 In this post I’d like to look at how the KP-OODA loop realization may invalidate current thinking on how to write software requirements. Other posts have, and will, deal with software design and operational matters.
In this post I’d like to look at how the KP-OODA loop realization may invalidate current thinking on how to write software requirements. Other posts have, and will, deal with software design and operational matters.
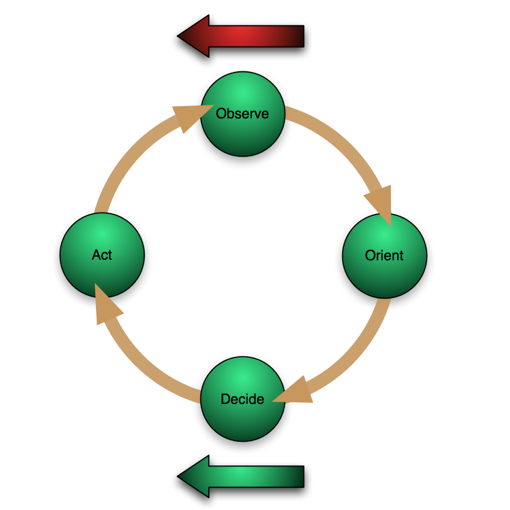
In the previous post I described the OODA loop and introduced a new concept created by combining this loop with the knowledge pyramid insights that detail the level of operations that must be supported for each step in the loop. The result is the knowledge pyramid OODA loop or KP-OODA shown to the left. The KP-OODA loop defines the data organization levels that must exist for any software system designed to augment and support the full organizational decision cycle. Awareness and understanding of this loop must be woven deeply into every step of the software life cycle if the final system is to fully meet user goals and stand up to the erosive effect of change over time.
There is a vast amount of literature on the software requirements process, as well as a plethora of government specifications dictating how to write software requrements for government related software. Those of us who have worked in this realm are painfully aware of all these standards. For discussion purposes, we’ll simplify things, and say that a basic Software Requirements Specification (SRS) usually has the following major sections:
- Introduction
- Purpose
- Definitions
- System overview
- References
- Overall description
- Product perspective
- etc.
- Constraints, assumptions and dependencies
- Specific requirements
- External interface requirements
- Functional requirements
- Performance requirements
- etc.
- Software System attributes
- Reliability
- Availability
- etc.
- Other requirements
The bulk of these sections make a lot of sense, and are required to define the environment and context within which the software must operate. However, the fact is that for any large system, the vast majority of the final document, unsurprisingly lies within the ‘Functional requirements’ section which is where we describe “what the software must actually do”.
What happens in any complex system is that multiple experts in various technical areas meet with assorted customer representatives over a period of time in order to tease out the most complete list of requirements practical. When the process is complete, the requirements output from all groups is integrated and rationalized, often using semi-automated requirement ‘dredging’ tools to assist the process.
When the agreed upon requirement set is achieved, they are organized into perceived ‘functional areas’ within the software architecture (e.g., database requirements, security requirements, user interface requirements, etc.). Ultimately a large SRS document detailing all the requirements (with requirement strength indicated by key words such as ‘shall’, ‘should’, ‘may’, and ‘will’) is generated, with large numbers of sub-sections under the ‘Functional Requirements’ heading, each of which represents a ‘functional area’, and is further broken down, ultimately to the specific agreed requirements which must be tracked.
This document is then parceled out to various development groups responsible for one or more functional areas, and they implement their portion(s) of the requirements and
unit test to ensure correctness. These components are then assembled and go through
integration testing to ensure they work correctly together. Finally the system is delivered and a formal
acceptance testing process takes place on-site to ensure that all requirements are met.
The actual development process is of course considerably more complex and iterative than the linear sequence described above, and there are many
software development methodologies intended to make it work better. All have their own strengths and weaknesses. Which one is appropriate depends on the specifics of the project.
The problem with all this is that ultimately as we have said earlier, the system is designed to support the decision cycle in some way. Simple systems may focus on just one aspect of the OODA loop (e.g., a weapon system is fundamentally part of ‘Act’), but truly complex systems ultimately have one purpose, and one purpose only, which is to facilitate some kind of complete decision cycle. Seldom is anything as abstract as ‘decision support’ likely to receive top billing in a system description, and this is a mistake.
