In an earlier post I described Mitopia’s patented Lexical analyzer technology and the unique capabilities it supports. In this post I would like to introduce the concept of ‘Stemming‘ which is fundamental to effective text searching, and begin to lay the groundwork for future posts that will detail how Mitopia’s patented ‘universal stemmer’ finally allows accurate and universal cross language search, something that has long been a holy grail of the information retrieval field. First lets start out with a review of the stemming field as it exists today.
Definition Stemming is the process for reducing inflected (or sometimes derived) words to their stem, base or root form — generally a written word form. The stem need not be identical to the morphological root of the word; it is usually sufficient that related words map to the same stem, even if this stem is not in itself a valid root. The algorithm has been a long-standing problem in computer science; the first paper on the subject was published in 1968. The process of stemming, often called conflation, is useful in search engines for query expansion or indexing and other natural language processing problems.
Stemming programs are commonly referred to as stemming algorithms or stemmers.
A stemmer for English, for example, should identify the string “cats” (and possibly “catlike”, “catty” etc.) as based on the root “cat”, and “stemmer”, “stemming”, “stemmed” as based on “stem”. A stemming algorithm reduces the words “fishing”, “fished”, “fish”, and “fisher” to the root word, “fish”.
History of Stemmers
The first ever published stemmer was written by Julie Beth Lovins in 1968. This paper was remarkable for its early date and had great influence on later work in this area.
A later stemmer was written by Martin Porter, and was published in the July 1980 issue of the journal Program. This stemmer was very widely used and became the de-facto standard algorithm used for English stemming. Dr. Porter received the Tony Kent Strix award in 2000 for his work on stemming and information retrieval.
Many implementations of this algorithm were written and freely distributed; however, many of these implementations contained subtle flaws. As a result, these stemmers did not match their potential. To eliminate this source of error, Martin Porter released an official free-software implementation of the algorithm around the year 2000. He extended this work over the next few years by building Snowball, a framework for writing stemming algorithms, and implemented an improved English stemmer together with stemmers for several other languages. Various other custom stemming algorithms have been developed for both English and other languages.
Overview of Stemming Algorithms
There are several types of stemming algorithms which differ in respect to performance and accuracy and how certain stemming obstacles are overcome.
Brute Force Algorithms
The term brute force is borrowed from a concept in artificial intelligence research and problem solving in mathematics denoted as brute force search. Brute force stemmers employ a lookup table which contains relations between root forms and inflected forms. To stem a word, the table is queried to find a matching inflection. If a matching inflection is found, the associated root form is returned.
Brute force approaches are criticized for their general lack of elegance in that no algorithm is applied that would more quickly converge on a solution. In other words, there are more operations performed during the search than should be necessary. Brute force searches consume immense amounts of storage to host the list of relations (relative to the task). The algorithm is only accurate to the extent that the inflected form already exists in the table. Given the number of words in a given language, like English, it is unrealistic to expect that all word forms can be captured and manually recorded by human action alone. Manual training of the algorithm is overly time-intensive and the ratio between the effort and the increase in accuracy is marginal at best.
Brute force algorithms do overcome some of the challenges faced by the other approaches. Not all inflected word forms in a given language “follow the rules” appropriately. While “running” might be easy to stem to “run” in a suffix stripping approach, the alternate inflection, “ran”, is not. Suffix stripping algorithms are somewhat powerless to overcome this problem, short of increasing the number and complexity of the rules, but brute force algorithms only require storing a single extra relation between “run” and “ran”. While that is true, this assumes someone bothered to store the relation in the first place, and one of the major problems of improving brute force algorithms is the coverage of the language.
Brute force algorithms are initially very difficult to design given the immense amount of relations that must be initially stored to produce an acceptable level of accuracy (the number can span well into the millions). However, brute force algorithms are easy to improve in that decreasing the stemming error is only a matter of adding more relations to the table. Someone with only a minor experience in linguistics is capable of improving the algorithm, unlike the suffix stripping approaches which require a solid background in linguistics.
For technical accuracy, some programs may use suffix stripping to generate the lookup table given a text corpus, and then only consult the lookup table when stemming. This is not regarded as a brute force approach, although a lookup table is involved.
