 In this post we will give a basic overview of the process Mitopia® goes through when matching and merging newly created records from MitoMine™ (or elsewhere) with the existing records in persistent storage.
In this post we will give a basic overview of the process Mitopia® goes through when matching and merging newly created records from MitoMine™ (or elsewhere) with the existing records in persistent storage.
In order to be successful in creating effective and correct mining scripts, it is absolutely essential that the script writer have a full understanding of the logic used by MitoMine™ and Mitopia® in general as far as merging and matching mined records both during the mining run itself, and also as the mined results are merged with all existing knowledge held in persistent storage. If this process is not understood, the danger is that mined data will not correctly merge with existing knowledge, and as a result will be contradictory or at best disconnected, and thus useless in assisting the analytical process. Much of the discussions that follow below pertain more to Mitopia® as a whole than they do to MitoMine™ specifically, however, because this logic is so critical to effective mining, a detailed discussion before we discuss more complex topics is appropriate.
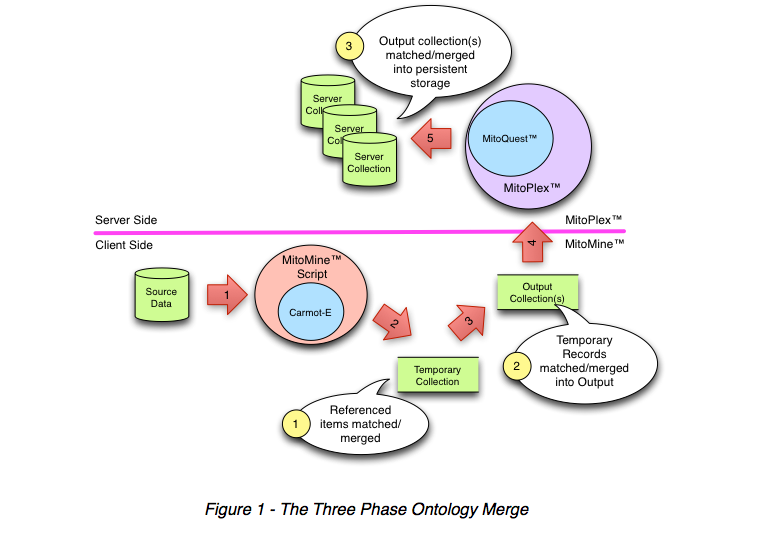 Figure 1 above depicts the standard process of merging and matching that all ingested records within Mitopia® go through (by MitoMine™ or otherwise) as it is passed to persistent storage and becomes part of the permanent system record. The process is referred to as the 3-phase ontology merge. The three basic merging steps are completely controlled through the system’s current Carmot ontology, and are always the same (labelled 1 to 3 – yellow circles) in the diagram. Two distinct heteromorphic language suites, MitoMine™ and MitoPlex™ are involved in the merging sequence, and both suites use an endomorphic language tied intimately to the Carmot ontology (Carmot-E for MitoMine™ and MitoQuest™ for MitoPlex™).
Figure 1 above depicts the standard process of merging and matching that all ingested records within Mitopia® go through (by MitoMine™ or otherwise) as it is passed to persistent storage and becomes part of the permanent system record. The process is referred to as the 3-phase ontology merge. The three basic merging steps are completely controlled through the system’s current Carmot ontology, and are always the same (labelled 1 to 3 – yellow circles) in the diagram. Two distinct heteromorphic language suites, MitoMine™ and MitoPlex™ are involved in the merging sequence, and both suites use an endomorphic language tied intimately to the Carmot ontology (Carmot-E for MitoMine™ and MitoQuest™ for MitoPlex™).
Although the basic rules for matching and merging records within Mitopia® are universal, the heteromorphic language suites and processes/environments involved mean that there are subtle but important differences in the merging and matching behaviors at each stage. An understanding of these differences is essential to correct script writing. The three merging/matching steps are as follows:
Phase 1 – Temporary Merge of Record References
The first matching/merging process that occurs during a MitoMine™ run happens entirely within the MitoMine™ ‘temporary’ collection (that is the Carmot-E ‘primary’ collection). When the matching <@1:3> meta-symbol for a record created via <@1:4> occurs, MitoMine™ calls the registered ‘record adder’ function. If no custom record adder has been registered (the normal case), MitoMine’s default ‘record adder’ is used. Custom ‘record adder’ functions can be passed to a number of the higher level MitoMine™ API calls and the ‘record adder’ can also be set using the API function MN_SetRecordAdder(). Because the logic within MitoMine™ is such that there is only one <@1:4> record in the ‘temporary’ collection at any given time (since after the merge with the ‘output’ collection, the temporary collection is emptied ready for the next <@1:4>/<@1:3> pair), the only merge/match behavior required occurs during the call to the type script $GenerateLinks() for the record in the ‘temporary’ collection. This script creates any additional records implied by persistent or collection references within the starting record in the ‘temporary’ collection. When the $GenerateLinks() script is invoked, the ‘options’ parameter passes is dependent on certain options set for the ectomorphic MitoMine™ parser as follows:
- If the ‘kNoUserAlerts’ parser option is set the type script option ‘kNoUserInteraction’ is OR’d into ‘options’.