With the SRS document that results from our standard approaches, there is no mention of a decision cycle, and it is very difficult for requirements buried down within the ‘Functional Requirements’ section to be tied to one. Without this tie-in, requirement importance to the ‘whole’ is subjective, and time and resources allocated to their development cannot be weighted appropriately or adaptively as project realities (i.e., schedule and resources) evolve and tradeoffs must be made.
The result is often a system that meets its requirements to the letter, and yet the customer is not happy, and finds that the system doesn’t help raise the organizational effectiveness as intended, even if it does exactly what was asked. Often the reverse may be true due to system complexity.
Mitopia® is an extremely complex end-to-end software architecture designed from the outset for adaptability. Consequently, it was a natural thing for us to extend the realizations embodied in the KP-OODA loop into the very software requirement process itself, not just the software design. This resulted in a unique structure to our internal MitoSystems software requirements and long term architecture planning document. This forward looking, rolling 10-year plan is referred to internally as the ‘Future Intelligence System Requirements’ document or ‘FIS’ for short. It is our self-imposed internal SRS/SDS, and it is our way of internally setting priorities and tracking progress. I would contend however that this same methodology could be beneficially applied in specifying virtually all large software systems.
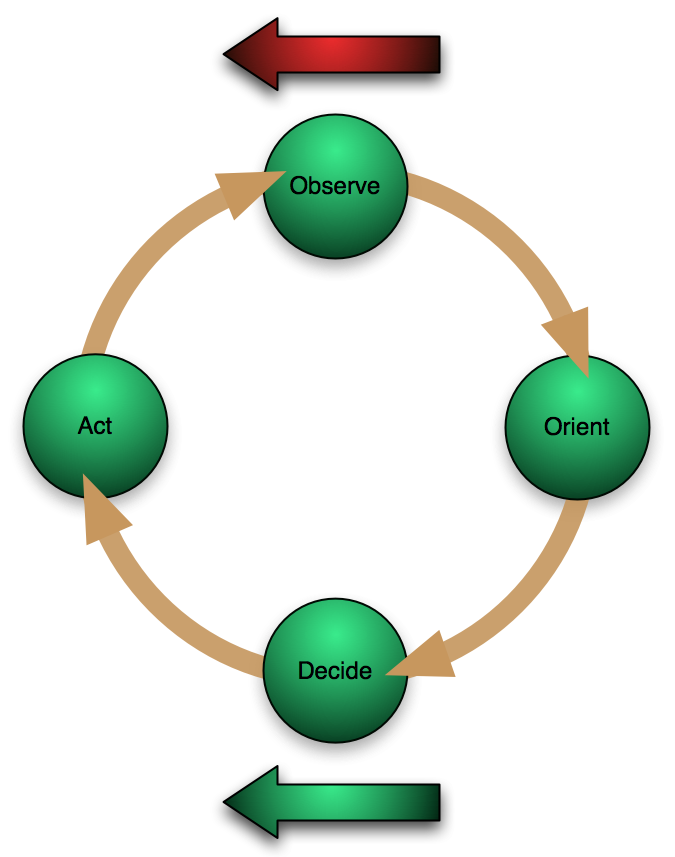 |
| An extended OODA loop used to define requirements |
The image above shows the modified OODA loop we use to categorize and organize requirements. You will note that in addition to Boyd’s standard OODA loop there is a left facing red arrow above, and a left facing green arrow below. The red arrow (which opposes the direction of the cycle) is referred to as ‘
Friction‘, the green arrow (which aligns with the cycle) is referred to as ‘
Torque‘. From a requirement categorization perspective we can say:
OBSERVE – Requirements in this category relate to obtaining and ingesting information from the outside world and persisting it for subsequent use. Front end data mining and ingestion requirements belong in this category.
ORIENT – Requirements in this category relate to taking captured information and searching, sorting, and organizing it in order to determine the current situation or the answer to a simple question. Simple database query is an example of this category.
DECIDE – Requirements in this category relate to activities that build on the current situation as determined during the Orient stage to provide more sophisticated integrated insights into what is going on in order to decide on actions. From the user perspective, example activities might be sophisticated visualizers and link analysis. Collaboration between users may also be part of the decision process.
