
 In the previous post we introduced Mitopia’s unique and patented heteromorphic language concept and showed the huge productivity and adaptability improvements possible over standard programming languages. In that discussion we deliberately limited ourselves to examples that in no way depend upon leveraging any ontology or other capabilities associated with the endomorphic language. But such examples are like fighting with one hand tied behind your back, so the eventual goal is to ‘drop the other shoe’ and explore the full potential of heteromorphic languages including their unparalleled power for data mining and integration applications. First however, we need to present a few more details regarding nested entangled parsers, and the Carmot-E endomorphic language suite in particular. A brief introduction to these issues is the subject of this post. Trust me, dropping the other shoe is coming…
In the previous post we introduced Mitopia’s unique and patented heteromorphic language concept and showed the huge productivity and adaptability improvements possible over standard programming languages. In that discussion we deliberately limited ourselves to examples that in no way depend upon leveraging any ontology or other capabilities associated with the endomorphic language. But such examples are like fighting with one hand tied behind your back, so the eventual goal is to ‘drop the other shoe’ and explore the full potential of heteromorphic languages including their unparalleled power for data mining and integration applications. First however, we need to present a few more details regarding nested entangled parsers, and the Carmot-E endomorphic language suite in particular. A brief introduction to these issues is the subject of this post. Trust me, dropping the other shoe is coming…
Nested Entangled Parsers
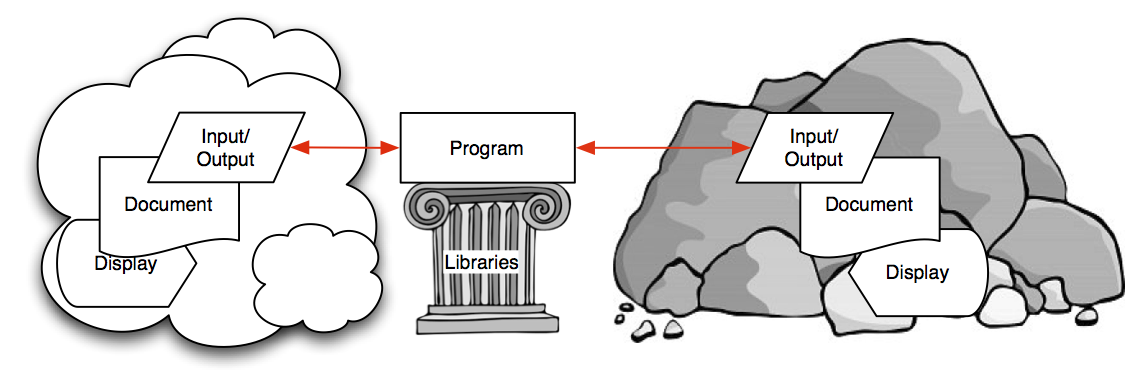 The discussion of heteromorphic languages given in the previous post makes it clear how the evolution of the outer ectomorphic parser state controls the program flow within the endomorphic suite, however, if this were all that was possible, we would have created what is essentially a one-way language where no feedback in the other direction from the ‘rock’ to the left side of our diagram (see discussion here) would be possible. Clearly to handle any conceivable programming situation, we cannot limit ourselves in this way, we must allow the ‘inner’ endomorphic language and state to influence and alter things in the ‘outer’ ectomorphic environment including of course the flow of the ectomorphic parser itself. To accomplish this we must ‘entangle’ the nested parsers of the heteromorphic language.
The discussion of heteromorphic languages given in the previous post makes it clear how the evolution of the outer ectomorphic parser state controls the program flow within the endomorphic suite, however, if this were all that was possible, we would have created what is essentially a one-way language where no feedback in the other direction from the ‘rock’ to the left side of our diagram (see discussion here) would be possible. Clearly to handle any conceivable programming situation, we cannot limit ourselves in this way, we must allow the ‘inner’ endomorphic language and state to influence and alter things in the ‘outer’ ectomorphic environment including of course the flow of the ectomorphic parser itself. To accomplish this we must ‘entangle’ the nested parsers of the heteromorphic language.
