 In the previous post, we introduced the overall architecture of Mitopia’s MitoPlex™ server federation. In this post I want to look at the architecture of MitoPlex™ queries in a little more detail. Mitoplex™ and MitoQuest™ together provide a SQL alternative query infrastructure with vastly greater expressive power. Listing 1 below presents the complete syntax for the MitoPlex™ query language. As you can see, the language is very small and simple to learn since it is really just a language of Boolean operators connecting queries that are implemented by various registered containers (see previous post), primarily Mitopia’s built-in MitoQuest™ container.
In the previous post, we introduced the overall architecture of Mitopia’s MitoPlex™ server federation. In this post I want to look at the architecture of MitoPlex™ queries in a little more detail. Mitoplex™ and MitoQuest™ together provide a SQL alternative query infrastructure with vastly greater expressive power. Listing 1 below presents the complete syntax for the MitoPlex™ query language. As you can see, the language is very small and simple to learn since it is really just a language of Boolean operators connecting queries that are implemented by various registered containers (see previous post), primarily Mitopia’s built-in MitoQuest™ container.
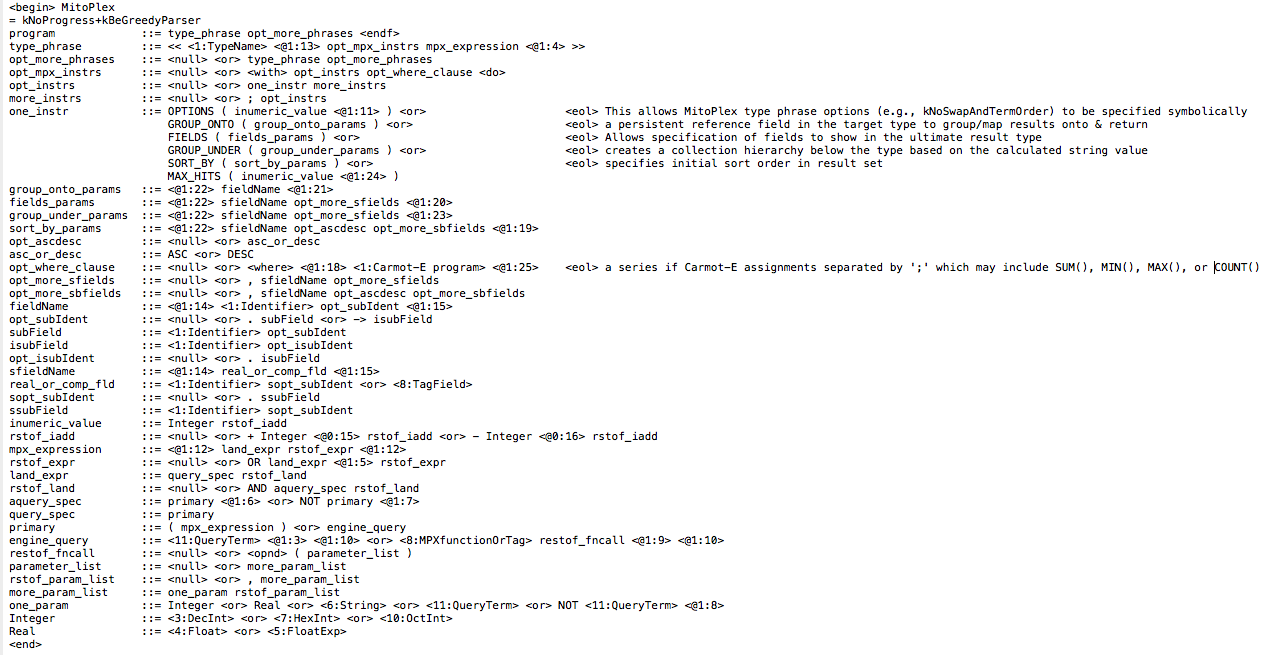 |
| Listing 1 – BNF specification for MitoPlex™ query language (click to enlarge) |
MitoPlex™ queries fall into two main groups, those that include a ‘with’ clause (and optional ‘where’ sub-clause), and the simpler forms that do not. In this post we will ignore the ‘with’ clause completely and discuss only the simpler query form. We will return to the ‘with’ and ‘where’ logic in a later post. To illustrate the simple query process, let us assume that the user issued a query for all countries where the “issues.other” field contained “drugs” and the country population was over 1 million (a silly query but this is only an example). If we were to look at the actual text form of the query generated by this sequence, it would be as follows:
<<Country[[MQ:$FieldContainsSequence(issues.other,”drugs”,0x0)]] AND [[MQ:$FieldIsGreaterThan(people.population,1000000,0×0)]] >>
We can see from the MitoPlex™ BNF syntax in Listing 1 that the “<<Country…>>” block is a type phrase, and Mitoplex™ supports the ability to specify and combine multiple type phrases, thus the user could issue a query against Country and combine the results with another query against People. In this case however only one type is involved. The blocks within each type phrase of the form “[[MQ:…]]” are the query terms, and their content is specific to each container of the federation, but always starts with a container identifier, in this case “MQ” is the identifier for the MitoQuest™ container. This standard format allows MitoPlex™ to route query fragments to the appropriate container. In the example above, both terms are using the MitoQuest™ container. From this it should be obvious that the MitoPlex™ layer provides a unified but easily extensible federation framework. To add a new container (a fingerprint recognizer say), all that is required is to define a new container and register the appropriate syntax and plug-ins (see Table 1 in previous post). Contrast this to the inflexible and arcane interfaces provided by the existing database models and their inability to natively handle federations at all.
Note that there are at least three distinct languages and associated parsers involved is any given MitoPlex™ query. The MitoPlex™ parser itself processes the outermost language. Each registered container plugin handles syntax and parsing of its own unique query terms, and the Carmot-E language and parser (see other posts) is responsible for dealing the content of the ‘with’ clause. In actuality there may be many containers, each with their own parsers, and also in different contexts (e.g., client side, main server, drone) different parsers interpret and operate on the query in different ways. There are in reality many distinct parsers involved in the process and they are frequently nested within each other to many levels. This is definitely not a simple one-tier language like SQL, it is a true SQL alternative/successor.
