

There are perhaps three fundamental database metrics by which performance of a repository can be measured from a user perspective:
- Time taken to execute a query
- Time taken to create/update records
- Time taken to retrieve documents
If one wishes to scale a system to the petabyte level and above, it is clear that only a fully distributed data model will allow optimal use of CPU and network resources in order to meet the database metric objectives. While it is relatively simple to imagine partitioning data sets in order to speed up query execution and retrieval time, is it also clear that distributing data across multiple network nodes will lead to all kinds of complexity when creating new records or merging changes into existing records.
The fundamental issue is that when one ingests a record from an external source, the first question that must be answered is “is this the same as an existing record?” in order to determine if a merge or a new create is necessary. Equally as important in a distributed context is how does one avoid problems when two distinct nodes simultaneously ingest the same new record, how does one avoid the creation of duplicates?
While there are strategies to mitigate these issues, they normally require that all nodes be consulted up front before the fate of any newly ingested record is determined. This in turn results in the overall ingest rate for the network being drastically limited as each server node is effectively queued up waiting on all others. This is unacceptable if we want to maintain a database metric supporting massive and scaleable ingest rates.
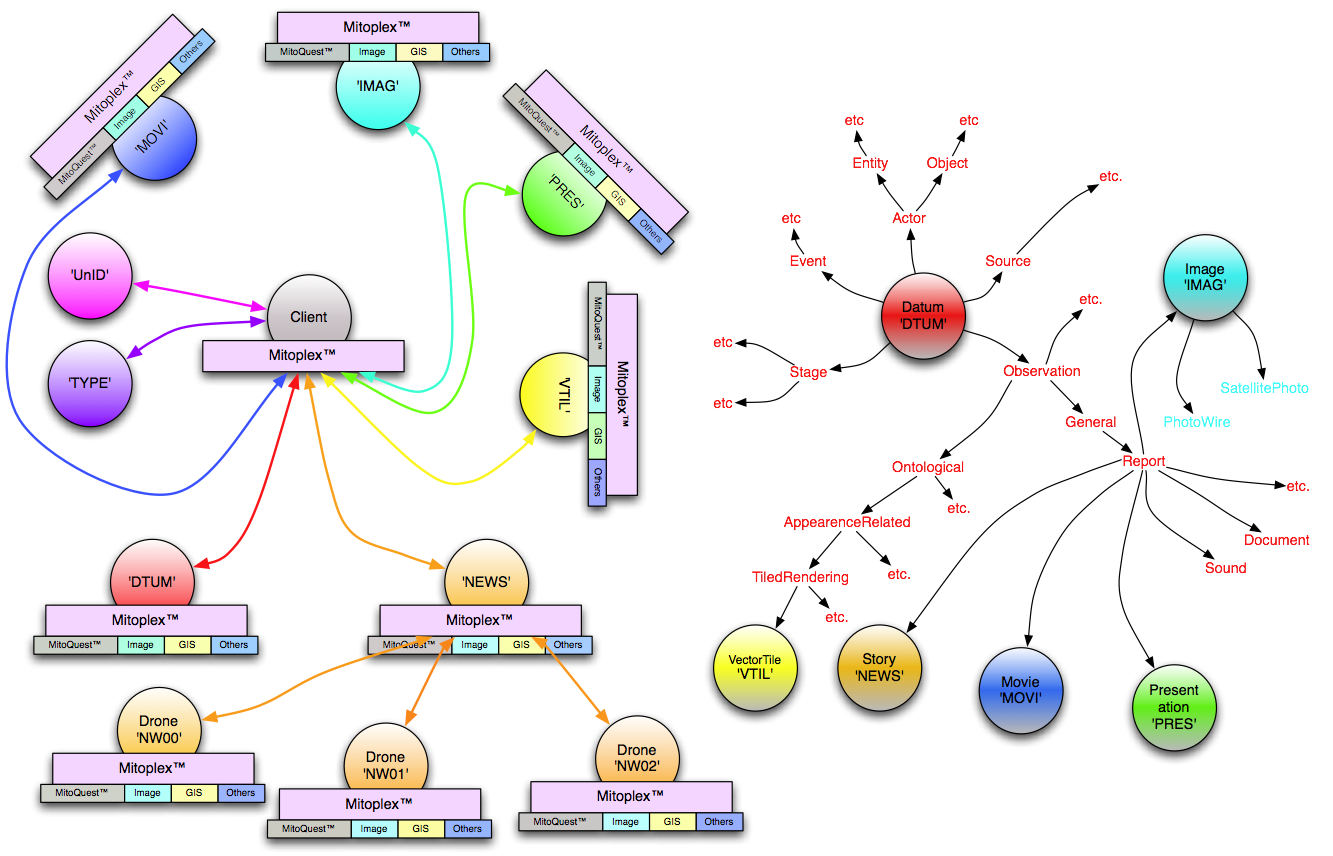 In earlier posts we talked about how the MitoPlex™/MitoQuest™ federation allows distributed persistent storage and queries. In this post I want to explore how we can solve this apparently inevitable ingest rate bottleneck. The answer is to delay making the merge/create decision for as long as possible, and a key part of this strategy is the use of ‘temporary unique IDs’. In a transactional relational database, the server is required to maintain certain guaranteed properties known as ACID (atomicity, consistency, isolation, and durability). To distribute and scale, one or more of these properties must be relaxed somewhat. The approach used by Mitopia® is know as ‘eventual consistency‘ and similar strategies to enable distributed architectures can be found in other NoSQL databases.
