 In the previous post we introduced the MitoQuest™ plug-in which is the principal member of the MitoPlex™ federated server architecture. In this post we will look in more detail at the MitoQuest™ query language syntax and the querying capabilities that MitoQuest™ provides, including of course cross language search. Like all MitoPlex™ plug-ins, these MitoQuest™ queries themselves operate within the context of an executing MitoPlex™ query, and actually represent the ‘terms’ in a larger more complex MitoPlex™ query. Listing 1 below presents the BNF syntax for the MitoQuest™ Query language:
In the previous post we introduced the MitoQuest™ plug-in which is the principal member of the MitoPlex™ federated server architecture. In this post we will look in more detail at the MitoQuest™ query language syntax and the querying capabilities that MitoQuest™ provides, including of course cross language search. Like all MitoPlex™ plug-ins, these MitoQuest™ queries themselves operate within the context of an executing MitoPlex™ query, and actually represent the ‘terms’ in a larger more complex MitoPlex™ query. Listing 1 below presents the BNF syntax for the MitoQuest™ Query language:
 |
| Listing 1 – BNF for the MitoQuest™ Query Language (click to enlarge) |
The MitoQuest™ query language looks a bit more complex than that for MitoPlex™ however, you will note from the BNF that most of the text-based query functions are replicated in the BNF for the various supported text scopes, namely ‘sentence’, ‘paragraph’, ‘field’, or ‘record’. If this replication were not shown, the language would actually be quite small. The query types fall into six main groups:
- Text-based queries like “$[Scope]ContainsSequence”, “ $[Scope]ContainsAnyOf” etc.
- Phrase-based text queries like “$[Scope]ContainsAllPhrases”.
- Reference-based queries like “$FieldContainsAnyReference”, “$FieldIsInDomain”
- Numeric queries like “$FieldIsGreaterThan” and “$FieldIsBetween”.
- Emptiness queries like “$FieldIsEmpty”.
- Connection-based queries like “$RecordConnectsTo”.
Text-based Queries
Text-based queries can be applied to any Carmot ontology field that is either an array of ‘char’ or is a memory or relative reference to ‘char’. In addition, persistent reference fields contain the name of the item referenced, and so they too can be queried using text-based queries. Text-based query names are preceded by the scope for which the query applies. When indexing text within fields, MitoQuest™ keeps track of sentence and paragraph boundaries within the instance entries in the inverted files. This allows the queries to support ‘sentence’ and ‘paragraph’ scope in addition to the standard ‘field’ scope. For example the query $SentenceContainsAllOf(…) implies that all of the words specified must be found in the same sentence within the field text. Similarly for the ‘paragraph’ scope. The ability to search for words appearing in the same sentence of the ‘paragraph’ can often be used to isolate relevant sentences much more accurately than the ‘sequence’ queries because it is not impacted by word ordering in the same way that sequence queries are. It is very common for word order to be transposed within sentences that are essentially identical and this is particularly true for sentences that have been root mapped from another language and for which cross language search is required. The sentence and paragraph scopes can overcome these word ordering issues.
As can be seen from the BNF (see restof_textFunc), the first parameter to all text-based query functions is the field name involved which may be a hierarchical field path (e.g., geography.landUse.note). In the case of a record scope function, you should pass ‘name’ for the field path since it is not used by the actual query but must be present. The second parameter to text-based queries is a string containing a comma-separated series of words (may of course just be a single word). This specifies the set or sequence of words involved. The final parameter is the query options word which is a numeric bit mask obtained by combining/adding zero or more the following options:
kExactMatch 0x00000000 // Search in the “.INV” file
kStemmedNativeMatch 0x00000001 // Search in the “.INF” file
kStemmedEnglishMatch 0x00000002 // Search in the “.INS” file
kConceptMatch 0x00000004 // Search in the “.INS” file using thesaurus
kUnsignedMatch 0x00000008 // Numeric comparisons – uns./absolute compare
kLanguageCodeMask 0x0000FF00 // Reserved to pass desired language code
kLanguageCodeShift 8 // Shifts to get language code to LSB
This options mask, as for all MitoQuest options masks, can be specified symbolically rather than numerically for example:
<<Country [[MQ:$FieldIsSequence(people.religions->religion, “Muslim”,kExactMatch+kEnglish)]] AND [[MQ:$FieldIsGreaterThan(people.religions->percent,20,0)]]>>
In the query above, the text query options for $FieldIsSequence() are specified symbolically as “kExactMatch+kEnglish”. The symbolic constant for each valid language name (e.g., kEnglish) can be found in the Mitopia header files. Note also in this query that the field paths involved are within an ‘@@’ sub-collection (hence the ‘->’ in the path specification).