- If the ‘kMatchElementsByNameOnly’ parser option is set, the type script option ‘kMatchByNameOnly’ is OR’d into ‘options’.
- Otherwise ‘options’ is zero.
We will discuss $GenerateLinks() in detail in later posts. For any non-empty persistent reference field (‘#’) in the <@1:4> record, $GenerateLinks() will invoke the $InstantiatePersistentRef() script, for any collection reference (‘##’) it will invoke the $InstantiateCollectionRef() script and for any relative collection reference ‘@@’ it invokes the $InstantiateCollectionRel() script. Any one of these type scripts can be customized on a per type basis through the ontology, however, because of the complexity of the logic implemented within Mitopia’s default registrations, the likelihood of this in your installation is very low. The descriptions that follow assume that Mitopia’s default implementations of these scripts are used.
The merging process that occurs within the temporary collection happens predominantly within the MitoMine™ API function MN_ProcessStringH() which implements some additional logic (see later description) that needs to be considered in script writing. In addition to that logic, the merging and matching logic within the temporary collection is as follows:
- If the reference field is a relative collection reference ‘@@’:
- If the ‘@@’ collection is initially empty, then the new record with the ‘@@’ is created as its fields filled out as specified.
- Otherwise if the ‘@@’ field/type involved does not have have a $UniqueBy annotation associated with it (or ancestral to it) in the current ontology, the ‘name’ field if it exists for the type is used, otherwise every new assignment is assumed to be unique within the ‘@@’ collection. If a ‘unique’ field(s) exists (may just be ‘name’) for the ‘@@’ type the API function TC_CompareUniqueField() (see other Mitopia® documentation) is used to check if the new record is unique or if it matches an existing record already within the ‘@@’ sub-collection. If no match is found, a new record is added to the ‘@@’ sub-collection and assigned, otherwise the assignments are merged with the existing record. Note that these assignments may set up ‘#’ or ‘##’ fields within the ‘@@’ record and this will recursively trigger the entire logic described herein.
- Otherwise (‘#’ or ‘##’ reference) the logic searches for an existing record in the outer collection with the same ‘name’ as the reference. This pre-search by ‘name’ alone is an optimization to improve mining performance but is justified since the references that might overlap are all originating from a single <@1:4>/<@1:3> record created in the temporary collection. It is thus considered unlikely (and will cause redundant records) for a script reference the same thing by two different names within a single created record. This means a pre-search by name is legitimate in this context.
- If no match is found, then a new record of the appropriate type is added and assigned to the outer collection and referenced from the original field. Also if the ‘kMatchByNameOnly’ option is in effect (i.e., the parser option ‘kMatchElementsByNameOnly’ was present) then the same happens.
- Otherwise the logic uses the API routine TC_FindMatchingElements() (see below and in other Mitopia® documentation) to match a test copy of the potential new/altered record (including all assignments) to all those that pre-exist in the temporary collection. In this call the matching option ‘kNoUniqueIDcheck’ is used since all records in the temporary collection generally use temporary IDs. In addition if the ‘kMatchByNameOnly’ option was passed in, it is used. Finally if the ‘name’ starts with “Unknown” or the ‘notes.sourceIDref’ field is non-empty, the ‘kNoPreFilterByName’ option is used. The ‘notes.sourceIDref’ field has a special significance that (overrides the record name and other considerations) when matching records as discussed later. If the test record matches an existing record in the ‘temporary’ collection, a field merge occurs, otherwise a new record is created, assigned, and referenced. The ‘source’ reference from the <@1:4>/<@1:3> record is cloned into any newly added record.
- Finally any additional assignments specified in the ‘stringH’ value are made to the record created/matched. This may assign to reference fields within the created/matched record which will result in the recursive invocation of all the logic described herein for that record and the records it references. This process recurses until no more reference assignments are made. At each point where a record is referenced, the existence on an ‘echo’ specification on the field involved will result in any echo fields being set up as dictated by the specification. If a ‘field assign’ function is specified (see MN_ProcessStringH parameter ‘fieldAssignFn’), this is called immediately before the echo field processing and can alter the behavior in subtle ways (see documentation elsewhere).
