This post is number 3 in a sequence of 7. Click here to get to the beginning.
The ‘##’ symbol – persistent collection ref.
The ‘##’ symbol, as one might expect given the meaning of the ‘#’ symbol, is used to denote a one-to-many relationship from a field within an ontological type, to a set of other records of the same or different types that are ultimately stored within Mitopia® servers and can be referenced by a globally unique ID. The actual implementation of the collection reference field is hidden by the abstraction layer from Carmot code, but is essentially as follows:

As can be seen, the ET_CollectionRef structure is identical to the first portion of the ET_PersistentRef structure used to describe ‘#’ references (see here). As with the persistent reference, the ‘stringH’ field is associated with MitoMine™, and its use is beyond the scope of this discussion. To implement collection references, Mitopia® simply uses the ‘elementRef’ field of the reference as a relative offset to the root node of an embedded sub-collection (see flat memory model discussion – here) where all the valued nodes in the sub-collection are of type ET_Hit (see previous post) and can be used to reference the target persistent items in the one-to-many relationship. For an example, we will use the type “GroupRelation” in the standard ontology which is declared as follows:

As we can see the field ‘Datum ##related’ is declared to be a collection of references to items of any persistent type derived from Datum. This is as one would expect for a generalized relating structure like ‘GroupRelation’. The ‘GroupRelation’ type can be used to create a one-to many relationship between a ‘one’ (in this case referenced via the ‘Datum #regarding’ persistent reference field) of any persistent type (i.e., derived from Datum), and the ‘many’ (referenced via the ‘Datum ##related’ field) which can similarly be of any number of persistent types not all necessarily the same. Like in the persistent reference case, the ‘aTypeID’ field of the ET_CollectionRef can be used to limit the types of the references in the associated sub-collection to descendant types of the declared type used in the referencing field declaration though this is seldom necessary since the sub-collection is hierarchical and thus can accommodate any set of descendent types within the hierarchy.
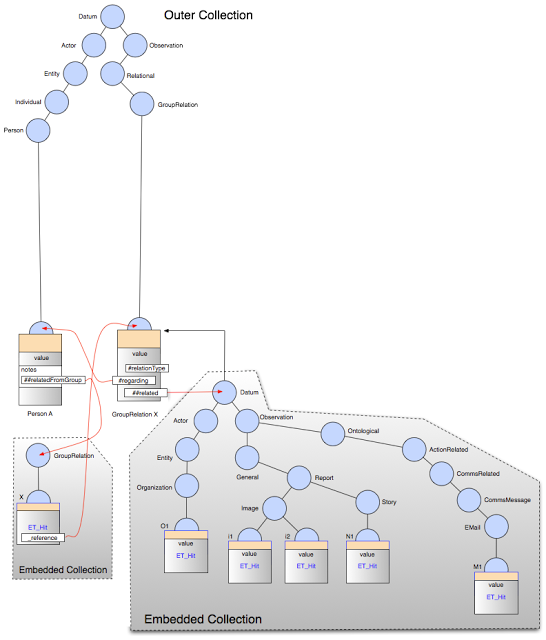 |
| An un-resolved ‘##‘ collection reference as held within a flat memory model collection |
Let us assume for the sake of illustration that we were to create a group relation ‘X’ (of relation type “Evidence” say) associating a person ‘A’ with two images (‘i1’ and ‘i2’), one news story (‘N1’), an organization (‘O1’), and an e-mail (‘M1’). This would appear as shown in the diagram above within the collection handle immediately after we were to fetch the record for person A from persistent storage and then resolve the “##relatedFromGroup” within the ‘notes’ section of the record for person A. This would result in fetching and referencing “GroupRelation X”. When any data record is fetched from storage, MitoQuest™ automatically fetches and returns the contents of all embedded collections within any collection reference ‘##’ fields of the record. Hence when the original person record was fetched, the small embedded collection associated with the ‘##relatedFromGroup’ field of ‘notes’ was already present.
