological approach unnatural because it challenges their own poorly thought-out models of what things mean in a way that a bland taxonomic approach does not, since it leaves the interpretation of meaning up to the reader. For these reasons, resistance to ontological thinking is widespread and the approach clearly faces significant educational hurdles. However, the truth is that though we might shy away from these concepts when they are made explicit in our communications, the human mind at its lowest, often subconscious, level, operates exclusively by means of ontologies.
 The process by which a child grows up and experiences the world is one in which that child builds mental models (or ontologies) of how things in the world work and interrelate, and refines these models to the point where they become powerful enough to allow that person to make informed and weighted decisions on what actions to take in any given situation and what the possible consequences might be (by modeling the ontologies of others). It is these ontologies that allow us to understand new and unfamiliar information by converting it to parallels or transient metaphors based on existing internal models and the connections between them. It is our internal ‘ontologies’ that drive us to seek particular answers, but our spoken language and other communication techniques require us to translate these into the taxonomy of others, who cannot possibly know or understand our internal models, for the purposes of communicating. Human beings, the consummate communicators, do this so well that most of us are completely unaware of our internal ontology unless closely questioned by experts, a thing that rarely happens unless we visit a psychiatrist or are suspected of a crime. Exposing our ontology in communication leads to conflict and we are all loath to do so.
The process by which a child grows up and experiences the world is one in which that child builds mental models (or ontologies) of how things in the world work and interrelate, and refines these models to the point where they become powerful enough to allow that person to make informed and weighted decisions on what actions to take in any given situation and what the possible consequences might be (by modeling the ontologies of others). It is these ontologies that allow us to understand new and unfamiliar information by converting it to parallels or transient metaphors based on existing internal models and the connections between them. It is our internal ‘ontologies’ that drive us to seek particular answers, but our spoken language and other communication techniques require us to translate these into the taxonomy of others, who cannot possibly know or understand our internal models, for the purposes of communicating. Human beings, the consummate communicators, do this so well that most of us are completely unaware of our internal ontology unless closely questioned by experts, a thing that rarely happens unless we visit a psychiatrist or are suspected of a crime. Exposing our ontology in communication leads to conflict and we are all loath to do so.
Thus we can say that in a very real sense, an ontology is the more fundamental, and ultimately more useful way, of organizing information for connections and computability, and yet there are almost no information systems in existence that adopt this approach to data and its organization. This is either because of the difficulty of bridging the communication gap with the user, or more likely, simply a matter of convenience or lack of mental rigor on the part of our software vendors. The fact of the matter is, that only an ontology based software architecture can serve as a generalized platform on which to build true knowledge level systems, since that ontology (and the technology to define and access it) is, as we ourselves show, the key to spanning and unifying diverse sources. It is this lack of a meaningful underpinning that gives rise to the belief that computer systems are stupid, and will never rise to the level of comprehension and flexibility exhibited by the human mind. For existing systems this belief is well-founded. Clearly the goal of future systems must be, if not to rise to the level of human understanding, then at least to rise to a sufficient level of understanding that these systems can serve to augment human beings and act as their proxies in the torrent of information (see here), drawing those things that seem most relevant to the attention of the appropriate person. Thus not only must the system operate ontologically, but it must also express that ontology (perhaps filtered) to the user so that he can frame his interests and desires in a form that the system can reliably, and as far as possible, unambiguously automate.
Mitopia® is fundamentally a suite of technologies necessary to rapidly build systems based on an application (and possibly user specific) configurable ontology, layered on top of a more fundamental ontology designed to understand the nature of the world and to facilitate meaningful exchange of knowledge between systems. We have stated above that information organized as an ontology is inherently more ‘computable’ and meaningful than information stored in taxonomies, but why and how is this so? To illustrate this with a trivial example, let us return to the question of how a person’s title(s) are represented in the two approaches. In the taxonomic approach, the ‘titles’ field contains a presumably comma-separated list of titles (hopefully spelled correctly!). It is basically free-form text. Now imagine we wish to create an analytical process that operates on the data, and is designed to extract some kind of predictive model for the probable habits, lifestyle, and social impact of a set of persons in storage.
In a taxonomic system, the best we could do is create a process with its own internal list of common titles and associated with each title we might define some sort of weighting to indicate certain social characteristics that such a title might imply. Of course, our title list would only be partial, would not adapt to new input, and we could hope at best to recognize a tiny fraction of the actual titles. More importantly, since there is no relationship between the titles field and the organization that confers it, we cannot in any real sense evaluate the significance of the title. For example, the President of the United States and the President of a one-man corporation are indistinguishable by taxonomy, the title “President” thus becomes meaningless. The same is actually true of almost all titles, so in fact the best our process could do in this situation, is make some kind of guess as to the nature of the job that person had, but not in any way the significance, allegiances or other implications. Titles themselves are used inconsistently and thus require context. For example the title Secretary generally connotes a low paid clerical worker with little or no authority. But consider the Secretary of State, or the Secretary of Defense.