The MitoPlex™ layer in the client takes the query terms specified and routes them to the appropriate server(s) across the network according to the Carmot ontology and the corresponding server topology. Note that for any given type say Country, there is only one prime server to which the query must be routed (although it may be clustered internally). This is in marked contrast to a conventional server federation where each member of the federation is probably running on different machines and in most cases different computing platforms. This is because as we have said, MitoPlex™ federations are tightly integrated and every machine on the network has the capability to implement all client and server functionality built-in. Thus talking to federation containers in a MitoPlex™ architecture is more akin to subroutine calls within a single thread context of the server (i.e., no network communications involved). The advantages of this approach are hard to overstate, as we will see below.
Query Optimization and Pipelining
One of the plug-in functions that each container must register is a query cost estimator function (kQueryCostEstimaterFunc) which returns an estimate of how expensive the query term will be to evaluate if it appears as the first term in a sequence or as a later term. Because of this, MitoPlex™ is able to perform extremely sophisticated and highly aggressive query optimizations by re-arranging query terms as necessary, and by converting full-blown querying operations into highly optimized pruning chains, even combining pruning chains, unraveling nested expressions, and sequencing queries between different servers. This is part of the reason for the “<8:MPXfunction>” syntax evident in the MitoPlex™ BNF given above. If we look at the simple query above after it has been through the MitoPlex™ query optimization chain in the server, and before it is actually issued, we see that it has been converted to the following form, which is also valid MitoPlex™ syntax:
<< Country $AND( [[MQ:$FieldContainsSequence(issues.other,”drugs”,0x0)]], [[MQ:$FieldIsGreaterThan(people.population,1000000,0×0)]] )>>
Thus two distinct MitoQuest™ queries have been converted into a form where the specification of each is one of a series of parameters to the MitoPlex™ pruning pipeline function $AND. During actual execution of this single query as a pruning pipeline, what happens is that MitoPlex™ causes the first query in the list to execute normally, but as this query finds an item in the database and attempts to add it to the accumulating list of matching hits, it calls back into MitoPlex™ to do this, and this then transparently executes each of the other queries in the list against just the item detected by the first query in order to determine if that item matches all terms in the $AND. If any of the trailing queries fails, the item is not added to the list, otherwise it is. MitoPlex™ has many different internal pruning functions like this, including of course the ability to handle logical negation of any term in the list. Because MitoPlex™ arranges that the cheapest query execute first, and that all other queries need only examine the specific data item (which has already passed all preceding pruning criteria), the processing of highly complex queries across different federation members is incredibly fast compared with any other architecture, and involves no creation of any intermediate hit lists that must be transmitted around the system (see discussion in previous post). Only exactly the hits that match all the various criteria are ever passed anywhere. The result is orders of magnitude improvement in federated database operation, and, given the inherent ability to distribute servers, the ability to scale to essentially unlimited levels. This patented behavior of the Mitopia® architecture cannot be matched or replicated by any other system, and is an absolutely critical requirement for scaling to truly massive data volumes.