Let us re-state this to be abundantly clear. Mitopia® servers store their data in collections described by the Carmot ontology for the system, exactly as they are held and manipulated in memory in the client; this means that all this complex sub-collection structure is already held within the server file describing the record involved, it can be searched, and is of course fetched in the client (completely unmodified) whenever the ‘containing’ record is fetched. This is a huge difference from a conventional information level (i.e., relational) database. Note that because the declaration for this collection reference field is:
GroupRelation ##relatedFromGroup >< regarding;
the root node of this sub-collection is GroupRelation, not Datum. This elimination of disallowed nodes in the hierarchy of sub-collections allows them to be stored and searched with maximum efficiency, and is possible because we know that any items within the sub-collection are constrained to be descendant from the referencing field type, and so we do not need to allow for any hierarchy outside of this type.
When this sub-collection is resolved (as the ‘relatedFromGroup’ field is resolved), the result is to fetch the corresponding data value into the outer collection (creating additional non-leaf nodes in the outer collection hierarchy as necessary) and then reference the fetched data record via its node/element designator using the ‘_reference’ field of the ET_Hit in the sub-collection responsible for the reference.
Once again when fetching the group relation record from persistent storage, all embedded collections within it are also fetched and so the much larger sub-collection displayed to the right in the figure above is fetched along with X. The parent of this sub-collection is the ET_Simplex record for X (see the flat memory model discussion – here), not the collection node (which is the pale blue ET_Complex record associated with the value). The red lines in the diagram show the logical links that are set up as part of the resolution process.
Note that the ‘echo’ field ‘regarding’ declared by the ‘ relatedFromGroup’ field causes the reverse link to be made directly back from X to Person A. The behavior of echo fields ‘><‘ will be discussed more fully later.
Within the embedded collection associated with the ‘##related’ field of X, we see that the hierarchy is much larger since this field is declared as being a collection of Datum, that is any persistent type. As with the outer collection, only those non-leaf nodes that are actually required are present in the sub-collection, others can be added later if additional related items are added to the sub-collection. This sub-collection therefore shows a larger sample of the default ontology.
As we have discussed before, the valued nodes in these embedded collections that are created by MitoPlex™ when returning data from persistent storage, are always of type ET_Hit, which we have seen previously is sufficient information to recover the actual value if required. Initially the ‘_reference’ field of all these embedded ET_Hit records will be zero; it is set non zero when the referenced value is fetched from persistent storage as a result of resolving the referencing field in the parent data record. In actuality, there is no fundamental requirement that embedded collections contain only ET_Hit values, they can contain whatever data is desired. However, MitoPlex™ and MitoQuest™ adopt this ET_Hit collection approach to sub-collections because it allows for efficient implementation of persistent storage servers, and also because it avoids creating duplicate records in sub-collections for records that might already be in the outermost collection.
You will note that the non-leaf collection nodes in both the outer and embedded collections are named and organized according to the Carmot ontology hierarchy. This convention too is enforced by MitoPlex™ in order to facilitate its operation. In actuality nodes may be organized in collections according to any scheme desired, however, when accessing data from persistent storage, all embedded and outer collections will be organized according to the Carmot ontology.
Note also that the leaf nodes (ET_Complex records) for the ET_Hit values in the sub-collections are named according to the name field of the item being referenced. This use of the leaf node name to hold the referenced record name is once again enforced by the underlying abstraction primarily to allow any user interface that is displaying a sub-collection in a list control to display the names of the items in the sub-collection without being forced to fully resolve the ET_Hit with persistent storage. This is a performance optimization primarily, much like the use of the ‘char @name’ field in the ET_PersistentRef record. As with the persistent reference case, the name is not used to resolve the data item with storage, it is simply a convenience for display. Leaf nodes in the outer collection are usually not named since the value of the node leads via the ‘char @name’ field to the name.
