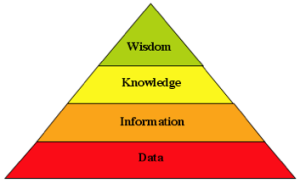
 Given the fundamental definitions of the levels in the knowledge pyramid presented in the previous post, it is now possible to examine various well known aspects of our digital world in terms of the ‘level’ of the model that underlies them, and the nature of the ‘problem’ they seek to solve. It should be obvious that by examining the level differences between the digital substrate and the ‘problem’ the system is intended to solve, we have a fundamental measure of the complexity of the undertaking. Similarly for projects that are as yet incomplete, we have a measure of the likelihood of success, the wider the span from model to problem, the lower the chance of success.
Given the fundamental definitions of the levels in the knowledge pyramid presented in the previous post, it is now possible to examine various well known aspects of our digital world in terms of the ‘level’ of the model that underlies them, and the nature of the ‘problem’ they seek to solve. It should be obvious that by examining the level differences between the digital substrate and the ‘problem’ the system is intended to solve, we have a fundamental measure of the complexity of the undertaking. Similarly for projects that are as yet incomplete, we have a measure of the likelihood of success, the wider the span from model to problem, the lower the chance of success.
This post is part 2 of a sequence. To get to the start click here.
The World Wide Web
 The world wide web is our most pervasive and largest system for organizing information. At its core, the web operates on the ‘document’ model, that is it is a system for publishing unstructured documents (web pages, PDFs, photos, videos, etc.). In other words the web is a Data Level system. Some sites on the web have relational databases backing them and offer more powerful search methods than the ubiquitous web ‘keyword’ search. These few sites can be said to operate at the Information Level, yet their advanced features can only be accessed by navigating to the site (assuming you know it exists), not from a more generalized web interface. Thus the web at its core is a Data Level (DL) system. A few forays into more advanced integrated interfaces to the web exist (e.g., Wolfram Alpha), however, these are still preliminary and as yet access only a very limited portion of the web, primarily certain sites that are Information Level (IL) based. The standard search engines that scour the web and allow us to perform keyword searches across all of it (e.g., Google) return lists of documents/pages, usually millions of them, that contain the word(s) we typed.
The world wide web is our most pervasive and largest system for organizing information. At its core, the web operates on the ‘document’ model, that is it is a system for publishing unstructured documents (web pages, PDFs, photos, videos, etc.). In other words the web is a Data Level system. Some sites on the web have relational databases backing them and offer more powerful search methods than the ubiquitous web ‘keyword’ search. These few sites can be said to operate at the Information Level, yet their advanced features can only be accessed by navigating to the site (assuming you know it exists), not from a more generalized web interface. Thus the web at its core is a Data Level (DL) system. A few forays into more advanced integrated interfaces to the web exist (e.g., Wolfram Alpha), however, these are still preliminary and as yet access only a very limited portion of the web, primarily certain sites that are Information Level (IL) based. The standard search engines that scour the web and allow us to perform keyword searches across all of it (e.g., Google) return lists of documents/pages, usually millions of them, that contain the word(s) we typed.
The web itself is touted by most as the way to find the answer to all problems, yet the rashness of this statement should be obvious, given that most questions that real people are interested in the answer to are at either the Knowledge Level (KL) or Wisdom Level (WL), not at the DL or IL level that more closely matches the underlying model. When humans go to the web for an answer they generally have a KL or WL question in their head like “What does this rash on my neck mean?”, “Should I sell my stock?”, “Why is the traffic so bad today?”, or “Is it safe to vacation in country X?”.
None of these questions can be answered by a substrate that operates at the DL. What happens is that the person obtains a list of millions of documents that contain keywords like “neck”, “rash”, “stock”, “traffic”, and “X” and the user is forced to refine keywords and then embark on a lengthy process of reading each of the documents until that person forms an opinion based on what has been read as to the likely answer to the original question. More likely, since most web pages are placed there by somebody with an agenda to divert the readers attention elsewhere, the user comes to their senses hours later, and realizes that they have forgotten what their original question was.