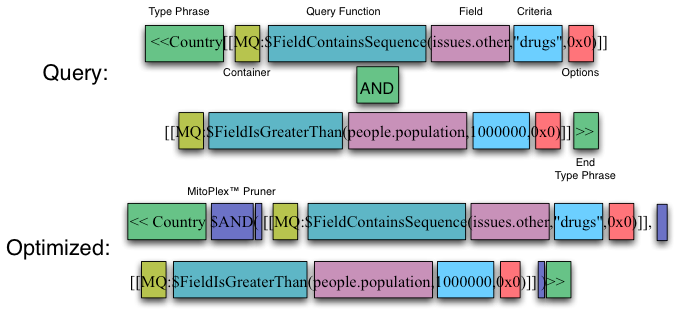 |
| Figure 1 – MitoPlex™ query re-writing during optimization pass |
The Figure 1 illustration above shows how the various portions of a MitoPlex™ query contain multiple embedded MitoQuest™ terms that are mapped through the query optimization process. Figure 2 below illustrates the actual process of executing this query within the server. As can be seen from Figure 2, the process of executing a compound query is implemented by nesting multiple parsers using the MitoPlex™ pruning function $AND (invoked by QX_AddIfNotPresent) as the glue. The $AND MitoPlex™ pruner function invokes any additional parsers associated with query terms other than the first during the process of attempting to add hits from the first embedded container parser (in both cases in the example the container is MitoQuest™).
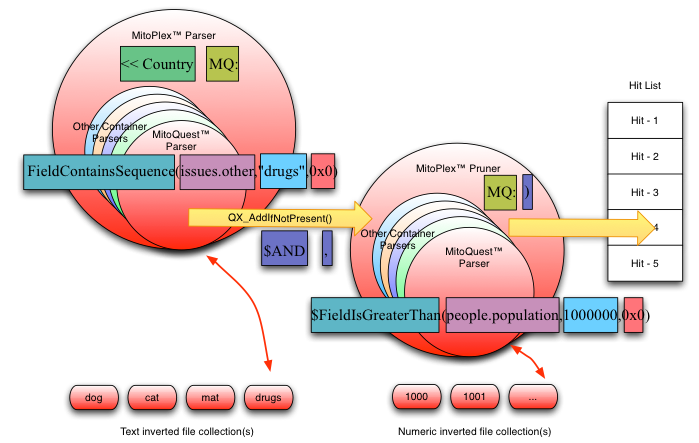 |
| Figure 2 – Executing a pipelined query within the MitoPlex™ federation |
The actual implementation of the container-specific queries associated with the various terms in the compound MitoPlex™ query statement is performed by code invoked by the embedded query parser. In the case of the MitoQuest™ container (which implements 99% of all queries), this is implemented using the inverted index files associated with the data collections of the server as illustrated in Figure 2 above.
The end result of this change from a horizontal to a distributed vertical federation architecture is a massive improvement over existing database technologies (orders of magnitude) in terms of complex query performance. Most importantly, the improvement continues to scale linearly with the number of machines in the server cluster. This in turn drives down the costs of the massive server farms necessary to address a specific large application (or performance level) both in terms of raw hardware costs as well as on-going airconditioning and electrical costs. We will talk in more detail about this in future posts.