ACT – Requirements in this category relate to the actions performed within or external to the system in order to communicate the results of a decision/recommendation arrived at during the Decide phase. Examples of this category might be report generation, messaging etc. Communications with or impacts on other entities or systems might also fall in this category.
TORQUE – Requirements in this category represent those capabilities that are pervasive throughout the system, and without which other steps may not operate. The effect of these facilities is to speed up the overall system OODA loop. This category also includes requirements that relate to such things as the physical environment that cannot be directly related to any other system area.
FRICTION – This grouping represents those requirements areas that must be provided, but which may actually contribute to slowing of the OODA loop. The best example of this category is Security Requirements. Implementations in this category should aim to minimize OODA impact while fully meeting the requirement.
These self explanatory categories give us a framework within which we can assign any and all functional requirements for the system we are specifying.
 |
| An ‘Observe’ requirements page within the FIS document |
The image above shows one requirements page from the FIS document. Since this document contains proprietary and forward looking information, I have chosen a long completed requirement ‘Distributed Persistent Storage’ from early in the ‘Observe’ section. The complete document is hundreds of pages long. As can be seen the requirement page contains a broad discussion of the requirement domain, and then a set of detailed requirements, given in standard requirement specification language, and each assigned successive letters of the alphabet. The top level requirement is assigned a requirement ID (RID), in this case FIS-OB-100 (the OB stands for ‘Observe’). As can be seen the ‘Observe’ node in the OODA diagram in the top right hand corner is highlighted. The requirement priority (in this case ‘high’) is determined largely by how important the requirement is to the ultimate goal of system adaptability. Many early requirements (such as this one) form the prerequisites for later more complex requirements and this may also increase their priority.
Unlike a pure SDS, because the FIS is an internal document, we use it not only as a requirements specification document, but also at the same time as a means for detailing and evaluating the anticipated solution, and tracking progress and/or completion. For this reason, when you open up the document the left hand page shows the requirement (as above), the right hand page shows the corresponding implementation details. This allows easy tracking directly between requirements and implementation on the same page of an opened document. The implementation page corresponding to the requirement above is shown below:
 |
| The corresponding implementation page |
The first thing to notice is that in the ‘Req.’ column you can see the beginning of each line in the sub-requirements which allows one to easily align the text of the implementation ‘Details’ column with the sub-requirement it pertains to.
The upper portion of the implementation page contains a textual description of the intended (or in this case the actual) implementation together with any significant system-level inputs and outputs and also any dependencies on other requirements. The ‘Details’ column contains a description of how each sub-requirement will be implemented. If the implementation is complete this may be no more than ‘Done’ as in the example above. The ‘State’ column, which is also aligned with each sub-requirement indicates the state of completion of the sub-requirement according to the following codes:
- D – Done. The code is core Mitopia® code and is presently written, tested and complete.
- C – Configuration. The requirement is customer specific and is fully supported via one or more elements of the Mitopia® customization layer (e.g., MitoMine, dictionaries, etc.).
- N – Near Term. The requirement could be implemented as part of a near-term delivery, that is within 4 months of customer project start (given sufficient manpower).
- M – Medium Term. Anticipated time to deliver the requirement if selected for a given customer is within 12 months (given sufficient manpower).
- L – Long Term. The delivery time for the requirement if selected exceeds one year and may if fact be far longer.
The codes ‘D’ and ‘C’ are both considered complete and so we can see that the entire super-requirement in this case is essentially complete. The exception is [F] which is listed as ‘N’ and looking in the ‘% Complete’ box (which summarizes the degree of completeness of all incomplete sub-requirements on the page), we see that requirement [F] was 80% complete at the time of this FIS version.
The ‘Evaluation’ box contains the evaluation scores for the proposed (or actual) implementation where each score is out of 10, and the maximum total score possible is 100. The various axes along which an implementation can be scored are shown in the table. Full descriptions of how to score in each category are provided in the introduction to the FIS.