Perhaps the simplest and most obvious form of entanglement between the ectomorphic parser state and the endomorphic language is the Carmot-E if/ifelse construct. In this construct, the occurrence of a “<@1:5 if (condition)> cond_production” sequence in the grammar has the effect of discarding the production cond_production off the outer ectomorphic parser stack if the condition specified within the ectomorphic expression is not met. This means that any conditional statement based on the state of the endomorphic environment at the time has the ability to alter how the ectomorphic language parses the input file without the ectomorphic language being aware that this decision was made for it. In earlier sections we referred to problems with handling context sensitive and non LL(1) grammars and stated that these problems can be very hard to handle with a one-level grammar. However, since the endomorphic language and environment has access to whatever mechanisms the system might provide for determining and storing ‘context’, another way to look at the idea of ‘entangled’ parsers is that it provides a simple formalism and means to overcome the parser theory failings as far as handling context sensitive grammars. Because the cond_production is itself a production which may be of arbitrary complexity, this conditional statement is inherently ‘block structured’. By adding the “<@1:5 ifelse (condition)> cond_prod1 cond_prod2” construct to Carmot-E, we have all the building blocks we need to implement explicit looping behaviors and all kinds of other constructs (for, while, do until, switch, etc.) that are required of a generalized programming language, but which are context sensitive and cannot be handled by regular grammars alone. Just to be clear, we have made it so that the ‘outer’ ectomorphic language statements are no longer in control of their own program flow, not even in a parsing sense, since the flow can now be altered unannounced by the endomorphic language. In other words, we have extended our language so that the only portion of it that was at least controlling flow within one production, can no longer be sure that this is so. The two parsers are entangled so that each has the ability to control the program flow within the other when necessary, and both are under control of the external source data. We now have a complete feedback loop between both sides of our generalized programming diagram above. The applicability to data mining and data integration problems should be readily apparent.
But of course entanglement is far more pervasive and subtle that just the obvious examples like the if/ifelse construct. As we shall see later, mechanisms are provided to alter the input token stream to the parser for various purposes (e.g., handling block comments) by the registered ‘recognizer’. This is a means for reverse entanglement that we can use for even more exotic purposes, particularly since our registered ‘plugin’ that is executing the endomorphic language statements has access to a shared ‘context ID’ as does the ‘resolver’. Suppose that context ID was shared between both the ‘inner’ parser and the ‘outer’ parser, now we open up all kinds of possibilities. This kind of shared ‘context ID’ between both parsers of a heteromorphic language is commonplace (though not required) so that the ‘inner’ parser can communicate ‘modes’ with the outer parser’s ‘resolver’ function and thus change how it perceives the ‘source’ content. This kind of capability is in fact used extensively particularly in complex MitoMine™ situations where the endomorphic language can directly control the ectomorphic parser (and the left hand side environment) in multiple ways, including (but not limited to) the following:
- The $Ask() function can directly interact with a user through an endomorphic language specified dialog.
- The $Exit() function allows the endomorphic language to force the ectomorphic parser to exit.
- The $SetOptions() function can dynamically alter the options in effect for the ectomorphic parser.
- The $ReplaceLine() function replaces the current input line being processed by the ectomorphic parser and forces that parser to re-parse the line as its new ‘source’ input.
- The $GetSource() function can be used to obtain all or part of the endomorphic ‘source’ input which can be edited by the endomorphic language by using the function $PutAllSource() to replace all or part of the ectomorphic source.
- The $SkipInput() function can be used to skip the ectomorphic parser over an required portion of the ‘source’ input. The $ScanInput() function can be used to skip over ectomorphic input until a specified pattern is reached.
The ectomorphic language can dynamically create and invoke additional nested (to arbitrary levels) MitoMine™ heteromorphic variants which can share the original ‘input’ stream and thus can override the original ectomorphic parser.
Custom ‘plugin’ meta-symbols can be registered with both the ectomorphic and the endomorphic languages which can use any mechanism they wish to interact with or alter the left hand side environment.
As can be seen from the partial list for MitoMine™ above, the MitoMine™ data mining/integration heteromorphic language provides for an almost limitless variety of feedback mechanisms from the endomorphic language and environment to the left hand side of our generic program diagram.