Suffix Stripping Algorithms
Suffix stripping algorithms do not rely on a lookup table that consists of inflected forms and root form relations. Instead, a typically smaller list of “rules” are stored which provide a path for the algorithm, given an input word form, to find its root form. Some examples of the rules include:
if the word ends in ‘ed’, remove the ‘ed’
if the word ends in ‘ing’, remove the ‘ing’
if the word ends in ‘ly’, remove the ‘ly’
Suffix stripping approaches enjoy the benefit of being much simpler to maintain than brute force algorithms, assuming the maintainer is sufficiently knowledgeable in the challenges of linguistics and morphology and encoding suffix stripping rules. Suffix stripping algorithms are sometimes regarded as crude given the poor performance when dealing with exceptional relations (like ‘ran’ and ‘run’). The solutions produced by suffix stripping algorithms are limited to those lexical categories which have well known suffices with few exceptions. This, however, is a problem, as not all parts of speech have such a well formulated set of rules. Lemmatisation attempts to improve upon this challenge.
Lemmatisation Algorithms
A more complex approach to the problem of determining a stem of a word is lemmatisation. This process involves first determining the part of speech of a word, and applying different normalization rules for each part of speech. The part of speech is first detected prior to attempting to find the root since for some languages, the stemming rules change depending on a word’s part of speech.
This approach is highly conditional upon obtaining the correct lexical category (part of speech). While there is overlap between the normalization rules for certain categories, identifying the wrong category or being unable to produce the right category limits the added benefit of this approach over suffix stripping algorithms. The basic idea is that, if we are able to grasp more information about the word to be stemmed, then we are able to more accurately apply normalization rules (which are, more or less, suffix stripping rules).
Stochastic Algorithms
Stochastic algorithms involve using probability to identify the root form of a word. Stochastic algorithms are trained (they “learn”) on a table of root form to inflected form relations to develop a probabilistic model. This model is typically expressed in the form of complex linguistic rules, similar in nature to those in suffix stripping or lemmatisation. Stemming is performed by inputting an inflected form to the trained model, and having the model produce the root form according to its internal ruleset. This is similar to suffix stripping and lemmatisation, except that the decisions involved in applying the most appropriate rule, or whether or not to stem the word and just return the same word, or whether to apply two different rules sequentially, are applied on the grounds that the output word will have the highest probability of being correct (which is to say, the smallest probability of being incorrect, which is how it is typically measured).
Hybrid Approaches
Hybrid approaches use one or more of the approaches described above in unison. A simple example is a suffix tree algorithm which first consults a lookup table using brute force. However, instead of trying to store the entire set of relations between words in a given language, the lookup table is kept small and is only used to store a minute amount of “frequent exceptions” like “ran => run”. If the word is not in the exception list, apply suffix stripping or lemmatisation and output the result.
Affix Stemmers
In linguistics, the term affix refers to either a prefix or a suffix. In addition to dealing with suffices, several approaches also attempt to remove common prefixes. For example, given the word indefinitely, identify that the leading “in” is a prefix that can be removed. Many of the same approaches mentioned earlier apply, but go by the name affix stripping.
Summary of Stemming Today
While much of the early academic work in this area was focused on the English language (with significant use of the Porter Stemmer algorithm), many other languages have been investigated.
Hebrew and Arabic are still considered difficult research languages for stemming. English stemmers by comparison are fairly trivial (with only occasional problems, such as “dries” being the third-person singular present form of the verb “dry”, “axes” being the plural of “axe” as well as “axis”); but stemmers become harder to design as the morphology, orthography, and character encoding of the target language becomes more complex. For example, an Italian stemmer is more complex than an English one (because of more possible verb inflections), a Russian one is more complex (more possible noun declensions), a Hebrew one is even more complex (due to non-catenative morphology and a writing system without vowels), and so on. Korean is considered one of the most challenging languages to stem.
Multilingual Stemming
Multilingual stemming applies morphological rules of two or more languages simultaneously instead of rules for only a single language when interpreting a search query. Commercial systems using multilingual stemming exist but are extremely rare.
Error metrics
There are two error measurements in stemming algorithms, overstemming and understemming. Overstemming is an error where two separate inflected words are stemmed to the same root, but should not have been – a false positive. Understemming is an error where two separate inflected words should be stemmed to the same root, but are not – a false negative. Stemming algorithms attempt to minimize each type of error, although reducing one type can lead to increasing the other
Information Retrieval and Commercial Use
Stemmers are common elements in query systems such as Web search engines, since a user who runs a query on “daffodils” would probably also be interested in documents that contain the word “daffodil” (without the s). The effectiveness of existing stemmers for English query systems were soon found to be rather limited. An alternative approach, based on searching for n-grams rather than stems, may be used instead. Also, recent research has shown greater benefits for retrieval in other languages. Many commercial companies have been using stemming since at least the 1980’s and have produced algorithmic and lexical stemmers in various languages..