In an ontological system, the situation is quite different. Firstly, our process needs no disconnected internal list of titles since it can retrieve the current complete list simply by accessing persistent storage. The fact that the titles field is implemented by reference also removes all issues with misspelling, updates and consistency between the reference field and the referenced items (via the echo fields). Also now that there is an ontological type to hold title names, we have a place in persistent storage to put the fields defining any characteristics or information associated with particular titles. This means that not only is this information available to our analysis process, it is also available to all other algorithms in the system and indeed can be viewed and/or updated directly by any system user. It is clear that we are breaking down the stovepipe ‘hidden’ nature of the algorithm that our taxonomic process would have exhibited, and instead are publishing it in ontological form for all to see (or ignore).
Moreover, since the title link is between an individual and an organization, we can now examine the organization to see what it is, and how big it is, and thereby we can get a far more accurate measure of the significance of each particular use of a given title such as “President”. We will no longer confuse the President of the United States with just another guy on the street. Furthermore, if we wish to know more about the job a person might do, we can examine the conferring organization, perhaps we know its SIC or NAICS code, or perhaps we have a list of ontologically described products. We can probably examine the number of employees, or the annual income, and thereby compute the social significance of the particular title when used to interact with outsiders. From this we may be able to compute certain constraints on that individual’s public positions and behavior. We can probably also discover or approximate the individual’s income and living standard, and we can certainly track allegiances. The list of possible computations that such a process might do based solely on the ‘titles’ field could be quite extensive.
Now imagine this same improvement in computability repeated for all the possible fields in a Person record (perhaps hundreds) and the various institutions, persons, possessions and insights they might lead us to. Then further imagine a suite of similar processes each using ontologically-based algorithms to establish some kind of quantitive or qualitative measure of understanding, all of which can share in drawing an analytical conclusion, and we begin to see the difference in power between the two approaches. More importantly, in the ontology approach, since algorithms can be written to operate on higher level types (e.g., entity) from which specific types derive, the algorithmic smarts can be re-purposed easily and, if well written, may be largely independent of the specific ontology and certainly should be common across the underlying base ontology.
Unfortunately the word ontology has now been completely hijacked in the computer field to mean ‘semantic ontology’ (see here), that is an ontology of language and sentence understanding. In pure semantic ontology, everything is simply a “document” together with a set of graphs representing the “meaning” of the sentences within the document. Specialized AI-style code is required to manipulate these graphs and tie them to the source documents, and the utility of such a system is restricted to querying based on the graphs that are present in those documents. The other major shortcoming of this approach is that while it deals well with document understanding, it cannot represent or leverage in any meaningful way an encyclopedic store of data derived from external databases in order to improve the power of its analysis.
To add more power, one must add more semantic knowledge (or rules) to the ontology itself. This is why researchers have spent so many man-years developing more and more elaborate semantic ontologies in order to improve performance in sentence understanding. Many such projects can be found on the web. Moreover, such ontologies provide no means to unify information from divergent sources into an explicit representational form that can serve as a generalized platform on which all computations and data accesses can be built. Only the semantic graphs are provided, and thus it is meaningless for example to discuss the use of semantic ontologies to represent and handle business process since there is no support for anything but the manipulation of semantic graphs in text.
The
semantic web, which is largely based on
OWL, seeks to extend the semantics into the
XML tags associate with the text on the web. In the previous post (
here) we examined the semantic web and its use of ‘semantic ontologies’.
Future posts will contrast that with the Mitopia® approach in order to clarify exactly what we mean by the word ontology in a Mitopia® context.


 A relational database (see here) can be visualized as a collection of tables, each of which comprises a number of columns and a number of rows. The tables are called relations, and the rows are called tuples. Each relation records data about a particular type of thing such as customers, products, or orders, and each tuple in a relation records data about one individual instance of the appropriate type. The names of each relation’s columns must be set up by a database administrator before the database is first set up. Thereafter, new tuples can be added and existing tuples can be altered or deleted to reflect changes in the data. The SQL language provides the interface between code in an application program and the operations or searches that it wishes to do on the tuples of the database. In every relation, one or more columns together are designated as the primary key which can be used elsewhere to reference individual tuples. There must be exactly one primary key, no more, no less. A relation may also contain one or more foreign keys, which are basically references to the primary key of some other relation and it is through this mechanism that it is possible to link one table with others thus creating a complete cross-referenced database.
A relational database (see here) can be visualized as a collection of tables, each of which comprises a number of columns and a number of rows. The tables are called relations, and the rows are called tuples. Each relation records data about a particular type of thing such as customers, products, or orders, and each tuple in a relation records data about one individual instance of the appropriate type. The names of each relation’s columns must be set up by a database administrator before the database is first set up. Thereafter, new tuples can be added and existing tuples can be altered or deleted to reflect changes in the data. The SQL language provides the interface between code in an application program and the operations or searches that it wishes to do on the tuples of the database. In every relation, one or more columns together are designated as the primary key which can be used elsewhere to reference individual tuples. There must be exactly one primary key, no more, no less. A relation may also contain one or more foreign keys, which are basically references to the primary key of some other relation and it is through this mechanism that it is possible to link one table with others thus creating a complete cross-referenced database.