Other Mitopia® heteromorphic language suites provide other feedback mechanisms, for example, the MitoPlex™ federated query capability is entirely built as a heteromorphic language (MitoPlex™ is the ectomorphic language) where the endomorphic components (referred to as ‘containers’ such as MitoQuest™) have multiple variants some of which can issue deeply nested MitoPlex™ queries (expressed in the same heteromorphic language), thereby creating communications spanning the entire network of machines implementing a Mitopia® installation, including both servers and clients. All this functionality, that is all of Mitopia’s persistent storage and querying capabilities from the client to all nodes within the server clusters, is just one example of a heteromorphic language suite; in this case where the connections between each entangled parser pass over the network and are referred to as ‘queries’ in one direction and ‘hit lists’ in the other.
Carmot-E
Now that we have described the abstract form of a heteromorphic language suite, we can examine the most prevalent endomorphic language used within Mitopia®, that is Carmot-E. As discussed before, the Carmot ontology language underlies most of what Mitopia® does. Carmot-D is Mitopia’s Ontology Definition Language (ODL) and drives virtually all aspects of the system. The Carmot language however comes in two variants, Carmot-D and Carmot-E.
Carmot-D is a language of type definitions only, and is designed to describe the types that make up the ‘world model’ used the by system and its users. Carmot-D was deliberately designed so that it contains no means for creating executable programs within the language, no assignment operator, and no ability to declare local variables and/or types. Everything in Carmot-D is targeted at understanding, representing, and discovering the system ontology, it is not a language designed to ‘do‘ anything, indeed it is designed to discourage that.
The primary reason why Carmot-D has no concept of a run-time program flow is that if one were to add these run-time abilities to a language whose very purpose is to discover what the external ODL specification says, there would be the temptation to declare local types and bury logic and behaviors within the code. It is precisely to avoid this inevitable temptation within standard programming languages that the decision was made to split the Carmot language into two variants.
Carmot-E is the run-time part of the pairing, it is designed to manipulate at run-time, data collections held in the ontology defined by Carmot-D. Once again, to prevent programmers from the temptation of standard language techniques, Carmot-E lacks any ability whatsoever to define new types. It is not even possible to specify anything (e.g., a register) to be of a known type. Every bit of data manipulated by Carmot-E must be either of a very few fundamental types (e.g., integer, real, string), or it must be defined by the Carmot-D ontology for the system which thus irrevocably defines its type and the type of any fields within it. To set the type of a ‘variable’ in Carmot-E, you must assign something of that type to it (i.e., it is a ‘dynamically typed’ language). The Carmot-E programmer is unable to rustle up local types and use them (and the assumptions and limitations they inevitably imply) to manipulate data.
This rigid separation allows the Carmot-D ontology to drive all persistent storage, analysis functions, user interface, etc. in an unambiguous way since it is impossible to define any other types of data except through Carmot-D. This means all data within the system can be displayed, persisted, and manipulated through the ontology, no exceptions. Conversely, the restrictions on Carmot-E ensure that run-time programmers cannot stray from the original philosophy that gave rise to Mitopia®, and thus cannot unintentionally render the system fragile and non-adaptive by burying things inside the code (as they would in a standard programming language) that should be explicitly associated with and discovered from the data. It is the ability to unintentionally ‘ossify’ a system through these buried code assumptions that tends to render systems created using standard programming languages obsolete and non-adaptive.
In our generic diagram of “what programmers do” above, we said that the right hand side of any given programming undertaking can be thought of as the ‘system’ and contains things that are ‘fixed in stone’. In Mitopia’s case the Carmot ontology is that right hand side, though it is hardly fixed since it can be changed at any time. Carmot-E is the run-time part of the Carmot ontology language pair, and thus it is most frequently used as the endomorphic language for heteromorphic language suites that must be tied to Mitopia’s ontology. Because of its prevalence, and because so many other ‘suites’ are built upon it, we must describe Carmot-E in detail herein before we can discuss other technologies in detail. Remember however that Carmot-E is just one example of an endomorphic language and environment.