Once again, all the activity described above occurs entirely within the MitoMine™ temporary collection. The true complexity actually occurs within the API call TC_FindMatchingElement() which will be discussed in more detail in the next section.
Phase 2 – Local Merge of Temporary to Output Collection
The second merging/matching process of the 3-phase ontology merge also occurs within MitoMine’s default ‘record adder’ after the invocation of the $GenerateLinks() script (which causes the first phase to occur within the ‘temporary’ collection). In the second phase, the entire content of the ‘temporary’ collection resulting from the phase-1 process is now merged and matched with all the mined records already in the MitoMine™ ‘output’ collection. As before, the most important function in this merge is the type collections API function TC_FindMatchingElements(). The ‘options’ passed to this API call include ‘kRecursiveOperation’ and ‘kNoUniqueIDcheck’ and also if the ‘name’ of the original <@1:4>/<@1:3> record in the temporary collection starts with “Unknown” or the ‘notes.sourceIDref’ field is non-empty, ‘kNoPreFilterByName’. In addition if the ectomorphic parser option ‘kMatchElementsByNameOnly’ is set, the type script option ‘kMatchByNameOnly’ is OR’d into ‘options’. The logic performed in this match/merge step is as follows:
- For each record of all types in the ‘temporary’ collection not already processed loop:
- if the record’s unique ID field is not set, assign a new temporary ID
- match = if the ectomorphic parser option ‘kItemsAreUnique’ is not set OR the record type is descendent from ‘Source’ OR it is not the original <@1:4>/<@1:3> record of the temporary collection then
- Match the ‘temporary’ record with the ‘output’ collection contents using match = TC_FindMatchingElements().
- if no match has been found above then match = Add a new empty record to ‘output’ collection
- Call TC_MergeFields() API function to merge all fields of the ‘temporary’ record (and any ‘@@’ sub-collections it may contain) into the ‘match’ record in the ‘output’ collection.
Note in the logic above that the ‘kItemsAreUnique’ parser option only applies to the ‘temporary’ record that was explicitly created using the <@1:4>/<@1:3> meta-symbols, not to any other records in the ‘temporary’ collection that were created by reference. This is a critical point since if this were not so then the ‘kItemsAreUnique’ logic would cause unintentional replication of referenced items which would render the mined output useless.
Before we discuss in detail how the logic of the TC_FindMatchingElements() call, and that of the call to TC_MergeFields() (see other Mitopia® documentation for complete details) impact the MitoMine™ script writer, the API and description for both these functions (and US_CombineStrings which is used by TC_MergeFields) is presented below. It is necessary for the script writer to be aware of how these lower level Mitopia® APIs operate in order to fully understand the matching and merging process that goes on within the second phase of the 3-phase ontology merge.
TC_MergeFields() – Intelligently merge fields from two matched records
 This function (semi) intelligently merges the fields of two records in the same or different collections that relate to the same item, preserving in the ‘tgtElem‘ all fields found in both records. Where there is a conflict between the fields, if the field concerned is textual and different between the two records then:
This function (semi) intelligently merges the fields of two records in the same or different collections that relate to the same item, preserving in the ‘tgtElem‘ all fields found in both records. Where there is a conflict between the fields, if the field concerned is textual and different between the two records then:
- If the source field is non-empty and the target field is not, the source field is copied to the target field. If the field is a relative reference, it is zeroed in the source.
- If the target field is non-empty and the source field is not, the target field is preserved.
- Otherwise merge the strings according to the logic used by US_CombineStrings().
If the two fields conflict and are not textual then:
- If the source field is non-empty and the target field is not, the source field is copied to the target field. If the field is a relative or persistent reference it is then zeroed in the source.
- If the target field is non-empty and the source field is not, the target field is preserved.
- Otherwise the target field remains un-altered.
In the case of copied fields containing relative or persistent references, appropriate changes are made to adjust the reference (if non-zero) to reference the original referenced item from the target. Once done, if the source and target collections are the same, the reference is zeroed in the source. In the case of two non-empty collection references, all children of the source collection are looked up by name and type within the target collection and if not found, and the source and target collections are the same, they are removed from the source collection and inserted into the target collection appropriately. Once done, the source field collection is zeroed (if the collections are the same). If the source collection is non-empty and the target collection is empty, the collection is simply moved in its entirety to the target. When merging referenced collections into the target, the collection elements are converted to the type ET_Hit if not already of that type in the source
The ‘kNoUniqueIDcheck‘ option will cause unique IDs to be ignored during record comparison. This may well be appropriate when merging records containing temporary unique IDs. The ‘kMatchByNameOnly‘ option may be specified and will be passed through to embedded calls to TC_FindMatchingElements().
See the later section entitled “Comma separated Fields” for the unique behavior of this function for text fields that have the $CommaDelimFields type annotation associated with them.