The first three options above basically select which inverted index file is used to execute the query, and as described previously, this determines the degree of stemming (and language mapping for cross language search) applied to the text during indexing (and search). The kConceptMatch option is designed to allow thesaurus-based querying. The kUnsignedMatch option is applied to numeric (not text) queries where its effect is to make all integer numeric comparisons as if the values were unsigned. For real number fields, the effect of this option is to compare the absolute value as in the C library function abs(). The kLanguageCodeMask and kLanguageCodeShift constants allow you to specify the language that the query text is in. You may find the definitions for the various language code constants in the Mitopia® header files. In particular the value zero implies kCurrentLanguage that is whatever language the application language menu has currently selected (defaults to kEnglish). The value kEnglish (1) specifies the English language. The same stemming behavior specified in the options word is applied to the query words as the query is issued so that the query terms and the selected inverted index file are using the same stemmed lexicon.
The “$[Scope]ContainsAnyOf” query will match all records where the specified scope contains any of the words in the comma-separated list in any order. Note that as a result of query term stemming, it is possible that one word in the comma-separated list could turn into more than one in the actual query. For example a stemmed English query on the words “unending,subzero,possums” would be translated into “not end,below zero, possum”. The terms containing multiple words are actually implemented within the query engine as sequence queries, that is, both words must be found adjacent to each other for a match to happen. The issuer of the query can generally ignore this fact. For more details on stemming see other posts. The “$[Scope]ContainsAllOf” query will match all records where the specified scope contains all of the words specified in any order.
The “$[Scope]ContainsSequence” query will match all records where the words in the word list appear in a contiguous sequence. The “$[Scope]StartsWithSequence” and “$[Scope]EndsWithSequence” queries are essentially identical but allow you to require that the specified scope start or end with the sequence.
The “$[Scope]IsSequence” query requires that the specified scope both start and end with the sequence given.
Phrase-based Text Queries
Phrase-based text queries are a powerful and elaborate means of issuing text-based searches for the name of all members of the domain of interest, for example you can issue a single query for any records that mention the name of any know item of military equipment. This system works by effectively embedding one ‘query’ within another so that the first query returns an arbitrary set of names from persistent storage and the second query then issues a ‘sequence’ query on the original search domain for occurrences of any phrase in the list returned by the first query. In actuality, a phrase list may simply be a list of key phrases that has been compiled manually; it need not be a dynamic query. The definition for the ‘SystemRelated’ derived Carmot type ‘PhraseList’ used to implement phrase queries can be found in the base ontology as shown in Listing 2 below:
 |
| Listing 2 – Fields of the type PhraseList |
The phrase-based queries “$[Scope]ContainsAnyPhrase” and “$[Scope]ContainsAllPhrases”, take the same first parameter as text queries, that is a file name/path. The subsequent parameter(s) for phrase list queries can be seen from the MitoQuest™ BNF to be comprised of a list of one or more integers (see restof_phraseFunc) each of which specifies the unique ID of a persistent record of type ‘PhraseList’. This means that to create a phrase-list query, you must first create at least one phrase list record.
