The productivity of software projects have increased by less than 10 times since 1970. In 1970, COBOL was the state of the art, mainframes were in vogue and both the PC and the internet were only a dream. By year 2000, end user and distributed computing exploded. Software developers are now developing in a bewildering and ever changing variety of compiled, interpreted, scripted, web-based, visual, and other languages.
One of the most accepted means of measuring software productivity is by measuring the number of hours it takes a programmer to create one ‘function point’. The function point measure was defined in 1979 by Alan Albrecht and is essentially a measure of the amount of business functionality an information system provides to a user. The graph below (from www.SoftwareMetrics.com) shows the historical trend since 1970 for programmer productivity measured in terms of the number of programmer hours it takes to complete a single function point:
Unlike productivity, the size of software projects has increased at dramatic rates. Since 1970 projects have grown more than 20 times as large as they were in the 1970’s. The trend is towards larger and more complex software. The graph below (also from www.SoftwareMetrics.com) plots this trend:
During this same period, the transistor count of the computers on which our software runs has increased according to Moore’s law by a factor of over a million times as shown in the Moore’s Law graph below (from Wikipedia):
Note that the vertical scale on this chart is logarithmic, not linear. Obviously not all of the increased number of transistors on a chip result in increased real-world performance since other factors such as memory bandwidth come into play, so let us conservatively say that computer hardware performance has increased by a factor of 100,000 while over the same period, the productivity of the programmers that make use of that increased power has increased by a factor of less than ten!
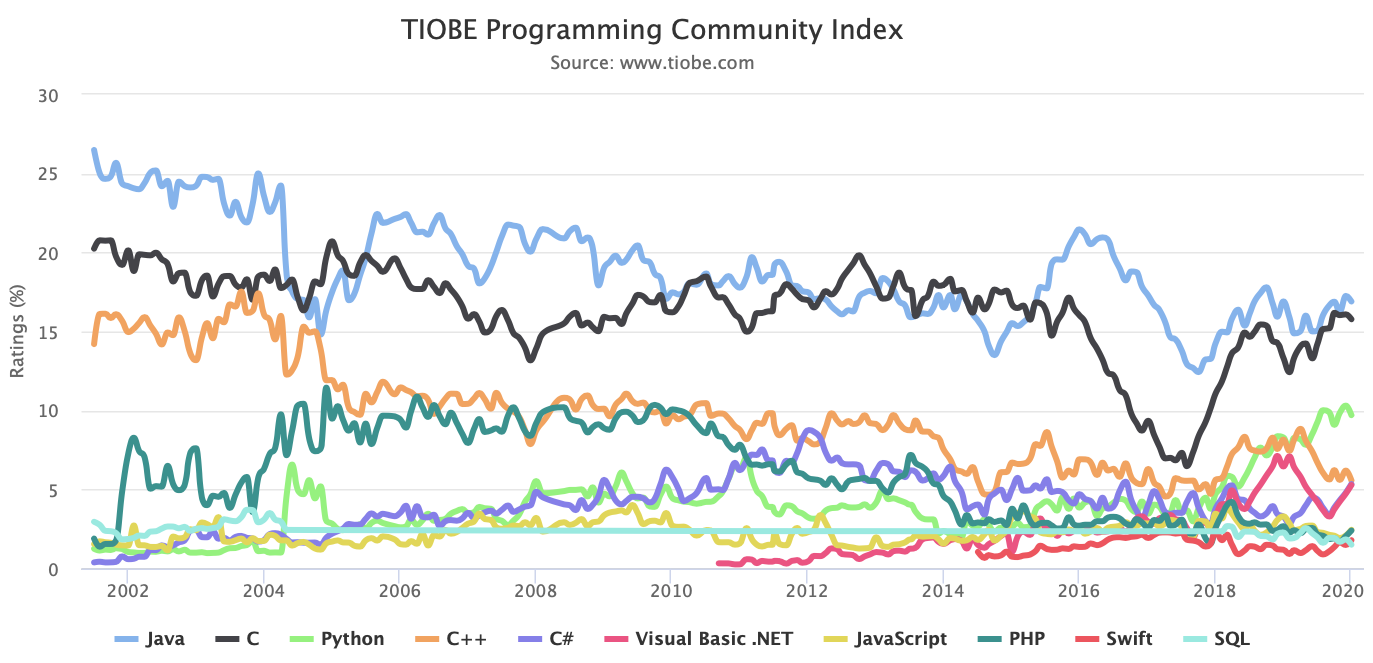
Every year it seems there are new programming languages invented based on new paradigms like object oriented (actually that too dates from the 1970’s), component based (1980’s), concurrent, data-driven, and others. All these developments claim to improve programmer productivity (at least within some domain), however, given our productivity factor of less than 10, it is clear that none has delivered in any substantial way. If we look at the long term trends (see the programming language index from www.tiobe.com below), none of these ‘fad’ languages appear to have made any dent in the dominance of classical procedural/OOP languages (of which C, according to Tiobe, has been the #1 language for most of the last 25 years):
In other words, other than the fact that programs now tend to be built on top of large libraries/classes of existing functionality (thus alleviating the need for the programmer to implement that functionality themselves), and that our development tools are greatly improved (which most likely accounts for much of the development speedup factor), we are basically writing new software code almost the same way and at the same rate as we did back in the 1970’s. The steep rise in size and complexity of the projects undertaken combined with the relatively flat curve for programmer productivity, is at the root of the alarming trend in large software project failures that we now see (see here , here, and here for examples).