TC_FindMatchingElements() – Find elements that match a given element in a collection
 This function makes use of TC_Find() to locate a record(s) within the designated portion of a collection having data for which the various fields of the record can be used in a custom manner to determine if the two records refer to the same thing. This routine operates by invoking the script $ElementMatch() when it finds potentially matching records, this script can be registered with the ontology and the algorithms involved may thus vary from one type to the next. This capability is essential when trying to determine if two records relate to the same item, for example when comparing people one might take account of where they live, their age or any other field that can be used to discriminate including photographs if available. The algorithm for other types would obviously be different. The correct and useful operation of the system is predicated on the application code registering effecting comparison scripts that can be invoked via this function. The ‘kNoUniqueIDcheck‘ options will cause unique IDs to be ignored when comparing elements. This may be appropriate when records contain temporary unique IDs. Mitopia® internally registers a default match script with ‘DTUM‘ that simply compares type compatibility and name fields and this will be invoked if no other more refined $ElementMatch() script is found.
This function makes use of TC_Find() to locate a record(s) within the designated portion of a collection having data for which the various fields of the record can be used in a custom manner to determine if the two records refer to the same thing. This routine operates by invoking the script $ElementMatch() when it finds potentially matching records, this script can be registered with the ontology and the algorithms involved may thus vary from one type to the next. This capability is essential when trying to determine if two records relate to the same item, for example when comparing people one might take account of where they live, their age or any other field that can be used to discriminate including photographs if available. The algorithm for other types would obviously be different. The correct and useful operation of the system is predicated on the application code registering effecting comparison scripts that can be invoked via this function. The ‘kNoUniqueIDcheck‘ options will cause unique IDs to be ignored when comparing elements. This may be appropriate when records contain temporary unique IDs. Mitopia® internally registers a default match script with ‘DTUM‘ that simply compares type compatibility and name fields and this will be invoked if no other more refined $ElementMatch() script is found.
The default function is subject to short circuit index lookup if a “name:type” index is defined (which it always is for the ‘output’ collection within a MitoMine™ run, unless the ‘output’ collection is created externally and passed in through API calls), in many cases this can substantially improve performance within servers and when mining large collections of similar items. Note that it is assumed that when an item is added to the “name:type” index it is added both for “name:” and also “name:type” so that lookup may be first by name and then separately by type. This logic holds for all internally generated “name:type” indices such as that used within MitoMine™. Note that if there is more than one possible match in the collection, and “name:type” exists, and ‘maxHits‘ is set to 1, there is a possibility that a less ‘relevant’ item may be matched when a more ‘relevant’ one actually exists in the collection.
The ‘kMatchByNameOnly‘ option can be used to suppress the use of type-specific element compare function in cases where you can be sure that no two distinct items of the same type in the collection have identical names which might be distinguished by the comparators. This option can considerably speed up the search in this case (particularly relevant for large MitoMine™ operations) but you must be certain that this assumption is true. The ‘kNoUniqueIDcheck‘ is also required for this option to take effect. Even if the ‘kMatchByNameOnly‘ option is not set, this function will pre-filter by name using the “name:type” index if present, however, it will then call the appropriate element match function to ensure that an actual match has occurred. This behavior by itself causes execution time to be close to that for ‘kMatchByNameOnly‘ during MitoMine™ since it always has a “name:type” index and it is rarely if ever the case that one would not want this behavior. If you wish to inhibit this behavior, you must set the ‘kNoPrefilterByName‘ option.
US_CombineStrings() – Intelligently combine two strings

This function performs an intelligent merge between two strings so as to append those portions of the text that appear in the source string to the end of the target string. The merge assumes that the text represents standard phrases, sentences, and paragraphs and is performed in a top down manner so as to preserve levels of text grouping from the two sources. The basic algorithm is as follows:
(a) if the strings are identical do nothing.
(b) if the strings start with <html> tags, append source (starting at “<head“) to target starting at “</html>“.
(c) if source contains multiple paragraphs (delimited by “.” EOL_STR “\t”), then all source paragraphs not in the target are appended to the target.
(d) if not (c) and the source contains multiple sentences (delimited by “.”), then all source sentences not in the target are appended to it.
(e) if not (c) or (d) and the source contains comma delimited phrases (delimited by “,”), then all source phrases not in the target are appended to it.
(f) otherwise if the source string is longer than (or equal to) the target string, copy the source into the target, overwriting the target.