In earlier posts we talked about how the MitoPlex™/MitoQuest™ federation allows distributed persistent storage and queries. In this post I want to explore how we can solve this apparently inevitable ingest rate bottleneck. The answer is to delay making the merge/create decision for as long as possible, and a key part of this strategy is the use of ‘temporary unique IDs’. In a transactional relational database, the server is required to maintain certain guaranteed properties known as ACID (atomicity, consistency, isolation, and durability). To distribute and scale, one or more of these properties must be relaxed somewhat. The approach used by Mitopia® is know as ‘eventual consistency‘ and similar strategies to enable distributed architectures can be found in other NoSQL databases.
Temporary Unique IDs
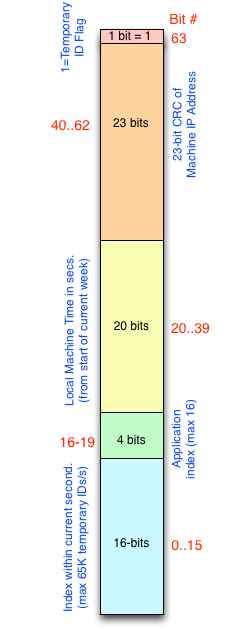 In order to ensure that no machine in a network is hung up waiting to get a new unique ID for an item of data being mined, Mitopia® adopts a unique approach to IDs wherein newly created data is assigned temporary unique IDs which are later converted (or resolved) to permanent unique IDs as the information is merged into the various MitoPlex™ servers that make up system persistent storage. By adopting this approach, we ensure that mining of data can proceed at full speed both on system servers and on client machines. Without this strategy, mining ingest rates are reduced to a relative trickle and the system cannot scale to the massive levels necessary. While this patented approach brings massive performance advantages, it comes at a considerable price in complexity for handling temporary and permanent IDs and the migration path between them. One aspect of this problem is the question of how can any given process on a network ensure that the temporary IDs it allocates cannot possibly conflict with temporary IDs allocated by any other process. The technique Mitopia® uses is to encode the machine IP address into the temporary ID as well as the application index on that machine and the time. This base unique set is then extended by allocating sequential indexed temporary IDs from it. As we have mentioned before, unique IDs are 64-bit quantities which means that all this information must be tightly packed into the available 64-bits. The packing of temporary unique IDs is shown to the left.