Note that the phrase list query can reference more than one phrase list. Indeed this is the basis for the existence of the two phrase list forms. If multiple phrase lists are referenced by the query, the “$[Scope]ContainsAnyPhrase” query will match all records where the specified scope contains any phrase occurring within any phrase list in the list. For the “$[Scope]ContainsAllPhrases” query, each matching record must contain one or more phrases from each phrase in the query list. Within the ‘PhraseList’ record, you have the option of entering the list either as a persistent reference to any other supported content query (e.g., “find all persons who are on a given watch list”) together with a type name for which the query is to be issued (this specifies the type phrase in the MitoPlex™ query). Alternately you may simply type in a comma-separated list of single or multiword phrases into the ‘@phraseList’ field. Phrase queries are always issued against the .INV inverted index, that is they are exact match only.
The execution of phrase list queries within MitoQuest™, like all other MitoQuest™ query forms, has been very highly optimized, which means that by using this technique one can rapidly execute the equivalent of hundreds or thousands of separate ‘key word’ style queries in one step. By selecting the queries that generate the phrase lists, and combining these with manually entered phrase lists, one can imagine using this query form to trivially address some very complicated problems. Phrase lists and content queries are saved in persistent storage on a per user basis, and thus once constructed they can be re-issued at any time simply by double-clicking the query. These saved queries, like all queries, can of course be combined with other queries and can be shared with other users. Phrase-based text queries can be applied to the same ontology field types as can text-based queries.
Phrase lists can be referenced from a query (see ‘phrase_term’ in the syntax) either by specifying the unique ID of the persistent phrase list (as discussed above) or alternatively by specifying a string parameter in the query. If the string starts with “<<“, it is taken to be a nested query and is executed in order to obtain the names (and aliases) of all the hits which become the phrase list to be used. Alternatively the string may contain the name (rather than UID) of the persistent phrase list to be used. This ability to construct phrase lists on the fly by embedding nested queries is particularly powerful. See the discussion below for more on nested queries.
Reference-based Queries
The reference-based queries “$FieldContainsAnyReference” and “$FieldContainsAllReferences” can only be applied to persistent reference or collection reference fields of an ontological type. Clearly the ‘ContainsAll’ variant only applies to a collection reference field since a persistent reference field only references a single item. As for other query forms, the first parameter is the field name/path involved. Remaining parameters are one or more integer values, each of which corresponds to the unique ID of an external reference to be checked. The queries are actually performed by use of the .INN numeric inverted index file. The $FieldIsInDomain() query is the basic mechanism whereby nested queries are implemented and is fully supported in the Query Builder UI. See the discussion on nested queries below.
Numeric Queries
Numeric queries can be applied to any ontological fields of either integer or real types. Date and time values are encoded and double precision real values within Mitopia® and are thus descendants of the type real and subject to numeric queries. The available query functions are $FieldIsNotEqual, $FieldIsEqual, $FieldIsLessThan, $FieldIsLessThanOrEqual, $FieldIsGreaterThanOrEqual, $FieldIsGreaterThan, $FieldIsBetween, $FieldIsNotBetween, and $FieldIsInSet(). Like other query types, the first parameter of all numeric queries is the field name/path. The last parameter of all numeric queries (other than $FieldIsInSet) is an options mask for which the only defined option at this time is kUnsignedMatch as described above in the options discussion for text queries. The second parameter to all numeric queries specifies the numeric value to compare the field to (or for range queries, the lower end of the range). For the ‘Between’ and ‘Not Between’ forms, a second numeric value is also passed to specify the top of the range. As discussed earlier all numeric comparisons are actually performed using the .INN inverted index files which represents all numbers as 64-bit hexadecimal strings for indexing purposes and this ensures that numeric queries always operate as fast as text-based queries since they rarely have to examine the actual record content. You should avoid issuing the $FieldIsEqual query for floating point numbers since precision limits may make exact equality hard to establish.
The $FieldIsInSet() query simply takes a list of numeric values representing the set of values to compare to, in effect it is like the ‘OR’ of a series of $FieldIsEqual(). Finally note that numeric fields (and in this context we include persistent reference and collection reference fields) can be queried using the $FieldIsInDomain() function. This opens up the possibility of creating a large set of numeric values to compare to, including having that set constructed on the fly as the result of a nested query. See the discussion on nested queries for more details.