Proponents of the object oriented languages would claim otherwise, but this is not true – look at the Tiobe graph above and draw an imaginary average line through the established OOP language graphs (e.g., Java, C++) for the last 10 years or so, both trend downwards indicating that interest has waned, presumably because the languages have not delivered on the promises made. Only Objective-C and C# (OO languages) trend upwards, and these are relatively young (driven by Apple and Microsoft respectively). It is likely that they too will peak over time, indeed it looks like this may have already begun for C#.
Only C, one of the lowest level and oldest languages (early 70’s) remains relatively level over the long term. This is because C essentially has no ‘paradigm’ and enforces no constraints or application ‘domain’ on the programmer. There is no safety net in C, you can do anything you want, including shoot yourself in the foot. To step outside the box and create something revolutionary, one does not jump into somebody else’s sandbox (i.e., programming language) and accept whatever constraints it imposes in the name of boosting programmer productivity in a specialized area, encouraging a particular design methodology, or protecting the unwary programmer from error.
In my opinion, it would take a programmer productivity boost of way more than 10 times to justify such language hopping. Such a boost has not been demonstrated for any new language once one sorts out what is language and what is library. The Tiobe graph shows that despite the fact that many programmers feel the allure of the ‘shoal’, and often chase gleaming new language trends, over time the bulk of the real work gets done in languages like C.
What is the reason for computer science’s failure to improve itself significantly even while the products of computer science are responsible for many if not most of the improvements in other fields? Of all technologies out there, the discipline of computer science may be one of the slowest changing there is!
We invent new languages continuously, but in the end, measured in real-world productivity, nothing much changes. The constant process of switching to new ‘fad’ languages is nothing more than shuffling the deck chairs on the Titanic. We programmers are sinking in the ocean of our ambition, dragged down by the weight of the hammer and chisels we use to write our code.
To answer this question, we must evaluate at the deepest level what it is that we programmers actually spend our time doing. I would contend that with the possible exception of embedded control systems programming, what most of the rest of the programming community does can be abstracted down into the very simple diagram below:
The basic job of all programs is to convert data or input from one form that is not wholly controlled by the ‘system’ (i.e., the left of the diagram) to another form that is fixed in stone (i.e., the right) and upon which the ‘system’ is essentially built. Sometimes both sides are fixed in stone. The RHS of the diagram may be a database, an internal format, one or more existing systems, or any format covered by a standard/protocol. In essence the reason for the creation of the ‘program’ (which is usually built on existing libraries/classes) is that the ‘rock’ on the right hand side pre-existed the ‘program’, and the choice (probably required) has been made to interface to the ‘rock’ in order to create a new application sourced/controlled from the ‘new’ left side, which may be no more than a GUI. The program’s job is to translate bidirectionally between the two initially diverse world views.
The reason that programmer productivity has been essentially stagnant for 40 years is that the programming languages we use are generic and general purpose, that is they are not tied specifically to the ‘paradigm’ of either the left or the right side. This makes sense since if languages were not this way, they would find little applicability and would die out fast. Unfortunately, that which ensures the language’s survival, also places a huge burdon on the programmer. The program created must span the gap between the left and right sides, while simultaneously ensuring that the bridge built can withstand the erosive forces of change. Not surprisingly few succeed when the gap is vast or complex, and none get any real help from the language, whatever it may be.
As far as tying a language to the left side is concerned, the reason this rarely happens is clear. Since most left-side problems are unique and distinct in some way, if this were not so, the customer would have purchased an existing ‘program’ designed specifically to interface to that customer’s left-side situation. So languages for which the programming ‘paradigm’ is shifted heavily to the left tend to be highly specialized into a small well defined niche. This renders them useless for other domains and highly vulnerable to change in the environment. Since pervasive change in the environment is the only real constant, these languages, like standard languages with a hot new [generic] ‘paradigm’ that does not bridge the gap, tend to die out fast.