In order to ensure that no machine in a network is hung up waiting to get a new unique ID for an item of data being mined, Mitopia® adopts a unique approach to IDs wherein newly created data is assigned temporary unique IDs which are later converted (or resolved) to permanent unique IDs as the information is merged into the various MitoPlex™ servers that make up system persistent storage. By adopting this approach, we ensure that mining of data can proceed at full speed both on system servers and on client machines. Without this strategy, mining ingest rates are reduced to a relative trickle and the system cannot scale to the massive levels necessary. While this patented approach brings massive performance advantages, it comes at a considerable price in complexity for handling temporary and permanent IDs and the migration path between them. One aspect of this problem is the question of how can any given process on a network ensure that the temporary IDs it allocates cannot possibly conflict with temporary IDs allocated by any other process. The technique Mitopia® uses is to encode the machine IP address into the temporary ID as well as the application index on that machine and the time. This base unique set is then extended by allocating sequential indexed temporary IDs from it. As we have mentioned before, unique IDs are 64-bit quantities which means that all this information must be tightly packed into the available 64-bits. The packing of temporary unique IDs is shown to the left.
As can be seen, this packing scheme reserves four bits for encoding the application instance within a given machine and this fact is tied intimately to the maximum number of cloned instances of Mitopia® that can be created on any given machine since to create more that 16 might result in temporary ID collisions which in turn could cause problems during persistence in the servers. Mitopia® adopts the strategy of replicating copies of the application as needed to make optimal use of machine CPU and RAM resources without having to pay the considerable costs of a preemptive scheduling model and all the time that would waste manipulating semaphores.
Due to the encoding used, temporary IDs only remain valid for a period of at most one week. Of course in normal operation, the temporary IDs will no longer be required after a matter of seconds. Servers generally resolve the temporary IDs within minutes of their creation which means that after a week it is quite safe to re-cycle the same temporary IDs without causing confusion. When collections are loaded from disk you may see a progress bar as the system assigns new temporary IDs for all temporary IDs found in the collection. This is because collections may have lain on disk for a substantial time and so it is not safe to assume that the temporary IDs within the collection do not conflict with temporaries from the current cycle. Due to the encoding used, an ID can be recognized as temporary when treated as a signed 64-bit integer simply by determining if it is negative. Obviously due to this encoding, we are limited to 65536 temporary IDs per second/instance which is unlikely to cause a problem for normal mining operations, but could conceivably throttle things back a little when assigning new temporary IDs to an entire collection, as for example in the function PX_AssignNewTemporaryIDs(). If the architecture detects that it might be allocating more that 65K temporaries in any given second, it automatically throttles back the requesting process until a new second rolls over and it is safe again to allocate unique temporary IDs.
The Unique ID Server
In earlier posts we discussed the Types (‘TYPE’) server which is critical to the ability to move from one version of the ontology to another. In this post we shall also examine the other critical ‘administration’ (i.e., non-MitoPlex™) server for system persistent storage to operate correctly, that is the Unique ID (‘UnID’) server. The Unique ID server is a specialized server for parcelling out batches of consecutive unique IDs to the various nodes on a network as they request them. Whenever a new data item is created in persistent storage, it requires a system-wide permanent unique ID (UID). To coordinate UIDs and ensure they are unique the allocator API routine ID_GetNextLocalUniqueID() contains logic to request batches of unique IDs (currently each batch is a block of 8K contiguous IDs) from the Unique ID server when necessary, otherwise it allocates consecutive IDs until it is necessary to request a new batch. Given the rapid pace that items are created in system servers, this approach saves a considerable amount of time by avoiding unnecessary communications. This means that no other server in the system is able to persist new data items until it can establish communications with the Unique ID server. Unlike temporary IDs, the server-based approach for creating permanent unique IDs means that UID blocks are allocated sequentially to whatever server requests them so the UID itself does not directly contain the machine IP address involved. Instead, the UID server maintains a simple database of unique ID blocks and the process they were allocated to. The UID server requires only an output folder in which it stores the allocated batches in a Mitopia® string list file (Batches.STL) and the current highest batch start ID in the text file (BatchID.TXT). The Unique ID server is capable of performing backup and restore to/from its backup folder and so ensures that in the event of a system-wide restore, the UID batch information remains consistent. The server-based solution to uniqueness cannot be used for temporary IDs because these are created so early in the startup sequence for all machines that it is not yet possible to talk to the ID server since communications initialization is not complete.