Date values are represented within Mitopia® as real numbers where the whole number part is the Serial Day Number (SDN), and the fractional part represents the time of day. The SDN is a serial numbering of days where SDN 1 is November 25, 4714 BC in the Gregorian calendar and SDN 2447893 is January 1, 1990. This system of day numbering is sometimes referred to as Julian days, but to avoid confusion with the Julian calendar, we use the term Serial Day Numbers here. The term Julian days is also commonly used to mean the number of days since the beginning of the current year. Since date-related numeric comparisons have a number of common forms, MitoQuest™ provides the terminal symbol form <9:DateSpec> (see the .LXS specification for MitoQuest™) to allow dates and date ranges to be specified symbolically using a more human-readable syntax. The format of a token is:
{DATE:date,d,unit,calendar}
where:
- date – is either a floating point number (see OC_ConvertDateToDateDouble), NOW – which means the date/time right now, or a standard date specification of the form: “yyyy/mm/dd [ hh:mm[:ss] [AM/PM]]“
- d -is a positive or negative integer relative to the ‘date‘ value (negative numbers are before ‘date‘; positive are after)
- unit – is the time unit for ‘d‘ which may be one of SECOND, MINUTE, HOUR, DAY, WEEK (of the year), MONTH or YEAR
- calendar – is a character constant giving the calendar to be used (e.g., G for Gregorian,I for Islamic, etc.). This calendar will impact the interpretation of WEEK, MONTH and YEAR units.
The specified date/time is truncated to the start of the unit given when dates are specified in this manner. For example:
- {DATE:NOW,0,DAY,G} — means “Today”
- {DATE:NOW,-1,DAY,G} — means “Yesterday”
- {DATE:NOW,-7,DAY,G} — means “Within the Previous 7 Days”
- {DATE:NOW,0,WEEK,G} — means “This Week” – note that weeks go from Monday…Sunday
- {DATE:NOW,-1,YEAR,I} — means “Last Year (in the Islamic Calendar)”
Thus a query for all the news stories where date filed is from the second year of this century to the beginning of the current year would look like:
$FieldIsBetween(dateFiled,{DATE:2000/01/01,1,YEAR,G},{DATE:NOW,0,YEAR,G},0)
Currently exposed calendar systems are as listed below. Approximately 20 other calendar systems are supported internally.
- kGregorianCAL ‘G’ // Gregorian Calendar
- kJulianCAL’J’ // Julian Calendar
- kIslamicAstroCAL’I’ // Islamic Astronomical Lunar Calendar
- kIslamicCivilCAL’S’ // Islamic Civil Lunar Calendar
- kHebrewCAL’Z’ // Hebrew Calendar
Emptiness Queries
The emptiness queries $FieldIsEmpty and $FieldIsNotEmpty can be applied to all fields of a type and utilize the ‘empty’ flags associated with each field held in the server collections. A field is ‘empty’ if it has never been assigned a value, otherwise it is not empty. Note that there is a logical difference between zero and an empty field since the latter implies an ‘unknown’ value whereas zero is a specific value. The query takes a single parameter which is the field name/path involved. The query “$FieldIsNotEmpty(id)” is frequently used internally by Mitopia® code as the ‘null’ query, that is match all records of a given type regardless of record contents. This is because by definition any record held in persistent storage must have an assigned unique ID and therefore this query is true for every persistent record regardless of type.
Note that it is often the case that empty fields are encountered during execution of another query form. In these cases, the ‘empty’ field is invariably taken to mean that the other query form fails to match.
