
Much of this post and the illustrations within are taken from a Semantic Web lecture by John Davies, BT.
The motivation behind the semantic web, for which OWL is the current underpinnings, was essentially to find some way for a computer to understand ‘meaning’ in the vast textual information content of the world wide web in order to assist computer users to answer more complex questions than those that could be answered by simple keyword text searches. This goal is still largely unrealized, although some progress has been made in limited areas. To understand why this is such a serious problem consider the appearance of a typical web page such as that shown below:
This page can be quite readily understood by a human being, however the page contains a vast amount of information that is communicated by such things as page layout, font sizes, color, sequence and organization as well as hyperlinks to related content. This information is largely held in the HTML markup tags used to lay out the page which are not displayed to the user but are nonetheless critical to understanding, thus the semantic content is not easily accessible to computers.
The human sees:

Whereas the computer from a cognitive point of view does not understand either the text, or the markup, and so it sees:

The solution that the web has adopted to this problem is to use XML markup with meaningful tags:

But of course, the next problem is how the computer understands the meaning of the tags themselves in any standardized and cognitive way across multiple web sites, all with different content and focus. The truth is that without addressing this issue, to the computer, the web page still looks as follows:

We need to add the semantics of the tags so that they can meaningfully be used to interpret the content that they enclose. One approach to this would be to get global agreement on the meaning of such annotation tags but this approach is fraught with problems and even if agreement could be reached, some formalism is needed to extend the annotation tags as necessary.
The solution chosen was to use semantic ontologies to specify the meaning of the annotations via a formalized ontology language thus allowing different systems to interpret data from other sources by examining the published ontology for that site and then interpreting the site contents which is fully tagged according to the site ontology. Semantic ontologies allow new terms to be defined by combining existing ones as well as formally defining the meaning of such terms. Just as importantly, it is now possible to specify the relationships between terms in multiple ontologies thus allowing sharing of knowledge.
The resultant architecture required in order to get semantic ontologies to perform the goal of the semantic web appears as shown below. Note that the entire architecture is built directly on top of Unicode and XML, that is, this is an architecture for which all the data, the ontology itself, and everything it can be used to express and manipulate, is based on text. This is as one might expect given the original target, which was to understand the textual content of the web pages that make up the world wide web. We have shown in an earlier post (see here) that such a text-based approach imposes an unacceptable performance penalty in distributed systems exchanging complex data at high rates. Moreover the basic model by which things are referenced is the ‘document model’ (i.e., the URL) so this is a Data Level (DL) architecture onto which a completely distinct Knowledge Level ontology has been independently (and incompatibly) grafted – that is the use of an ontology has absolutely nothing to do with how data is stored or referenced. It is fundamentally a mess, but a mess that was forced into being by the need for backward compatibility with the World Wide Web (which we have said is a DL not a KL technology). Not surprisingly therefore the semantic web faces huge hurdles to realize hoped for benefits.
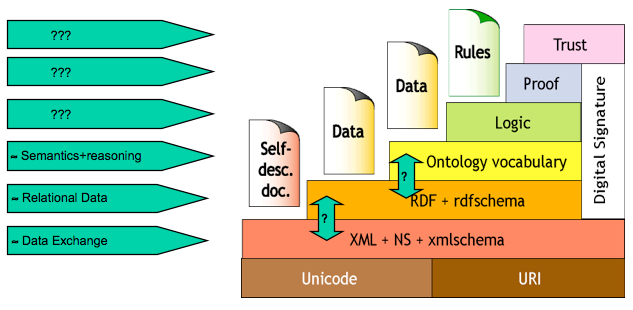 |
| Architecture of the Semantic Web |
Note also that various portions of this architecture are still in flux and much development work needs to be done before it is practical for any realistic ontological systems based on this approach to operate in unrestricted domains. In future entries we will contrast the Mitopia® approach to ontology with the semantic approach used in all other ontological systems as described in this post.