So, other than being familiar with the details of the logic within TC_MergeFields() and US_CombineStrings() as described above, the important thing a script writer must understand is the record matching behavior of TC_FindMatchingElement() as described above. Basically this in turn boils down to understanding the behavior of the $ElementMatch() script that relates to the ontological type of record being matched. This type script and the fact that it can be (and usually is) customized on an per type, per project basis within the current system, is perhaps the most critical thing for the script developer to understand regarding the 3-phase ontology merge. The whole subject of Mitopia’s $ElementMatch() script logic and how you can customize matching for any type in the Carmot ontology will be covered in a later post.
Phase 3 – Global Merge of Output Collection(s) to Persistent Storage
The final and most complex match/merge occurs within persistent storage after the final output collection(s) from the mining run are persisted to the MitoPlex™ servers. Here as for the phase-2 merge, the dominant consideration is the exact nature of the registered $ElementMatch() scripts which also control much of the server matching process. A full description of the complex process that the MitoPlex™ servers go though when matching the elements of a persisting collection to the existing content of all the servers and server clusters that make up persistent storage is well beyond the scope of this post. See other Mitopia® documentation for full details. However, for the purposes of the MitoMine™ script writer understanding the merging/matching process, we can grossly simplify our model of Mitopia® persistent storage to assume that there is just one server for all ontological types in the system (that is all types derived from Datum – key type ‘DTUM’) and that the ‘DTUM’ server has no drones and is a single process.
In reality of course servers could be widely distributed geographically, are type specific, and are often heavily clustered thus requiring matching and merging across data on many machines. Also for any given type in the ontology there may be hundreds or thousands of disk-based collections in any given server cluster node against which comparisons must be made. All this while coordinating across servers, and between all the drones of a given server cluster, to ensure that even during heavy parallel ingestions of overlapping records, no incorrect duplicate records are created in persistent storage. Of course we must perform all this as efficiently and fast as possible, while ensuring that no process gets hung up indefinitely waiting for an answer from another process/server/drone. In our discussions below we will ignore all this complexity – see other Mitopia® documentation for details.
When the server receives the ‘output’ collection(s) from MitoMine™ to be persisted, whatever ‘options’ you may have set in the mining script (e.g., ‘kMatchByNameOnly’ or ‘kItemsAreUnique’) are now irrelevant to the matching/merging process. To allow the client code to override or alter the globally registered matching and merging logic in the servers would be a recipe for disaster. There is one exception to this rule which is that if a server is set up to mine a particular live source (e.g., a news story feed), and if the ‘kItemsAreUnique’ option is set in the mining script associated with that source/server, then the effect is to suppress the matching process in the server as well as during the mining step. The purpose of this exception is to allow live feeds that are guaranteed unique even if subsequent items may have the same name as earlier ones (a news story feed is the classic example), to be treated correctly and create unique records for each new input.
If a record in the persisting collection has the ‘kHiddenFLG’ flag set, that is it is invisible in the GUI (see TC_SetFlags) it is ignored in the merging process. Otherwise the server calls the $ElementMatch() script on the server data collection(s) for the record type passing the “kNoUniqueIDcheck+kIsServerDataCollection+kStandardHierarchy” options. The ‘kNoUniqueIDcheck’ option is critical since the incoming records resulting from the mining process should normally have temporary IDs so that the match with persistent data is made based on other field values.
Note that when the logic calls TC_GetTypeScript() to obtain the appropriate $ElementMatch() function, it passes a reference to the persisting collection node to the call which means that it is theoretically possible to associate an $ElementMatch() script with the element concerned in the client after the mining run completes, and have that script used in preference to the globally registered script. This is an extremely obscure feature and there is very little chance you will need to use it.
If a match is found for a given record anywhere within persistent data, the incoming mined record is merged with the record in the server data collection using TC_MergeFields() just as in phase 2 except that the options passed are “kNoRefInstantiate+kNoUniqueIDcheck+kNoScriptInvoke”. The ‘kNoRefInstantiate’ option is present because each server data collection contains records of just a single ontological type, all references to other record of different types are made purely by unique ID (that is the ‘elementRef’ field of any reference is always zero in a server data collection). The need for the ‘kNoUniqueIDcheck’ option has already been explained above. The ‘kNoScriptInvoke’ option means that no registered type or field scripts will be invoked within the server’s field merge. This is essential not only for performance reasons, but also to ensure that badly written registered scripts cannot derail the merging process since at this point the records involved are no longer up for discussion. MitoQuest™ uses a custom field combiner function in this call in order to enforce the following additional logic onto the merge with the server data collection:
- The ‘dateUpdated’ field in the target is set automatically to the current data by code.
- The ‘hostID’, ‘id’, ‘datumType’, ‘dateEntered’, ‘source’, and ‘language’ fields in the data collection cannot be updated once set.
- The ‘name’ field of the target can only be updated if the record being merged uses a matching permanent unique ID. A merge using a temporary ID cannot change the name. This is to avoid damage to existing records from incorrectly filled out ‘matches’.