Connection-based Queries
All the query forms described above are examples of the Carmot base ontology type ContentQuery (which is derived from Query). Content queries operate by examining the content of fields within records and thus are analogous to the kinds of queries one might be able to issue from a conventional database system. The type ConnectionQuery is another child of the type Query, but is focussed on directly and indirectly querying the connections between records of the same or different types. There is no analog to connection-based queries in conventional database systems since they are taxonomic and connection-based queries require an ontology. Connection-based queries are generally issued in Mitopia® through use of the link visualizer rather than a conventional Query Builder UI. Like content queries, connection queries can be saved in persistent storage and re-issued at any time, they can also be combined within MitoPlex™ queries with other query forms in order to create more complex compound queries. A full description of connection-based query generation and execution within MitoQuest™ is beyond the scope of this post. These are by far the most powerful kinds of queries supported by Mitopia® and their operation, like all other queries, is intimately tied to and driven by the Carmot ontology for the system.
Wild Cards in Text Queries
As mentioned above, Mitopia® provides explicit support for searching text in one of three levels of stemming, either ‘exact’ (i.e, no stemming, the text is indexed exactly as is), ‘native stemmed’ (i.e., the text is stemmed in its native language – see stemming posts for details), or ‘mapped stemmed’ (i.e., foreign language text is first ‘native stemmed’ and the root word mapped to English and finally stemmed in English). These three modes provide a powerful ability to accurately search text both in a single language or in a cross language search mode for all languages. It would seem that this approach covers all possibilities, however, there are still some situations where a more conventional ‘wild card’ approach to text matching is appropriate, and so this is also supported within Mitopia® but only on the raw ‘un-stemmed’ version of the text in whatever language it is witten. Wild card search makes no sense on stemmed text since the words may have been dramatically transformed by the stemming so as to make wild card queries meaningless.
Wild cards are supported in the $[Scope]ContainsAnyOf and $[Scope]ContainsAllOf queries, but not in sequence based queries. Wild card processing operates by parsing the ‘words’ specified for an “all of” or “any of” query looking for either ‘*’ (zero or more characters) or ‘#’ (a single character) symbols. If one (or more) is found, the query is dynamically converted in the server into the equivalent $[Scope]ContainsAnyPhrase or $[Scope]ContainsAllPhrases query form and a phrase recognizer is built containing all possible matching words. To allow rapid determination of all possible matching for arbitrary complex wild card specification, the MitoQuest™ server maintains a lexicon (see the file Lexicon.LEX in the server collections folder) of every raw word ever encountered in any field within the data held in the server. This lexicon holds the words in both forward and backward directions in order to make it easy to handle arbitrarily complex wild card specification.
The scripted query (see later discussion) below shows an example wild card query being used in combination with other query types to match the very specific form of a standard 5-digit US Air Force Speciality Code (AFSC) in order to determine the number of enlisted persons having medical skill sets at a given air force base:
<@1:5:$a = $Query(“<<MilitaryHRRecord[[MQ:$FieldIsEqual(baseCode,” + $bc + “,0)]]”+
” AND NOT [[MQ:$FieldIsSequence(postings->name,”Termination”,kEnglish+” +
” kExactMatch)]] AND [[MQ:$FieldContainsAnyOf(specialization->specialization,”+
“”4####”,kEnglish+kExactMatch)]]>>” ,”MilitaryHRRecord”,”name”,”$ec”)>
<@1:5:[[ $xx $staff$enlisted$skills$4_medical ]] = $ec>
Note that wild card processing is language-aware so that when a ‘#’ character for example is used to match a text character, that means “one character in the language concerned”. Non-English languages can use from 1 to 6 bytes to encode each character in UTF-8 and hence a single ‘#’ may indicate more than one UTF-8 byte depending on the size (in bytes) of any text character that follows in the query specification. This complexity is handled automatically by the wild-card matching algorithm so that query wild-card specifications need not consider the language involved.