The existence of this document allows MitoSystems to evaluate new project proposals and to ensure that any new development aligns with the FIS, or if appropriate, the FIS is extended to include new thinking resulting from the project needs. In all cases, the meta-requirements of tight integration and layering with the Mitopia® architecture, and system adaptability in the face of change are considered uppermost in coming up with any new implementation plan.
What this document does is ensure that requirements and the corresponding implementation are always kept in context with the ‘big’ picture which as we have said is augmenting an adaptive organizational OODA loop. Additionally, the KP-OODA loop considerations as far as data organizational underpinnings are constantly kept frontmost. The effect is to curtail developer’s natural tendency to create personal code edifices which ultimately disrupt loop flow and limit adaptability. This in turn minimizes the time that must be wasted re-implementing sub-optimal solutions, and provides a continuous framework within which to tell if such a sub-optimal situation is emerging. The ultimate end point is the ability to deliver robust adaptive solutions to customer problems faster than others. The high risk of failure in such complex systems is thus mitigated.
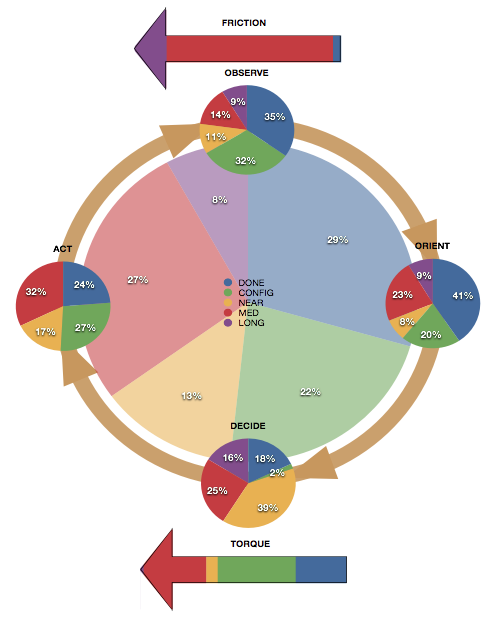 |
| Analysis of implementation state viewed at the decision cycle level |
The diagram above, taken from the FIS, is an illustration of the advantages of organizing requirements according to their OODA loop impact on the customer organization. This diagram shows the state of all FIS sub-requirements broken down into the completeness categories defined above. The center pie shows the overall state at the time. From this we see that of all requirements in the FIS, including those looking forward by 10 years or more, 51% are complete (either ‘Done’ or ‘Config’). However, if we examine the pie charts for each individual node in the loop, we see that the ‘Observe’, ‘Orient’, and ‘Act’ pies show similar or higher levels of completeness but the ‘Decide’ pie shows only 20% completeness. In other words the customer’s complete OODA loop tempo may be constrained by the ‘Decide’ step, and so we should place heavy emphasis on those requirements in order to bring the loop back into balance.
In fact, the situation is more complex because in our open-ended forward looking internal plan, most of the really ‘out there’ requirements, some of which we have absolutely no idea how to do at this time, can be found in the ‘Decide’ step. Exotic visualizers, immersive reality, AI, and all kinds of other research directions are in this step, and it is the incomplete (or more often un-started) nature of these requirements that makes ‘Decide’ seem out of balance with the rest of the loop. In an actual constrained customer requirement set, imbalance shown on this diagram would however be a real problem in terms of customer ‘happiness’ with the delivered results.
Another area that is clearly lacking according to this diagram is the ‘Friction’ arrow which shows that almost all requirements are still in the ‘medium term’ category. Most of these requirements pertain to handling security issues within a highly interconnected ontology driven environment. Current security methodologies are predicated on isolating access to portions of the data, but this is in direct conflict with a system where the major benefit is obtained precisely because all data is so richly and pervasively interconnected. For this reason we have in the past tended to emphasize isolated systems or ‘flat’ security models, and so delay addressing these highly complex issues. Nonetheless, one day a project will inevitably force renewed focus on the ‘Friction’ component, and we will know from the FIS what this involves and the time and effort it will require.
In conclusion the requirement specification and analysis methodology described in this post should I believe be part of any complex software system designed ultimately to augment organizational decision cycles. Failure to do so raises the chances of the final delivered product not meeting actual, but probably unstated, customer OODA loop requirements.