The web user is thus wholly responsible for bridging the divide from the DL to IL, KL, and even WL, while maintaining focus, validating reliability of sources, and integrating divergent information. No surprise therefore that implementing the web, other than massive infrastructure investment, is a relatively simple matter. The web really doesn’t do much; it is just a vast digital repository with a “Use at your own risk” sign above the door. It is effective for answering DL and IL questions, but cannot answer more complex questions. We have grown so used to, and have silently accepted, the fact that it is impossible ask computers the actual question in our heads. Instead we must play the ‘keyword guessing game’, and we barely even notice any more what a ridiculous and ineffective interface the web is for answering complex questions.
We have become the slaves to the web’s failings, we do all the hard work that the web claims to support, and then forget that it was ourselves, and not the web, that formed any unified picture that may have resulted. This is the nature of the knowledge pyramid, without a digital substrate based on the required knowledge level, we ourselves, as the only known ‘system’ capable of simultaneous operation on all four levels, particularly KL and WL, must do the bulk of the work.
Relational Databases

Relational databases (
RDBMS) underly virtually all information systems other than the web itself. These systems tend to be relatively small and to focus on answering IL questions. Examples of such systems abound viz: banking, HR databases, booking and ticketing, accounting and economics, parts and inventory, item tracking, etc. The relational database model is an IL component, that is it makes data available for search by content in complex ways by organizing it into tables which can be queried through the SQL query language and subsequently displayed in tabular or graphical form. RDBMS systems are organizationally a significant step up in capability from the document model of the web.
 |
| The Great Ziggurat of Ur |
Fundamental to successful deployment of RDBMS systems is that the deploying organization have a high level of control and ownership over the data contained in the tables, and over the taxonomy used to organize it within the database in order to facilitate search in the limited ‘query’ space supported. This level of control is necessary because there is considerable complexity and cost in implementing the ‘business logic’ code that ties the relational table structure to the specific displays and outputs required of the system. As long as these requirement remain stable, such systems can be extremely effective.
Identifying niches within which this level of control and stability can be maintained has allowed RDBMS systems to become the underpinnings of virtually every business enterprise and most government organizations. Unfortunately however, as each system is built and embodies ‘business logic’ within its code, by definition it tends to become isolated from other such systems forming what is known as a silo or stovepipe within the larger organizational data ecosystem. This eventuality is perhaps fundamental to the relational model, and may well be unavoidable.
RDBMS systems are often [mis]applied to problems that are KL or WL, and in these cases their shortcomings are apparent. Think for example of systems designed to help trade stocks. Here the user is provided with a variety of graphs and charts based on various simple data feeds like stock price history. The user has a WL question in mind, that is “Should I buy or sell a given stock?”, but since such questions are far beyond an IL substrate, the system responds by presenting a variety of charts and allowing the user to answer their own question by forming an opinion based on the displayed curves (a KL/WL process). Answering the true question of course involves vast amounts of data from diverse sources on the company involved, its products, its business model, its competitors, the economic environment, news reports, other technologies that might impact company profits, etc. etc. Since these data sources cannot be ‘controlled’ to a level necessary to plop them into pre-ordained tables, they must be ignored in favor of tracking the downstream consequences as reflected in the recent stock price history (a simple number that fits in a relational ‘cell’). Once again these systems deceive us into doing all the work ourselves, they fail utterly to track back to the ultimate causes behind the curves being presented and establish any causal relationship (KL), never mind visualize any causal patterns (WL).
Clearly for today’s IL technologies, the necessary level of control over the content and usage are lacking in any system that attempts to encompass a broad domain that includes information from a variety of sources. For this reason, RDBMS systems are ill suited to these larger more diverse applications and are seldom applied there. In these broader domains we tend to revert back to a simpler ‘document’ (or DL) model in order to manage diversity and change at the cost of functionality (i.e., they rely on keywords, and the human must do the work).
There are those that claim to provide knowledge level capabilities based on the relational IL substrate. This is clearly a falsehood since the thing that relational databases are perhaps the worst at is the representation of arbitrary and potentially changing relationships between items or ‘entities’ represented in the data. RDBMS systems excel on questions involving the content of various tables, they flounder on questions involving relationships between ‘entities’ that span multiple tables (i.e., just exactly the kinds of things that make up a KL substrate).