Syntax
The listing below gives the lexical analyzer specification for the Carmot-E language:

We can see from the specification above that Carmot-E supports an operator set that is functionally and lexically a subset of those provided by the C language. These operators are well known, so it is clear that Carmot-E implements these operators by referencing this facility. Evaluation of commutative operators (e.g., ‘+’) is always left-to-right. This is particularly important since it allows string concatenation using the ‘+’ operator. The ‘oneCat’ lexical exceptions are the use of the ‘\’ character in front of all occurrences of the ‘>’ character within operators, and the addition of the ‘ifelse’, ‘[[‘, and ‘]]’ tokens. The ‘\’ character is required in front of ‘>’ characters because Carmot-E is an endomorphic language which means that Carmot-E statements will occur within meta-symbols of the form <@n:m: Carmot-E statements> and thus it is important that any ‘>’ characters within the Carmot-E statements are not interpreted as the ‘>’ that closes the end of the meta-symbol by the outer parser’s recognizer. While this is possible to accomplish by adding ‘smarts’ to the outer parser’s recognizer specification, the decision was made to add the leading ‘\’ within the Carmot-E language so that the ‘>’ characters are ‘escaped’ (by the preceding ‘\’) when recognizing plugin meta-symbols. This specialized behavior within the plugin recognizer specification is internal to the parser abstraction and thus allows the use of escaped ‘>’ characters in any endomorphic language.
The ‘ifelse’, ‘[[‘, and ‘]]’ tokens will be discussed later. As far as IDENT symbols defined by the Carmot-E language (and recognized by the ‘catRange’ table), the table below defines these:
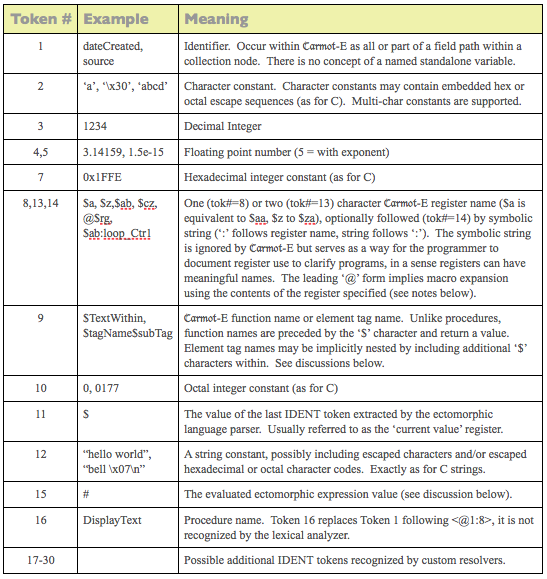
Given the lexical analyzer specification and the IDENT token set and explanations, the Carmot-E parser specification given below should be relatively easy to interpret. Virtually all the operators are implemented by the parser abstraction’s built-in plugin zero so the area of the grammar between the production for ‘expression’ and that for ‘primary’, is essentially standard and will not be discussed further. Operator precedence rules are exactly the same as for C. All integers are manipulated as 64-bit, all reals as ‘double precision’. Booleans are represented as (and interchangeable with) 64-bit integers where zero is considered FALSE and non-zero is TRUE. By convention procedure names should start with an upper case letter to distinguish them from field names in the ontology which always start with a lower case letter.

Programming Environment
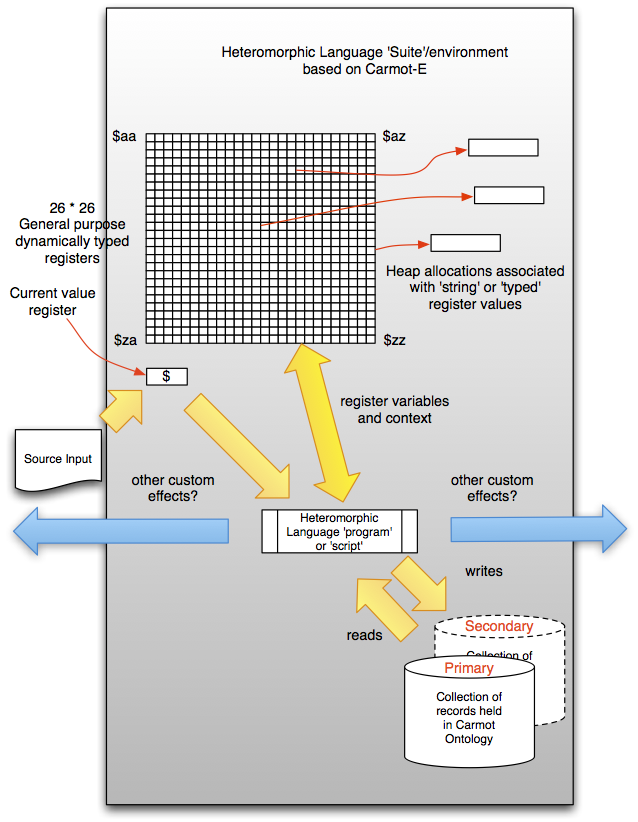 The drawing above depicts the programming ‘model’ for any heteromorphic language suite based on Carmot-E as the endomorphic language. The key features that Carmot-E provides are:
The drawing above depicts the programming ‘model’ for any heteromorphic language suite based on Carmot-E as the endomorphic language. The key features that Carmot-E provides are:
- access to a large generalized register set ($aa..$zz) which are dynamically typed (that is they each acquire the type of whatever was last assigned to them).