- When merging persistent reference fields where both the mined record and the data collection record have existing values, the target value is only updated if both the unique ID and the name fields of the persistent reference have changed.
Other than the logic described above, and the special cases discussed in the following sections, the merging/matching process relies entirely on the registered $ElementMatch() scripts for the record types involved. See the “$ElementMatch() Scripts” discussion elsewhere.
Comma separated fields
You will note that within the base ontology (see I.DEF) there are a number of $CommaDelimFields type annotations. For example the ‘Datum’ type contains the following $CommaDelimFields annotations which are of course inherited by all descendent types:

This annotation is used by TC_MergeFields() during every step of the 3-phase ontology merge (and indeed everywhere field values are merged) to alter the default behavior of the function for any text fields that have the annotation associated with them. The normal behavior of TC_MergeFields() was described earlier under “Phase 2…”. Within TC_MergeFields() the code combines the $CommaDelimFields annotation for the record type involved AND all ancestral types in order to obtain a complete lists of such fields for the current type. Then whenever the code is merging two relative reference (i.e., “char @fieldName”) fields (this annotation does not effect other field types derived from ‘char’), the following logic applies instead of the standard method:
- Any comma separated text sequences appearing within the source field value that are not already within the target field value are appended (comma separated) to the target (merged) field value.
- Any comma separated text sequences appearing within the source field value that are already within the target field value are ignored.
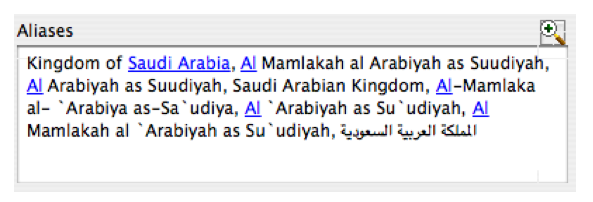
This logic makes ‘char @’ fields with an associated $CommaDelimFields annotation ideal for accumulating comma separated lists without the need for the script writer to consider all the complexity of ensuring that the same comma delimited value does not appear in the list more than once. As we shall see below, this logic is critical to the operation of the ‘notes.sourceIDref’ field, but it is perhaps most easily understood for the ‘aliases’ field which is intended to build up all the possible alternate names for a given thing regardless of source. For example, the screen shot below shows the alias field content for the country of Saudi Arabia as a result of merging data from approximately 40 different and largely unrelated sources in both English and Arabic. Each of these sources may refer to the country by a different name, and yet all data from the various sources has been correctly accumulated within the single country aliases field as a result of the automatic logic triggered by the $CommaDelimFields annotation.
 When adding to a comma delimited field such as ‘aliases’ one usually includes code similar to the following in the script: <@1:5:aliases = $a + “,”>.
When adding to a comma delimited field such as ‘aliases’ one usually includes code similar to the following in the script: <@1:5:aliases = $a + “,”>.
Matching via ‘notes.sourceIDref’
Quite often a data source will include a field giving something like the ‘unique ID’ of the record involved in the source system (often derived from a relational database). In many cases these ID reference fields correspond to a primary key in the RDBMS, in other cases they contain some otherwise guaranteed unique value (e.g., social security number). The meaning of this unique source ID is essentially that any two data that are tagged with the same source ID are by definition referring to the same thing, while any two data that have different source IDs are by definition referring to different things.
In cases where this kind of unique source ID is available, scripts can use it in order to ensure that any references to items with the same source ID are merged. The script can also use the unique source ID to prevent items that would otherwise be considered a match (e.g., two persons with the same name) from being merged. It is important however that if only one of the items being compared in a matching process contains a reference for a given source, then it has no effect on the matching logic. This ensures that items from one source/database with an internal ID designator can be correctly merged with items from another source/database that has a different (or no) internal ID designator. Finally, there may be two completely isolated sources both of which reference an externally unique ID (e.g. SSN) which can be used to merge records even if they might not otherwise be merged (maybe the name is different/misspelled in one source).
All this logic is facilitated within Mitopia® by use of ‘notes.sourceIDref’ which is a comma separated field (see previous section). The following list details all the places where the ‘notes.sourceIDref’ field impacts Mitopia® logic concerning merging and matching and the effect caused:
- Within TC_MergeFields() if a record has a non-empty value in ‘notes.sourceIDref’, the effect is to automatically set the ‘kNoPrefilterByName’ option so that nested calls to TC_FindMatchingElements() do not attempt to pre-filter the match records by name. This is because the name could be “Unknown…” or could be inconsistent between different sources so even records with different names may potentially be matched up via the ‘notes.sourceIDref’ logic. This same logic is found within MitoMine’s default record adder function MN_DefaultRecAdd() which means that the ‘notes.sourceIDref’ content also impacts record matching within the ‘temporary’ collection during phase 1 of the 3-phase merge. The MitoMine™ API function MN_ProcessStringH() also contains this logic.