This leaves specialized languages that slant heavily towards the ‘paradigm’ of an existing ‘rock’ to the right. There are many examples of such languages, particularly in cases where the ‘rock’ is a relational database (i.e., SQL), Web Browsers (e.g., JavaScript), Enforced Operating System APIs (e.g., Objective-C, C#), Assembly Language (i.e., a specific microprocessor architecture), and others.
There are two major disadvantages for a language whose paradigm leans significantly to the right like this, the first and most obvious is that the language’s viability becomes dependent on the existence of the ‘rock’ that the language was tied to. If the ‘rock’ gets overtaken by new technology, the language likely does as well. Fortunately truly large ‘rocks’ (e.g., relational databases) tend to erode quite slowly. The second issue is that by moving to the right like this, the language increases the ‘conceptual distance’ that the programmer has to bridge in order to implement the desired functionality on the left side. The bigger the ‘rock’, the greater this difference span becomes.
For example if the ‘rock’ is a relational database, the programmer must understand SQL (the ISO SQL standard is over 3,000 pages) and interface that to his internal program logic, then that internal logic must be interfaced to the left side, probably through use of an additional external library with a ‘paradigm’ that is unrelated to SQL. Usually to bridge the gap completely, the programmer is forced to use and master two or more distinct programming languages and paradigms that are each distinct from any application specific paradigm that program code itself may embody. The bottom line is that although the programmer has been spared the task of implementing the various external components that must be integrated to create the ‘system’, the complexity of that integration task has not decreased, it may in fact have increased.
So, over time (see the www.tiobe.com chart) it is clear that the programming approach of choice is to go with a ‘generic’ abstract language, and utilize libraries/classes (with APIs in the chosen ‘generic’) to tie into the external ‘rocks’. The language itself can do nothing to help our productivity, and so programmer productivity has increased by a factor of less than 10 over 40 years, that is it!
To make any substantial change to productivity, we must take a whole different approach to programming languages, and this must be something far more fundamental than any programming language paradigm explored to date. We need an adaptive language that is firmly and simultaneously rooted in the paradigms of both the left and the right side of our diagram , regardless of what the left may be, and which, to the maximum extent possible, bridges the gap for the programmer by reducing the cognitive dissonance. Since we know that the format/paradigm of the left side is completely unconstrained, it appears logically impossible that a language could be ‘native’ in both the left and right side of the diagram. As it turns out however, this is not so.
The unique Mitopia® concept of ‘heteromorphic’ languages, which I will discuss in future posts, finally solves this issue.
Updated TIOBE Index for Jan 2020
Update Jan 2020: The diagram above shows the updated TIOBE index for January 2020 (this original post was from 2012). Note that in the intervening time, not much has changed. C and Java are both way ahead of the pack, and the pack itself is largely unchanged with the exception that Objective-C has been replaced by Swift as Apple’s mandated platform language. C is once again poised to become the top language as explained by TIOBE in this months notes:
C awarded Programming Language of the Year 2019: Everybody thought that Python would become TIOBE’s programming language of the year for the second consecutive time. But it is good old language C that wins the award this time with an yearly increase of 2.4%. Runners up are C# (+2.1%), Python (+1.4%) and Swift (+0.6%). Why is the programming language C still hot? The major drivers behind this trend are the Internet of Things (IoT) and the vast amount of small intelligent devices that are released nowadays. C excels when it is applied to small devices that are performance-critical. It is easy to learn and there is a C compiler available for every processor. Congratulations to C!