- A ‘current input’ register ‘$’ for passing IDENT tokens from the ectomorphic parser to the inner Carmot-E language.
- The ability to associate a Mitopia® collection of data held in the ontology and access and manipulate collection content via the Carmot ontology. Access to both ontological fields and collection element tags (e.g., $tagName) is supported.
- A complete suite of programming constructs including function calls, operators, etc. Also provides control over ectomorphic parser flow.
- Access to all functions and procedures defined by MitoMine™ from other heteromorphic suites based on Carmot-E. Ability to register and invoke additional custom functions and procedures.
This last point is critical, it means that any functionality built using a heteromorphic language suite that incorporates Carmot-E is able to use not only the capabilities provided directly by Carmot-E, but also most of the hundreds of built-in procedures and functions provided by MitoMine™. This means that out of the box, without any real effort by the programmer, a heteromorphic language based on Carmot-E already provides an extensive library of functionality, targeted primarily at text processing. Additional language specific functionality can be added to extend this ‘library’ as required by the application.
Note also that because Carmot-E provides access to the collection element tags functionality provided by Mitopia’s type collections abstraction, the Carmot-E client language is free to organize data in any number of ways that are ‘outside’ that defined by the system ontology. This freedom obviously also includes the ability to define new custom types using the routine CT_DefineNewType() which then become known to Mitopia’s type system and can thus be manipulated ontologically within the associated collection(s) without resorting to element tags.
Tying Carmot-E to a Heteromorphic Language Suite
The Carmot-E endomorphic parser environment requires a single shared parser context record with the outer ectomorphic parser that makes up the the nested pair. Since the type and content of the Carmot-E context record is not public, this means that all custom (i.e., not internal Mitopia® code) heteromorphic suites with Carmot-E as the inner parser must declare the entire shared parser context record so that it starts with an anonymous memory block (initialized by calling CT_MakeCarmotEParser) declared as follows:

The constant ‘kCarmotInterpContextSize’ is guaranteed to be large enough to contain the required Carmot-E interpreter context so that the custom code can directly refer to any custom fields declared later within the custom context type ‘MyInterpContext’ while still being able to pass the same context ID reference to the Carmot-E API calls. To associate the inner Carmot-E parser with the heteromorphic language environment, the generic parser initialization function for the custom API would look something like the following:

Then within your outer parser custom ‘plugin’, where it is time to execute the Carmot-E parser (e.g., <@1:5> in the MitoMine™ example), you extract the plugin ‘hint’ and invoke Carmot-E as follows:
![]()
Where ‘p’ is a pointer to the outer parser context (i.e., MyInterpContext in the example above). The final thing that needs to be done is to designate the ‘node’ within the collection associated with the heteromorphic language suite that is to be used whenever access to a field occurs using CT_SetPrimaryNode(). Where this happens within your custom API may vary depending on where the collection itself comes from. In the case of MitoMine™ for example the node is created within the <@1:4> ‘plugin’ call. In other cases (e.g., the GUI interpreter), the ‘node’ may be designated explicitly by the invoking code (e.g., through the SetNode() GUI interpreter procedure call). See also the section below describing the current input register ‘$’.