Nested Queries
Though we have discussed connection-based queries above, there is another pervasive form of connection-based query that can be applied to any reference field (persistent or collection reference – #, or ##), this is the $FieldIsInDomain() query. This type of query is called a ‘nested query’. The nested query addresses the common problem in database situations where one realizes that the query involves not just conditions on the type of interest, but also on other types that are somehow related directly to each specific instance for the type of interest. The following are a few obvious examples of this kind of question:
- Find all Persons where the person’s child is employed by a given company
- Find all equipment of a given type where the manufacturer is based in a specified city or country
- Find all People where the person’s parent speaks Arabic
- Find all people who have been arrested for a given crime by an arresting officer based at a specific police station
In relational-database terms, the problem is that the answer requires multiple distinct queries to be performed and the the answers ‘JOINed’ using very specific knowledge of the database schema and the implicit links within it. As a result, anyone wishing to issue these fundamental and quite common queries must seek the help of a Database Administrator (DBA) or similar in order to get the answer. The result is that people generally can’t do these queries in an ad-hoc manner on relational systems, they must be canned and built into the client application code. However because Mitopia® is ontology based, it knows the reference fields that mediate these kinds of connections, and it also knows everything about the target type involved. By combining this with the numeric equivalent of the technology described earlier for ‘phrase queries’ (as provided by the $FieldIsInDomain form), it becomes possible for any user to easily ask these kinds of queries and to efficiently execute them. This capability represents a significant extension of Mitopia’s query capabilities over those of conventional databases. For example, the listing below shows a specific example of the second query type in the list above:
<<Aircraft[[MQ:$FieldContainsAllOf(category,”Unmanned aerial vehicle”,kStemmedNativeMatch+kEnglish)]] AND [[MQ:$FieldIsInDomain(company,”<<Organization[[MQ:$FieldContainsSequence(organization.country,”United States”,kStemmedNativeMatch+kEnglish)]] >>”)]] >>
Note that the nested query appearing in the $FieldIsDomain() call requires that the strings within be ‘escaped’ in a manner identical to that used by the C language, that is the ‘’ character must precede each double-quote character since the string itself is nested within and outer string that if part of the higher query that invokes it. This process of nesting can be repeated to and arbitrary number of levels. For example suppose we not only want to find all aircraft that are “unmanned aerial vehicles” and for which the manufacturing company is US based, but instead want to limit our query to just those companies where a key company officer’s surname was “Cowley” (perhaps we had bumped into the guy and knew he was high up in a company making aerial vehicles but had forgotten the company name). A few trivial additional level of nesting could answer this question as the example query below:
<<Aircraft[[MQ:$FieldContainsAllOf(category,”Unmanned aerial vehicle”,kStemmedNativeMatch+kEnglish)]] AND [[MQ:$FieldIsInDomain(company,”<<Organization[[MQ:$FieldIsInDomain(personnel.keyPersonnel,”<<Title[[MQ:$FieldIsInDomain(incumbent,\”<<Person[[MQ:$FieldContainsAllOf(name,\\\”Cowley\\\”,kStemmedNativeMatch+kEnglish)]] >>\”)]] >>”)]] >>”)]] >>
Note the additional levels of escape ‘\’ characters required to handle this nested query that now goes three levels deep in order to answer the question. It may appear that the query above is incredibly complex, however, in fact building this kind of complex query is simple and intuitive in Mitopia®. Moreover, execution time for this query is very fast. This nesting capability is a direct result of the fact that Mitopia® uses an ontology to describe data and its interconnections and also uses that ontology to generate and query persistent storage. Without such an approach, the query interface would not have sufficient information to simplify the relational ‘JOIN’ issue in this way for the user, and the query engine itself would have no means of executing such nested queries.