Systems that make the KL claim while using RDBMS substrates are forced to drastically limit the allowed connection type set. As an example of a purported KL system operating on RDBMS underpinnings, take FaceBook or any other social network. Social networks address a KL problem domain, however each must limit the scope of connections in order not to overwhelm the incompatible relational underpinnings. For FaceBook we see the set limited to such things as ‘like’, ‘friend’ and similar. For other social networks, the set may change (perhaps to professional links, music tastes, etc.), but the limitation remains. Social networks as embodied in today’s offerings can really only claim to be half way from the IL to the KL, they give but a hint of KL power, while limiting its applicability drastically due to the shortcomings of the underlying relational model.
The Semantic Web

As an attempt to help close the gap between the data-level web and the knowledge or wisdom levels questions that people commonly seek to answer, a new movement known as “The Semantic Web” was started some time around 2001. This idea was predicated on the fact that document model of the web was a fait accompli, therefore in order to make the web suitable for more complex questions the only solution was to graft semantic ontologies on top of the web content. Web content would be annotated with metadata (through a combination of
RDF,
OWL,
XML) with the anticipated result that this unified tagging would allow people to find and exchange relevant data more effectively.
Unfortunately, the semantic web has thus far failed to deliver substantially on its promises. It remains isolated to a small pocket of the web, specifically companies that are interested in semantic web technology for internal use. Much of this can be attributed to the fact that the approach requires two distinct sets of matching data to be created for every page, one is the HTML content, the other the semantic web payload. Few web authors have any understanding or any particular interest in all the extra work and maintenance this would involve. Other issues involve intentional semantic deception on the part of web authors, and issues of security and censorship.
A major problem is clearly that semantic ontologies pertain to the understanding of language and the meaning of words, they have nothing whatsoever to do with how information is actually represented. This dichotomy between how something’s meaning is represented and how the thing itself is manipulated means that the grafting process really does not take because much of the meaning is mediated by context, formatting, and tags and links held in forms not susceptible to semantic analysis. The ontology is disjoint from the data it is attempting to describe.
 |
| The temple of Kukulkan at Chichen Itza |
Additionally, to understand words one must pick a language, specifically English, and yet most of what happens or is written in the world does not occur in English. Finally the vast span between the underlying data model (data level) and the semantic tags (knowledge level) given that the tag is constrained to referencing words in a sentence, mean that any truly meaningful and navigable chains of connections (i.e., knowledge) cannot truly be created or leveraged efficiently. Text is not the medium through which complex chains should be represented; text processing is too slow and imprecise for this to be practical.
Well meaning though the semantic web may be, at its heart it may be an impractical dream. To represent and manipulate knowledge, one must physically represent as knowledge. It is not possible to graft and manage knowledge firmly on a substrate comprising an ever changing sea of ambiguous and context sensitive words in just one evolving human language. The mind boggling (and ever growing) scale even of very focused OWL ontologies (the SNOMED CT medical ontology alone contains 370,000 class names) are a clue to the ultimate futility of this approach.
Intelligence Infrastructures

There is a long history of attempts within the US government and elsewhere to build an overarching architecture to handle all intelligence within a single unifying framework. One of the largest such projects within the last decade or so was the
Trailblazer project at the
NSA. This project set out in 2002 (contracted to
SAIC) to analyze and understand data on communications networks like the internet. The project failed spectacularly and was shut down completely in 2006 at an eventual cost measured in the billions. Trailblazer was built on relational underpinnings but attempted to apply ontologies to the analysis of data. The rigid and inflexible nature of RDBMS technology and the lack of a formalism to transform and move packets up the knowledge hierarchy, combined with attempts to graft esoteric and philosophical ontologies onto a substrate ill suited to the task, were in my opinion largely responsible for the failures. As usual however the failings were blamed on poor management rather than a technical failure to look at the problem from first principles.