In most cases (e.g., MitoMine™, GUI interpreter, etc.) where you encounter Carmot-E as the endomorphic language, the API suite to the heteromorphic language has already done all the work necessary to tie in the Carmot-E functionality and also the connections to the left and right side of our generalized programming diagram so you do not need to make any Carmot-E API calls yourself, you just need to understand how to write Carmot-E program fragments within the outer ectomorphic parser grammar provided by the higher level abstraction.
General Purpose Registers
Because the Carmot-E endomorphic language provides all access to the internal register set, there are no API functions provided to allow custom code to access register values. This is a deliberate choice because the memory handling associated with register accesses must be managed very carefully to avoid leaks or memory errors, so this code is all internal to Carmot-E. The 676 (26*26) general purpose registers that make up the Carmot-E register set are more than enough to satisfy the ‘local variable’ needs of any heteromorphic program built upon Carmot-E. Register values are initially all empty/undefined and as they are assigned they take on the fundamental type of the value assigned to them. Carmot-E recognizes just five fundamental types that can be held in registers, they are Integer (64-bit), Boolean (held as a 64-bit integer), real (held as a ‘double’), string (held as a heap allocated C string handle), and reference (type ET_ViewRef). These fundamental types align closely with the fundamental types supported by Mitopia’s parser abstraction (Integer, Boolean, Real, Pointer, and Reference) except that in registers Carmot-E replaces the generalized Pointer type by a heap allocated handle to a C-string. Carmot-E makes extensive use of the Reference type. It is not possible (except through private APIs) within Carmot-E to assign any other type to a register. The use of handles to contain C-strings is driven by the fact that string concatenation is a common operation within Carmot-E programs (the ‘+’ operator of built-in ‘plugin’ zero concatenates string operands). String concatenation within a heap allocated handle is trivial to implement since handles, unlike pointers, can always be resized without invalidating any references that might exist. What this means is that the Carmot-E register set may contain multiple registers that reference external heap memory at any given time. Since Carmot-E based parsers may be shared across thread boundaries, this makes memory management a considerable headache to handle correctly. For this reason the functions CT_PossessCarmotEParser() and CT_DisPosessCarmotEParser() are provided, and the function CT_KillCarmotEParser() and CT_ZapAllRegisters() each ensure that any dangling memory references are cleaned up.
The symbol ‘$aa‘ is a register designator. There are 26*26 registers ‘$aa‘ to ‘$zz’ which may be used to hold the results of calculations necessary to compute field values and/or local variables. You may use a single character register designator instead thus ‘$a‘ is the same as ‘$aa‘, ‘$b’ is the same as ‘$ba‘ etc. Register names can optionally be followed by a ‘:‘ and then an arbitrary alphanumeric text string (including ‘_’) which is completely ignored by the parser but serves as a convenient way of documenting the code to indicate what is in the register concerned. For example the syntax “$i:LoopCounter” might be used to make it clear what the contents of register $i (that is $ia written out in full) are being used for. All registers are initially set to empty when the parse begins, thereafter their value is entirely determined what is assigned to them.
The syntax ‘@$a‘ is effectively macro expanded to replace the occurrence of ‘@$a‘ by the string value in $a. This means that supposing you have a field in the current record called ‘name‘ then the sequence $a = “name”; @$a = “Fred Bloggs”; will result in the ‘name‘ field of the record being assigned to “Fred Bloggs”. Similarly $a = “$ab”; @$a = “Fred Bloggs” will result in the assignment of “Fred Bloggs” to register $ab. It is often handy to use this macro form inside what are effectively production ‘subroutines’ that take a number of indirect parameters. For example, take the MitoMine™ heteromorphic language ‘subroutine’ portion below:

The addto_CommaList production above is basically a ‘subroutine’ that takes as its parameters the registers $ra:ListName and $rb:ItemName. Register $ra must be set up prior to invoking the production to be the name of some other storage location being used to accumulate a comma separated list of names for example (i.e., $ra = “$al” means that register $al contains the comma separated list so far). Register $rb:ItemName must be set up before the invocation to contain the item name to be added to the list (e.g., $rb = $a; $a = $TextBetween($og,”(“,”)”) sets up register $rb to specify that the actual item name string is held in register $a, and then sets up the content of $a by calling the $TextBetween function to extract whatever is between the braces in the current content of register $og). Now adding the production addto_commaList after these setup calls will make the appropriate addition to the list. The code of the ‘subroutine’ first checks if the list is empty by following @ra:ListName to discover that the list is held in register $al, so effectively the ifelse condition is $IsEmpty($al). The rest of the logic can be followed simply by expanding the references implied by ‘@$ra’ and ‘@$rb’. The $TextContains condition within the production for checkin_commal ensures that if the list already contains the item name given, it is not added twice.