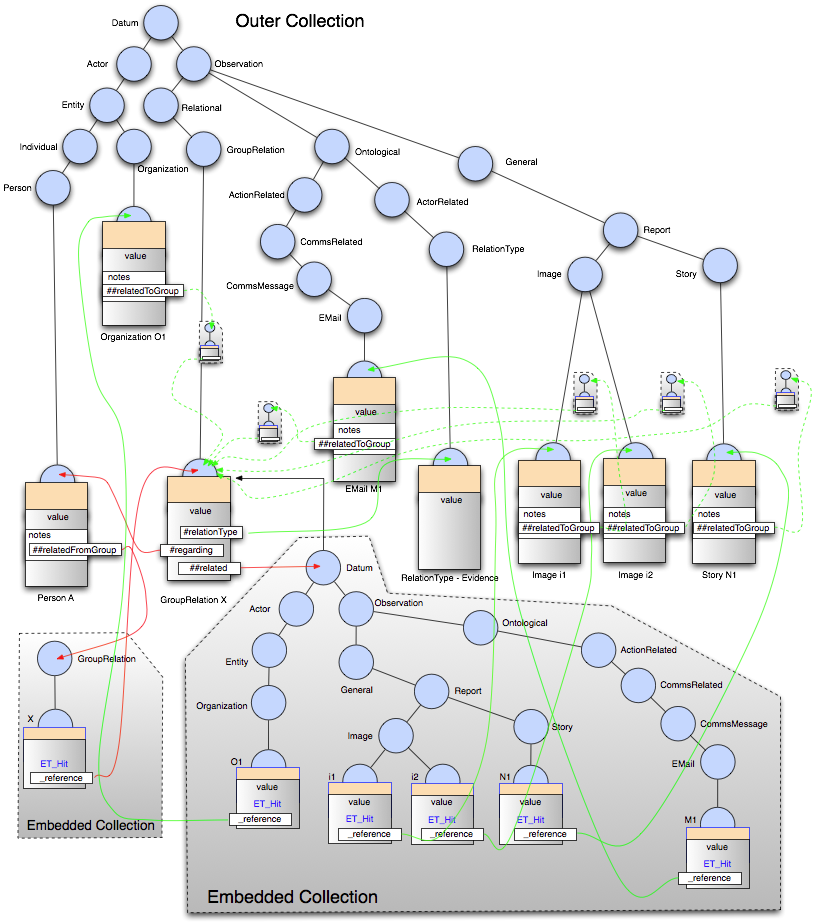
After resolving all the reference fields for GroupRelation X including the ‘Datum ##related’ field, the collection content would appear as follows:
 |
|
|
As can be seen, as a result of resolving the second embedded collection, the Mitopia® abstraction has fetched all the referenced values into the outermost collection, adding non-leaf ontology nodes as necessary to hold the values fetched. When all the data has been fetched, the ‘_reference’ field of the referencing ET_Hit is updated to refer to the fetched data. These references are shown in green in the second diagram. However, the actual situation is even more complex since the data items fetched during the resolve process themselves had embedded collections (shown small in the diagram for space reasons) that were the result of the echo field in the group relation “Datum ##related >< notes.relatedToGroup” field of the GroupRelation, which as can be seen implies that the item being referenced should have the opposite reference in its “notes.relatedToGroup” field which is itself a collection reference. This enforcement of the echo behavior results in all the additional embedded collections and all the links (shown in dashed green in the second figure) being established simultaneously when resolving the embedded collection. To see why this is, consider the declaration of the ‘notes’ sub structure which is part of every Datum derived record:

See the later section on echo fields for further details. Clearly then the activities involved in creating and maintaining even the simplest links between data items described by the Carmot ontology in order to ensure referential integrity, are extremely complex and far beyond the ability of any normal programmer to handle reliably in an ad-hoc manner. In fact, much of the true complexity has been left out of the diagram in order to focus on the subject at hand; a real collection would by this stage contain many other nodes and links.
This complexity is one of the primary motivators behind tightly integrating Mitopia’s Carmot ODL with the underlying abstraction layers using a contiguous-model. Without this extreme level of integration, the complexity of handling the ramifications caused by ontological links almost immediately gets out of hand. This fact may be the reason why other ontologies have chosen to follow the disjoint-model approach, and leave such complexity as an exercise for the poor developer that attempts to use them.
Within Mitopia®, all this complexity is handled automatically and pervasively by the substrate to such an extent that the Carmot programmer is generally unaware if any given bit of data is simply transitory in memory or has been fetched and resolved into memory by the substrate, at the Carmot level both appear identical.
In the next post we will examine an even more complex form of nested sub-collection, that is the relative collection reference signified by the ‘@@‘ symbol in Carmot.