The Trailblazer project was replaced by another more piecemeal attempt called Turbulence that included cyber attack capabilities. For a long time Turbulence did not appear in any budget. This project too encountered budget and schedule problems. With annual costs of around half a billion, Turbulence has apparently encountered technical problems and suffers from a vague and ever changing game plan. The model underlying the Turbulence project today is unclear. Following the failings of Trailblazer and the relational approach, there was a general move within the NSA towards the new NoSQL big-data approach based on Hadoop and Map-Reduce, but it is unlikely this approach went too far since the big-data technologies actually represent a considerable dumbing down from the relational (IL) model. To seek understanding based on such a flimsy (if massively scaleable) substrate is clearly folly and would place Turbulence in much the same position as the world wide web, that is attempting KL/WL problems on top of a DL infrastructure.
 |
| The avenue of the dead in Teotihuacan |
The FBI’s Virtual Case File (VCF) project was another spectacular failure in this realm. Launched in 2000 and also awarded to SAIC, the project was intended to modernize the bureau’s outdated IT infrastructure. While the hardware and network aspects of the project were generally successful, the software component quickly ran into trouble trying to replace the bureau’s home grown Rube Goldberg “Automated Case Support (ACS)” system. The project was finally scrapped in 2005 at a cost of hundreds of millions. By that time code size had reached around 700,000 lines (smaller than Mitopia!). Once again problems with management were officially blamed for the failure. In truth of course, the project failed technically to consider the need to re-examine the digital underpinnings to ensure that they were capable of supporting the complexity and scale required.
The Railhead project was intended to replace the aging Terrorist Identifies DataMart Environment (TIDE) system originally built by Lockheed Martin. TIDE is the US Government’s central database of known or suspected international terrorists and is updated and accessed by many agencies including the CIA, DIA, FBI, and NSA. The database contains around half a million names and is used to generate other lists like the TSA ‘No Fly List’. The Railhead replacement project began in 2006 and by 2008 had an annual cost of around half a billion with around 850 contractors involved in the project. At that time the system still remained incapable of even simple Boolean queries. The project was reduced to a skeleton crew in 2008 and has since gone dark. The original TIDE database comprised 463 separate tables, 295 of which were undocumented. The transition from this fragile relational base to another relational repository was perhaps overwhelming and left the SQL query engine blind and impotent when all was said and done.
 |
| The pyramids of Giza |
It would appear that our scenery is littered with ziggurats and truncated or malformed pyramids. We have yet to build our digital equivalent of the plains of Giza. Indeed we have yet to build more than the base for our first complete digital knowledge pyramid. The bases we have (e.g., the relational model) were built by giants, but now their flat tops are littered with ramshackle dwellings and wobbly towers that strain for the sky yet always fall short. The giants all perished long ago, and those that follow are too busy to construct new bases from first principles. Instead they churn out their monuments at great cost on the foundations of old, and are then surprised that they are toppled by the winds of change before they can truly scrape the skies.
The Aztecs and Mayans found many useful purposes for pyramids with the top chopped off, foremost among those uses was human sacrifice. Our digital landscape too is littered with such structures…

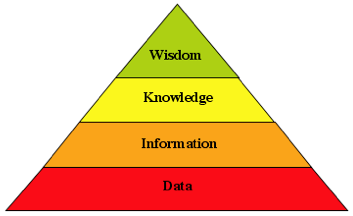 Given the fundamental definitions of the levels in the knowledge pyramid presented in the previous post, it is now possible to examine various well known aspects of our digital world in terms of the ‘level’ of the model that underlies them, and the nature of the ‘problem’ they seek to solve. It should be obvious that by examining the level differences between the digital substrate and the ‘problem’ the system is intended to solve, we have a fundamental measure of the complexity of the undertaking. Similarly for projects that are as yet incomplete, we have a measure of the likelihood of success, the wider the span from model to problem, the lower the chance of success.
Given the fundamental definitions of the levels in the knowledge pyramid presented in the previous post, it is now possible to examine various well known aspects of our digital world in terms of the ‘level’ of the model that underlies them, and the nature of the ‘problem’ they seek to solve. It should be obvious that by examining the level differences between the digital substrate and the ‘problem’ the system is intended to solve, we have a fundamental measure of the complexity of the undertaking. Similarly for projects that are as yet incomplete, we have a measure of the likelihood of success, the wider the span from model to problem, the lower the chance of success.