Archiving, Rollover, and Splitting of Collection Files
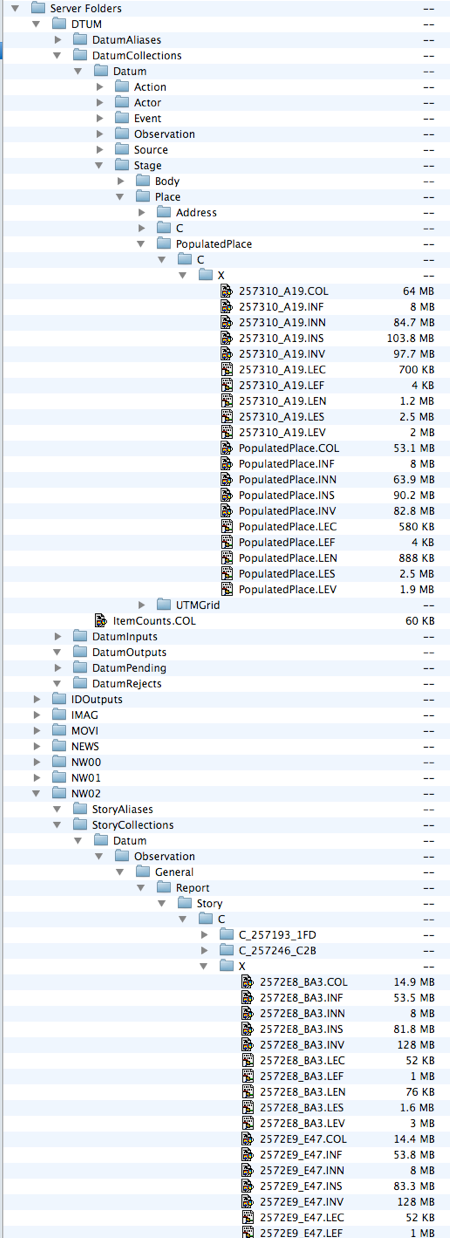 In the earlier discussions (see MitoQuest™ collections section), we briefly alluded to the fact that the content of any given folder within a server’s collection folder hierarchy may include multiple .COL (and associated) files as illustrated in the screen shot to the left. Here we see that within the ‘PopulatedPlace’ folder of the Datum server, there are two distinct .COL files PopulatedPlace.COL and 257310_A19.COL. Note that these collections are embedded within a nested sub-folder path given by “C:X” within the actual type’s folder. The ‘C’ stands for collections and other sub-folders within the type folder may exist with different one-letter indicators. However in common usage, only the ‘C’ sub-folder will be encountered. The ‘X’ folder within ‘C’ always contains the latest set of collection files and for small installations with little data, the ‘X’ sub-folder may be the only one ever seen within the ‘C’ folders. If you look at the visible portion of the collections folder for the ‘NW02’ drone further down in the screen shot, you can see that within the ‘C’ folder there are two additional sub-folders over and above the ‘X’ sub-folder namely C_257193_1FD and C_257246_C2B. This screen shot the ‘Story‘ server cluster contains approximately 2.5 million news stories (distributed across the drones), the total size of the Story server cluster collections folders is 125GB, and the total number of Story data collections (see later discussions) is approximately 450.
In the earlier discussions (see MitoQuest™ collections section), we briefly alluded to the fact that the content of any given folder within a server’s collection folder hierarchy may include multiple .COL (and associated) files as illustrated in the screen shot to the left. Here we see that within the ‘PopulatedPlace’ folder of the Datum server, there are two distinct .COL files PopulatedPlace.COL and 257310_A19.COL. Note that these collections are embedded within a nested sub-folder path given by “C:X” within the actual type’s folder. The ‘C’ stands for collections and other sub-folders within the type folder may exist with different one-letter indicators. However in common usage, only the ‘C’ sub-folder will be encountered. The ‘X’ folder within ‘C’ always contains the latest set of collection files and for small installations with little data, the ‘X’ sub-folder may be the only one ever seen within the ‘C’ folders. If you look at the visible portion of the collections folder for the ‘NW02’ drone further down in the screen shot, you can see that within the ‘C’ folder there are two additional sub-folders over and above the ‘X’ sub-folder namely C_257193_1FD and C_257246_C2B. This screen shot the ‘Story‘ server cluster contains approximately 2.5 million news stories (distributed across the drones), the total size of the Story server cluster collections folders is 125GB, and the total number of Story data collections (see later discussions) is approximately 450.