Google search adopted word stemming in 2003. Previously a search for “fish” would not have returned “fishing”. Other software search algorithms vary in their use of word stemming. Programs that simply search for substrings obviously will find “fish” in “fishing” but when searching for “fishes” will not find occurrences of the word “fish”.
Issues with Existing English Stemmers
The overwhelming majority of stemming implementations today are of the Suffix Stripping type, indeed it is difficult to find an implementation of any other stemming algorithm in the literature. The reason for this is that despite their significant shortcomings, suffix stripping algorithms are fairly easy to develop compared with any other technique, and can be made very fast and efficient. Affix stripping algorithms (i.e., those that also strip prefixes) have proved notoriously difficult, since in most languages the first few characters of a word cannot be safely stripped off without completely destroying the meaning. Meanwhile, the overhead of maintaining pure brute-force algorithms has made them prohibitively expensive to deploy, while Lemmatisation and Stochastic approaches have yet to show any significant improvements over existing suffix stemmers in real world tests. As a consequence, the art of language stemming has not progressed in any significant way for many decades.
Part of the problem with existing stemmers is their very low levels of accuracy when conflating word forms which has led to stemmers being considered of marginal benefit in search by many researchers. To get a feel for the accuracy of different stemming algorithms, some of the more successful ones have been incorporated into the Mitopia® stemming framework so that Mitopia’s universal stemmer (called the Fairweather stemmer) can be compared with them side by side. Figure 1 shows the result of running these various algorithms on a small sample set of words. The first column shows the input word, the second column the selected stemmed output (chosen from all stemmer outputs as discussed later), the third column shows the output from the Fairweather stemmer, and subsequent columns show the output from various other English language stemmers (where a ‘-‘ in a column indicates that the stemmer made no change or failed to stem).
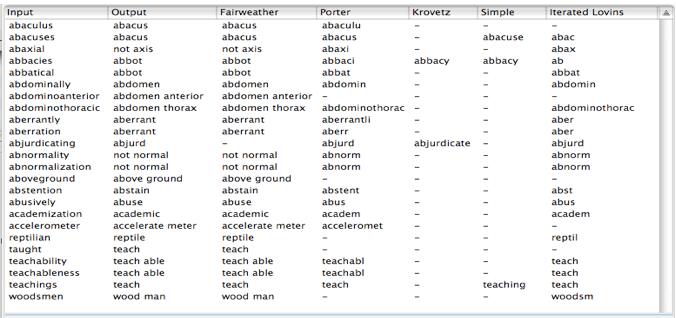
Table 1 – Comparison of Various Stemmer Outputs
In all cases, the output from the Fairweather stemmer is correct. The reasons for this will be discussed later. If we examine the output from the other stemmers, we can see that there is a great deal of variation between them, and that to a greater or lesser degree all current stemmers exhibit the following classes of problems:
- The stemmed outputs are usually not actual words but are instead word fragments. This is not generally an issue since stemmer outputs are rarely displayed, but are only used for searching, where the only important thing is that all variants of a root word map to the same root. Nonetheless, if producing correct output were a performance criteria, the highest score in this example for any existing stemmer would be 12.5% for the “Iterated Lovins” stemmer, closely followed by 8.3% for the ”Porter” stemmer. The Fairweather stemmer scores 100% by this measure (including correctly rejecting a misspelling for the word “abjurdicating”). In a multilingual search system however, this is a fatal flaw, since to meaningfully search across roots requires valid root words as a stemmer output that can be linked across languages.
- The stemmers have no ability to conflate words that should yield the same root but are quite different (the words “abacus” and “abaculus” above are an example).
- The stemmers only handle suffix stripping, they cannot handle prefix stripping (see the word “abnormality” where the prefix “ab” means “not”). Prefix stripping is virtually impossible with standard algorithms since it can easily destroy valid words beginning with the same prefix. The list above has many words beginning with “ab” yet in only three cases (out of 24) should this be treated as a prefix.
- The stemmers cannot handle compound words, i.e., those made up of multiple roots (see the words “abdominoanterior”, “abdominothoracic”, and “aboveground” in the list above).
- The stemmers cannot handle words containing multiple roots connected by infix sequences (see the word “woodsmen” above where the “s” is an infix sequence connecting the two roots “wood” and “man” in which “men” must be recognized as an irregular plural of “man”).
- The stemmers cannot conflate irregular plurals (e.g., “men” and “man” above), nor can they handle irregular tenses (e.g., “taught” and “teach” above).
- The stemmers often map words that should have different root meanings onto the same root (see examples below).