- Within a MitoPlex™ server when matching/merging a collection with the server’s existing data, the process occurs in two distinct phases if any of the records in the collection being persisted contain non-empty ‘notes.sourceIDref’ fields. In the first phase, all such non-empty records are matched across the entire server/cluster data content using just the ‘notes.sourceIDref’ server side logic described below. Any records not matched during this phase are then matched normally using other record fields. After both phases, records matched in either way are merged, those that remain un-matched create new records in persistent storage.
- Every type specific $ElementMatch() script must make use of the API function TS_ItemsExternalMatch(). This routine is called when the ‘name’ field of the two records being compared differs, but one of the names starts with “Unknown” (see following section). The purpose of the call is to see if ‘notes.sourceIDref’ logic can be used to confirm/deny a match. The logic of this function is as follows:

So the bottom line is this function will cause any two records having a common comma-delimited entry in their ‘notes.sourceIDref’ list to match.
- Every type specific $ElementMatch() script also uses the API function TS_ItemsExternalMisMatch(). This routine is called at the end of the $ElementMatch() function in order to see if despite the fact that the records appear to match, they should be considered different because of ‘notes.sourceIDref’ logic. The logic for this function is as follows:

The critical logic here is the fact that this routine will return a mismatch if any two comma delimited sequences match exactly up until the first underscore character ‘_’. This means that we can choose to construct our ‘notes.sourceIDref’ entries to be of the form “sourcePart_idPart” where ‘sourcePart’ uniquely identifies the data source or the unique thing being matched (e.g., “Janes orgID” – unique Organization identifiers that are common to all Janes databases) and the ‘idPart’ contains just the unique identifier sequence itself (e.g., “100”). Because of the difference in the logic between TS_ItemsExternalMatch() (which ignores ‘_’ characters) and the logic in TS_ItemsExternalMisMatch() (which does not), if two sequence match for their entire length (that is both ‘sourcePart’ and ‘idPart’ match) then we can declare a match, but if they match only up until the ‘_’ character but not for their entire length, then we can be sure that the items are different. If they mismatch completely then the items do not have a common unique source reference between them, so we cannot decide a match or a mismatch and the matching process falls back on the standard $ElementMatch() logic described earlier. You will find many examples of using this feature dotted around the example MitoMine™ scripts. For example, you will find productions similar to those shown below in many of the Janes sample scripts. This is because Janes assigns a unique (internal to Janes) ‘Organization reference’ to every manufacturer or supplier that is referenced across all of its databases (though not all use/reference this unique ID). This Janes ID probably derives from some kind of relational database within Janes that tracks such things. The reason that we use this information in the ‘notes.sourceIDref’ assignments shown, is that despite referencing the same unique organization ID, different Janes databases may actually use widely divergent names to refer to that organization. If we didn’t improve the matchup using the available organization ID in this way, the result would be that data from different Janes databases that actually refer to the same organization would not be correctly merged when the names used differ. It is important here to remember that within a MitoPlex™ server when merging with existing storage, the matching logic for any records contain ‘notes.sourceIDref’ values is tried REGARDLESS OF NAME using the ‘notes.sourceIDref’ values only (see above). Only then is the standard logic applied. This means that even if neither ‘name’ being matched begins with “Unknown”, during the phase 3 merge when the data from one mined Janes source/collection is compared with existing data from previous Janes sources, it will be matched using the Janes unique organization ID and thus correctly merged into a single record. Within the phase 1 and 2 merge/match steps which are associated with a single source, the ‘notes.sourceIDref’ field will only merge items if their names match, one of the names begins with “Unknown”. This too makes sense since a single source presumably uses the organization name consistently.

Note that records can be merged regardless of the content of the ‘name’ field on the client-side if the routine TS_RecursiveMatchElement() is invoked (see below), which in turn implies that the ‘theParentRef’ parameter to TC_FindMatchingElements() is set to zero (i.e., search the entire outer collection). This is not the case for MitoMine’s default record adder function MN_DefaultRecAdd(), nor is it the case for MN_ProcessStringH(). This is why names other than those involving “Unknown” are only merged at the third phase in a MitoMine™ context.