For this and other reasons, it is strongly recommended that all the administration servers be run on a separate dedicated server machine from any MitoPlex™ servers that is not used for any other purpose. The administration machine itself does not need to be high performance since the load on these servers is minimal regardless of system size. The machine does need to be available and running at all times otherwise the system eventually grinds to a halt. When starting up a system from scratch, the administration server machine should always be started before any others.
Decoupling the ingestion process
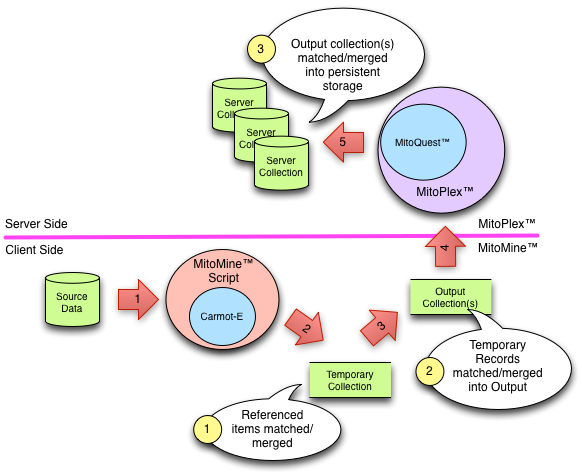
The Three Phase Ontology Merge
Given the discussions above, we can now examine how Mitopia® decouples and parallelizes the data ingestion process. The first stage of the process is handled by MitoMine™ which creates as output one or more flat memory model data collections containing interconnected data described by the Carmot ontology and utilizing purely temporary IDs. Because this stage of ingestion merges only the data coming from the specific source, and does so utilizing temporary IDs, it never needs to check with the servers (or even with other parallel mining tasks) to make an initial intra-collection merge/create determination. This allows the computationally and resource intensive mining process to be completely decoupled from the servers and distributed throughout the client machines, it therefore scales linearly and indefinitely without regard to system size. What remains is the process of determining what to do with the ontological records in the output collections when they are persisted (which may be immediate or some time later). Fortunately all data both in the servers and from the newly ingested source is now held in binary form as described by the ontology and so the comparison process can be accomplished far more rapidly than would otherwise be the case. In addition the collections themselves already contain many connections, and these connections can help disambiguate records whose fate might otherwise be in question.
Each collection may contain thousands of interconnected records (using temporary IDs) when it is sent to the servers. Because of the TID scheme described, there is no possibility of TID confusion between two collections for up to one week, which is vastly more than enough time to persist and resolve everything across the server cluster. When a server nodes receives any given collection, it sends the collection as a whole to all other nodes that might potentially contain a match. At the same time it performs a match scan for the collection with its own data. The fact that this distribution is binary and for the entire collection saves considerable bandwidth and back-and-forth communications for individual records. Remember that Mitoplex™ organizes records according to the ontology, so each node only need examine the records of types for which it is responsible. The respondent nodes then send back information giving the probability of any record within their local data set being a match for the records involved (if any). How these probabilities are computed is beyond the current scope. The original server node then determines which other server cluster node has the best claim to matching various nodes within the collection (including itself of course) and sends a message to those nodes to go ahead and merge the records they have won possession of. The original node creates new records for all collection nodes (of its type) that remain. As specific server nodes create new permanent records or merge with existing ones, they transmit (in response to requests) to other involved servers the mapping from temporary ID to permanent. In a fairly short time causes all server nodes to reach a consistent set of connections without any remaining temporary IDs.
This merging logic described above is a considerable simplification of what really goes on, however, the end result is that server nodes can ingest and persist new data largely in parallel once the voting process described above completes. While this scheme does not scale completely linearly as does the mining front end, it does nonetheless scale quite efficiently, and is capable of supporting truly massive ingestion rates given sufficient computing nodes. With suitable machines, there are likely 16 distinct copies of Mitopia® servers running in each server node (limited by the TID scheme described above), and so within this sub cluster, network communications overheads are essentially eliminated. We will explore these issues in more detail in later posts.
Ultimately, the entire process is designed to keep and process the data in a complete and fully interconnected binary form using temporary IDs until the very last time possible for the merge/create fork which is the source of potential bottlenecks. Temporary IDs are thus a form of constructive procrastination.