Note also the ifelse condition in the production do_comma_add which extracts the first character of the content of $ra (not @$ra) to see if the storage element is a field in the ontology (first character != ‘$’) or a register (first character == ‘$’). Depending on which is true either the <@1:5:@$ra = @$ra + @$rb + “, “> or the <@1:5:@$ra = @$rb + “, “> production is executed. This logic is necessary because when assigning values to registers the new value overwrites the previous value completely whereas when assigning values to string fields within the ontology, the default behavior is to concatenate the new string onto the end of any string already in the field. Because the caller might have passed a field path for the comma delimited list location instead of a register name (for example $ra = “aliases”), it is important that our production ‘subroutine’ takes this into account. This ability to use productions containing embedded endomorphic language logic and statement is an incredibly powerful feature conferred by the heteromorphic language concept and facilitated by the Carmot-E ‘@$r’ register indirection construct. Without this construct in the example above we would have to repeat all this logic everywhere in the grammar that we want to add something to any comma separated list. This could lead to the grammar exploding unnecessarily. Using ‘subroutines’ like this, one production set can handle multiple different comma separated lists held in different locations and used for different purposes in the grammar. Note that this ‘subroutine’ is comprised entirely of endomorphic program fragments and productions, that is it is independent of the outer ectomorphic grammar and all the ectomorphic productions within it have empty FIRST sets. This is very common in heteromorphic programs.
As mentioned above, the general purpose registers are dynamically typed (within the 5 basic types supported) so that the assignment “$aa = 1” will set the type of register $aa to Integer. Similarly “$ab = 1.0” sets the type of $ab to Real, and “$ac = “Hello World”” sets the type of $ac to String. Following these three assignments, the statement “$ac = $aa” will dispose of the heap string allocation previously associated with $ac and set its type to Integer and its value to 1. Note also that given the assignments earlier, the statement “$aa = $aa / 0.5” will set the type of $aa to Real and the value to 2.0.
When assigning from a field within the ontology to a register, the register acquires the fundamental type associated with the field, so that “$ba = anIntFieldName” sets the type of $ba to be Integer and the value to be whatever was in the integer type descendant field ‘anIntFieldName’. Similarly for field types derived from the real number type. If the field type in the ontology is derived from an array or reference to ‘char’ then the field is assumed to contain a C string which is assigned to the register. Thus “$bb = name” sets the type of register $bb to String and the value to whatever is in the ‘name’ field of the current designated collection node.
This leaves only the question of what happens when you assign a persistent (#) or collection (## or @@) reference field to a register value. In the case of a persistent reference field, if the field already has a unique ID value assigned, the register type becomes Integer and the value matches the 64-bit local unique ID within the persistent reference, otherwise if the persistent reference has a ‘name’ value, the register type becomes String and the value matches the referenced item name.
If the field assigned to a register is a persistent collection reference (## field) or a relative collection reference (@@ field) then the value assigned is the content of the ‘stringH’ portion of the reference (if any) and the register type becomes String. To understand why this is so, read later posts.
If you attempt to ‘read’ a value from a register that has not yet had a value assigned to it, you will get a ‘kUninitializedValue’ error and the parse will fail. You can suppress these errors using the ‘kPermitEmptyEvaluation’ parser option. With this option in effect, the assignment $a = $b where $b is uninitialized will silently cause $a to be uninitialized afterwards.