 Unlike productivity, the size of software projects has increased at dramatic rates. Since 1970 projects have grown more than 20 times as large as they were in the 1970’s. The trend is towards larger and more complex software. The graph below (also from www.SoftwareMetrics.com) plots this trend:
Unlike productivity, the size of software projects has increased at dramatic rates. Since 1970 projects have grown more than 20 times as large as they were in the 1970’s. The trend is towards larger and more complex software. The graph below (also from www.SoftwareMetrics.com) plots this trend: During this same period, the transistor count of the computers on which our software runs has increased according to Moore’s law by a factor of over a million times as shown in the Moore’s Law graph below (from Wikipedia):
During this same period, the transistor count of the computers on which our software runs has increased according to Moore’s law by a factor of over a million times as shown in the Moore’s Law graph below (from Wikipedia):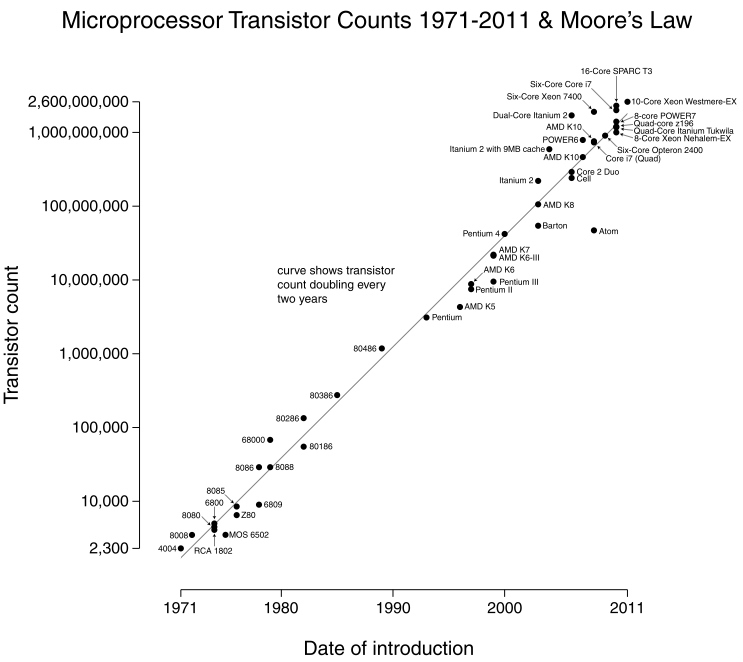 Note that the vertical scale on this chart is logarithmic, not linear. Obviously not all of the increased number of transistors on a chip result in increased real-world performance since other factors such as memory bandwidth come into play, so let us conservatively say that computer hardware performance has increased by a factor of 100,000 while over the same period, the productivity of the programmers that make use of that increased power has increased by a factor of less than ten!
Note that the vertical scale on this chart is logarithmic, not linear. Obviously not all of the increased number of transistors on a chip result in increased real-world performance since other factors such as memory bandwidth come into play, so let us conservatively say that computer hardware performance has increased by a factor of 100,000 while over the same period, the productivity of the programmers that make use of that increased power has increased by a factor of less than ten!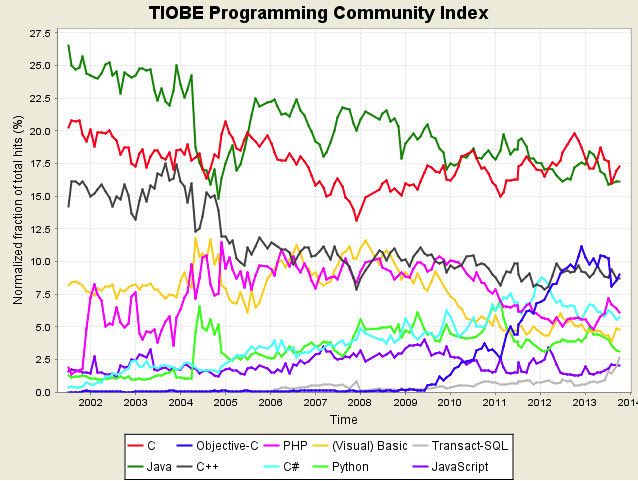 In other words, other than the fact that programs now tend to be built on top of large libraries/classes of existing functionality (thus alleviating the need for the programmer to implement that functionality themselves), and that our development tools are greatly improved (which most likely accounts for much of the development speedup factor), we are basically writing new software code almost the same way and at the same rate as we did back in the 1970’s. The steep rise in size and complexity of the projects undertaken combined with the relatively flat curve for programmer productivity, is at the root of the alarming trend in large software project failures that we now see (see here , here, and here for examples).
In other words, other than the fact that programs now tend to be built on top of large libraries/classes of existing functionality (thus alleviating the need for the programmer to implement that functionality themselves), and that our development tools are greatly improved (which most likely accounts for much of the development speedup factor), we are basically writing new software code almost the same way and at the same rate as we did back in the 1970’s. The steep rise in size and complexity of the projects undertaken combined with the relatively flat curve for programmer productivity, is at the root of the alarming trend in large software project failures that we now see (see here , here, and here for examples).
 So, over time (see the www.tiobe.com chart) it is clear that the programming approach of choice is to go with a ‘generic’ abstract language, and utilize libraries/classes (with APIs in the chosen ‘generic’) to tie into the external ‘rocks’. The language itself can do nothing to help our productivity, and so programmer productivity has increased by a factor of less than 10 over 40 years, that is it!
So, over time (see the www.tiobe.com chart) it is clear that the programming approach of choice is to go with a ‘generic’ abstract language, and utilize libraries/classes (with APIs in the chosen ‘generic’) to tie into the external ‘rocks’. The language itself can do nothing to help our productivity, and so programmer productivity has increased by a factor of less than 10 over 40 years, that is it!