The process that gives rise to these additional collections and folders is known as server collection rollover and is essentially a way of managing collections of data that will not fit into a 4GB addressing space and may indeed span petabytes. Since all collections are based on Mitopia’s flat memory model, the maximum possible size of any given collection cannot exceed 4GB. In practice, Mitopia® limits the size of server .COL files to more like 64MB so that they can be individually loaded and manipulated relatively rapidly. If server collections and inverted index files were allowed to get significantly bigger than this value, one might notice a performance slowdown when the collection exceeded around 1GB.
The current collection to which new records are added for a given type is always in sub-folder X and is called typeName.COL, where ‘typeName’ is the name of the type involved. When this collection or its associated inverted index files reach the approximate size limits used by the MitoQuest™ server code, it is “rolled over” and renamed and a new typeName.COL collection is begun to hold further new records. The collection is rolled over into the ‘X’ folder by renaming it based on a number computed from the current date and time. The weird file names used are basically hexadecimal equivalents of the SDN-based date encoding described in the previous section where the string before the underscore represents the SDN and the string after represents the time of day.
When the server performs queries or other operations, it iterates through all the .COL collections found for the type and they are generally represented in memory just as a collection ‘stub’ occupying no more than a few hundred bytes, that is they are file-based collections (see other Mitopia® documentation). This means that the server can theoretically simultaneously address and manipulate literally millions of such collections through the type collections abstraction without having to load them all into memory.
After a given type’s collection has been rolled over enough times, the ‘X’ folder can become quite cluttered and OS file operations that involve directory navigation become appreciably slower. For this reason, the MitoQuest™ layer automatically implements a second layer of rollover behavior when the ‘X’ folder gets 500 or more files created within it. In this case, MitoQuest™ rolls over the ‘X’ folder itself by renaming it based on the current time as illustrated for the ‘NW02’ drone collections in the screen shot. Once having rolled over the folder, a new ‘X’ folder and a new ‘typeName.COL’ file within it are created and server operation continues as before. The result of this two-layer rollover strategy is that the MitoQuest™ layer is capable of persisting, indexing, and querying petabytes (or more) of data limited only by the available disk space. These folders can of course be distributed arbitrarily over many disks (referenced through aliases higher up in the folder tree). The result is essentially unlimited available disk space for any given server node, which combined with the ability to cluster across nodes and/or types arbitrarily can dynamically solve virtually any scaling problem.
Collection ‘rollover’ occurs when a new record is added to a collection and results in the final collection size exceeding the size limit. However, there is also another condition where the collection grows to exceed the limit not by adding records, but by adding to existing records. This condition most commonly occurs in multimedia servers. For example in the ‘IMAG’ server a collection may be created rapidly by mining a large source containing many image references. Since the actual ingestion of the associated multimedia images and the creation of the ‘preview’ images in the ‘@picon’ field happens later as the server processes image files from the input folder, it is quite possible that while asynchronously adding these ‘@picon’ fields, the total collection size may exceed the limit. When this condition occurs, the server is forced to ‘split’ the collection involved into two approximately equal sized halves. This splitting process happens automatically when necessary and the resultant collection files follow similar naming conventions to those created by a rollover.
A number of tools are provided in the “Server Clusters and the Maintenance Window” which are aware of the MitoQuest™ collection folder hierarchy, and are thus capable of redistributing the contents of any folders encountered amongst the drones of a clustered server. Although tempting, one should not attempt to re-distribute server collections by hand as special measures must be taken with the ‘typeName.COL’ file which will normally appear in all the drones of the cluster, even though each one has different contents. Manual copying of collection files will encounter problems handling these files and so should be avoided.
As mentioned elsewhere, any folder within a server folder hierarchy can be replaced by an alias to another location, so it is quite possible to split the collections into multiple disks or into RAID and/or SAN configurations in order to improve file access times and thus server performance. This becomes particularly important when many ‘drone’ members of the server cluster are running on the same machine in separate instances of the Mitopia® application.