- All $ElementMatch() scripts also call the API function TS_RecursiveElementMatch() when the parameter ‘tgtOffset’ is zero. This API function implements additional complex logic associated with the ‘notes.sourceIDref’ field as follows:
- if the ‘tgtOffset’ parameter is specified as zero AND a non-empty “notes.sourceIDref” value exists within ‘srcOffset’ AND the ‘srcOffset’ record uses a temporary unique ID:
- Before attempting the normal recursive matching process, try for a match using just the ‘notes.sourceIDref’ fields. The only difference a leading “Unknown” in the ‘name’ makes in this case is that if present the ‘relevance’ on a match is 100% whereas if the ‘name’ fields differ otherwise it is 25%. See the note immediately above regarding passing zero for ‘theParentRef’ to TC_FindMatchingElements().
- if the ‘tgtOffset’ parameter is specified as zero AND a non-empty “notes.sourceIDref” value exists within ‘srcOffset’ AND the ‘srcOffset’ record uses a temporary unique ID:
Names beginning with “Unknown”
If you have not already read the preceding section entitled “Matching via ‘notes.sourceIDref’” you should do so now because the logic associated with the ‘notes.sourceIDref’ field and the occurrence of a ‘name’ field beginning with “Unknown” interact strongly.
As discussed in the preceding section, every registered $ElementMatch() script contains logic similar to that shown below regarding names that start with “Unknown”:
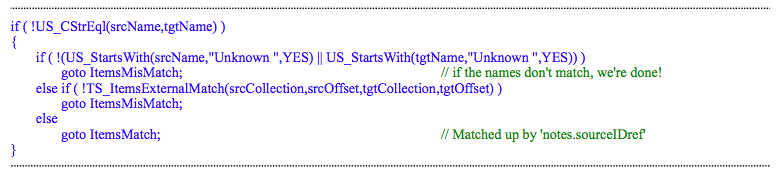
This effectively means that whenever two records of the same type are compared to see if they are referring to the same ‘thing’, if the record ‘name’ fields are different, they may still be considered to be the same thing if one of them begins with “Unknown” and the logic associated with a non-empty ‘notes.sourceIDref’ field (see previous section) indicates that they are referring to the same ‘thing’. Mining scripts commonly assign names starting with unknown to referenced items whose name is not known in the current context but perhaps some other identifying field is known (e.g., an airport’s call letters) which for the type concerned will make the match because it is known that the $ElementMatch() script for the type involved considers the identifying field within its logic. An obvious example is an email address for the type Person.
This special treatment of names beginning with “Unknown” also extends to the fact that when searching for a match using TC_FindMatchingElements() (which occurs during all match/merge phases), if the name of the record for which a match is being sought begins with “Unknown” then the ‘kNoPrefilterByName’ option is used which means that registered $ElementMatch() scripts may be set up to make a match at any stage in the process depending on the other field content. Also when merging field content (e.g., TC_MergeFields) in any merge for two ‘name’ fields, if one field begins with “Unknown” then the other record’s ‘name’ field wins. This means that it is safe to merge records starting with “Unknown” with others where the name is known in either order, that is the “Unknown” can be created/persisted first or second and the system will correctly finish up with the ‘name’ that does not begin with “Unknown” when all is said and done.
Within the system MitoPlex™ servers, when searching across all possible matches, records that are determined to be a possible match are assigned a lower ‘relevance’ is the begin with “Unknown” than if they begin with anything else. Once again this is part of ensuring the even in the (unlikely) event that a separate “Unknown” record and another record having ‘name’ filled out are created in different places within persistent storage, the “Unknown” record will loose out in later matching processes, so that the correctly named record will be the subject of any further merging activity. Merging and matching logic in the servers contains a lot of logic relating to records whose ‘name’ starts with “Unknown”, in particular when resolving temporary IDs between servers or server clusters, whenever an “Unknown” name is resolved, all potentially interested MitoPlex™ servers are notified so that any references (e.g., persistent reference ‘name’ fields) to the previously “Unknown” name are correctly updated to the new name.
Names beginning with “no ” or “none”
Within the API function MN_ProcessStringH() which is part of MitoMine™ default record adder function whenever an attempt is made to assign the ‘name’ of a referenced value to something starting with “no ” or “none”, the assignment (and any other fields that may have been assigned in that reference) is discarded and no reference is created. This basically only impacts the phase 1 expansion within the MitoMine™ ‘temporary’ collection but means that it is not possible to create items by reference in a script if the item name begins with either of these prefixes. The reasoning behind this is that often sources contain text fields that are intended to reference the name of something and when the referenced thing is not present, instead of leaving the field empty, these sources put in a string beginning with “none” or “no ” (e.g., “no known associates”). As a convenience to simplify scripts dealing with these kinds of sources, and to prevent the creation of erroneous persistent records starting with these prefixes, MitoMine™ includes internal logic to suppress references starting with these prefixes.
This post covers just the basics of merging and matching records during Mitopia’s 3-phase ontology merge process. We will go into further detail in future posts.