The Current Input Register – $
The primary means whereby the endomorphic Carmot-E program obtains chunks of the ectomorphic ‘source’ in order to operate on them is through the ‘current input’ register, denoted by the single character token ‘$’ (token number 11). The content of the ‘$’ register is determined by the most recent IDENT token accepted by the ectomorphic parser so for example in the heteromorphic grammar sequence production_one <3:DecInt> <@1:5:$a = $>, the value of register $a will be assigned to be the Integer value just accepted by the ectomorphic parser. Similarly the sequence production_two <1:Identifier> <@1:5:$a = $>, results in $a being assigned to be the string value accepted as an ectomorphic match for the <1:Identifier> token. In general, the value of ‘$’ at any given time can be thought of as equal to the value of the top element of the ectomorphic parser’s evaluation stack. However, the ectomorphic parser generally does not do anything with the IDENT tokens that it encounters, and so it must usually implement an aggressive evaluation stack (EStack) cleanup strategy to avoid stack overflows.
In MitoMine™ strategy, the ectomorphic parser EStack is wiped completely after each MitoMine™ record acquisition completes which ensures that we do not get an ectomorphic parser evaluation stack overflow. The code in the ectomorphic resolver causes the content of the Carmot-E ‘$’ register to be zapped immediately (using CT_ZapCurrentValReg ) after each ectomorphic token is accepted and records the EStack depth at the time.
The code within the MitoMine™ ectomorphic ‘plugin’ <@1:5> which actually invokes the inner Carmot-E parser checks if any IDENT token has been pushed by the ectomorphic parser since the last ‘accept’ completed (which can be determined from the saved value of ‘zapped’), the ‘plugin’ extracts the ‘evaluated’ value from the top of the ectomorphic EStack and assigns it appropriately to the Carmot-E ‘$’ register using CT_SetCurrentValReg(). This <@1:5> logic is a one shot if the ‘$’ register already has a value (by using CT_HasCurrentValReg) so that the value of ‘$’ remains available to subsequent <@1:5> productions, but is wiped as soon as the next ectomorphic IDENT token is accepted. This strategy means that the ‘$’ register will be uninitialized most of the time and will have a value of the appropriate type within any call to <@1:5> providing it is immediately preceded by an IDENT token. Other heteromorphic languages that use Carmot-E as the endomorphic component usually implement similar strategies. The utility of this approach is most obvious in a data mining or data integration application (like MitoMine™), however, the content of ‘$‘ might just as easily be a user interface action, a query, or any number of other things.
The Ectomorphic Expression Symbol – #
The ‘#’ symbol occurring by itself refers to the ‘evaluated’ (i.e., PS_EvalIdent(aParseDB,TOP)) value of whatever is on the top of the outer ectomorphic parser’s evaluation stack (EStack). Lets say that again: when the ‘#’ appears in the endomorphic Carmot-E source, this causes the OUTER ectomorphic parser to evaluate the top of its EStack and pass the result back to the Carmot-E program. This evaluation process may convert the symbol value in EStack[TOP] to either an integer, a real, or possibly a string. This construct is used when the outer ectomorphic language contains expressions for example, and the inner endomorphic language wishes to evaluate the expression and obtain the (usually) numeric result. Note that these expressions are in the ‘outer’ language, not the ‘inner’ Carmot-E language, which may of course contain expressions of its own.
The key ability this confers to a heteromorphic language is that values within the source file can be expressed as arithmetic expressions, not just simple numeric constants. It also means that the ectomorphic language itself can perform arithmetic computations (using built-in ‘plugin’ zero or otherwise), and can implement custom procedures and functions the results of which can actually be accessed as required from within the endomorphic Carmot-E grammar. In other words both the ectomorphic and the endomorphic language grammars can be full-up languages containing custom function code which can be invoked from the other language of the pair. This ‘#’ symbol is therefore yet another subtle form of entanglement between the parsers of heteromorphic languages built upon Carmot-E. The potential uses of this capability to deal with complex interactive situations are extensive. The utility of the Carmot-E API function CT_GetParentParseDB() for implementing features like this within custom code should now be clear. Heteromorphic languages are free to put ‘smarts’ wherever they are most appropriate, either in the endomorphic language, the ectomorphic language, or both.
As can be seen from the discussion above, Carmot-E, at least as far as registers are concerned, is a dynamically typed language. We will explore additional Carmot-E functionality in future posts.