- The stemmers do a very poor job even of conflating words with differing suffixes onto the same root (e.g. “teachability”, “teachableness”, and “teachings” above).
- The stemmers cannot conflate word variants, that is words whose spelling varies depending on the part of speech (e.g., the word “abstain” and “abstention”).
- The stemmers cannot preserve and output semantic meaning of suffixes where necessary (the word “accelerometer” above is an example of the common suffix “ometer”, a better example might be the word “clueless” which should result in the output “without clue” as a result of preserving the meaning of the recognized suffix “less”.
To get a better handle on the impact of stemming on the relevance of search results, one must query a large corpus with each stemmer and then manually examine each document to see how accurate the returned results were. This is a very labor-intensive process and the results can be highly domain dependent. For this reason there is very little hard data available on stemmer accuracy in a general sense. In order to get some feel for stemmer “meaning” accuracy, that is how accurately does each stemmer map morphological variants to the same “meaning” root, we typed in every word and its morphological variants from a single page of the unabridged dictionary, then dumped the various stemmer results (see table below). By examining how many such words are mapped to the correct unique root (even if that root is a meaningless fragment), we can get a true measure of how good a job each of the stemmers is doing in terms of search accuracy.
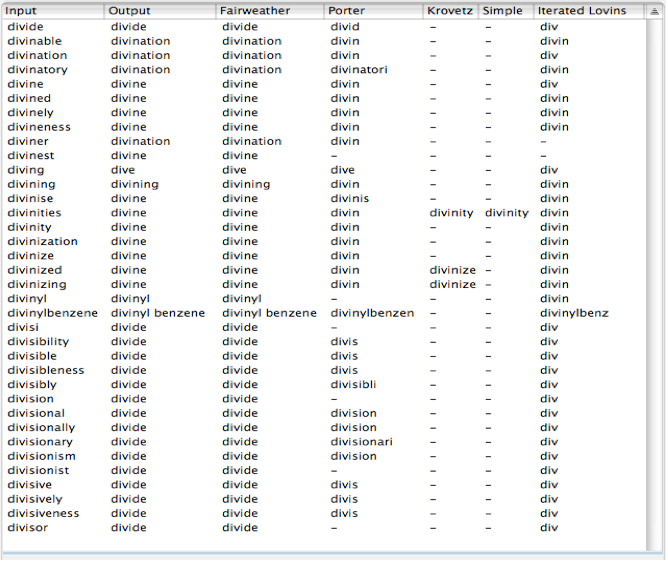
Table 2 – Comparative Stemming Accuracy for Various Algorithms
Once again, the output from the Fairweather stemmer is correct, but notice that some of the words are very difficult to distinguish by any simple algorithmic means. Take for example the words “diviner” and “divining” which all other algorithms that succeed in stemming, incorrectly map to the root “divine” as opposed to “divination” which has a very different meaning. If we calculate the most generous count of the number of correct unique root word conflations for each algorithm above given this page of the dictionary, we see that the “Porter” stemmer is correct 29% of the time and the “Iterated Lovins” stemmer 75% of the time, the others scored zero. If fact, as can be seen from the list above, the Iterated Lovins stemmer is an extremely aggressive stemmer, and if we had typed in the next few pages of the dictionary, we would have found that most of the words stemmed to “div”, with the result that the “Iterated Lovins” stemmer actually does not perform significantly better than the “Porter” stemmer for realistic input. For this reason the “Porter” stemmer, despite having an accuracy (by this measure) no better than 30%, has become the dominant stemming algorithm used by most text searching systems today for English.
Because of the poor performance of today’s stemming algorithms, there is considerable debate in the community as to whether they actually do any significant good in improving search results. Clearly any algorithm that could improve search accuracy from 30% to close to 100% in text search engines without adversely impacting run-time performance would be highly desirable. Mitopia’s stemmer development environment contains a tool for comprehensively comparing stemmer algorithm accuracy for large word lists, and the following table presents the results for an English language word list of approximately 450,000 standard English words:
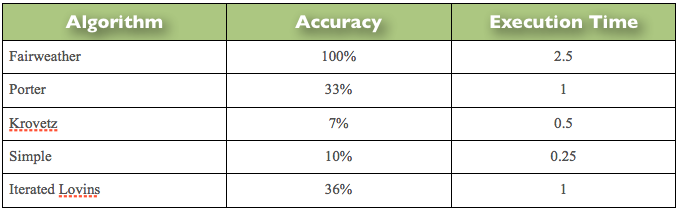
Table 3 – Measured Accuracy and Execution Time of Various Stemming Algorithms
This bulk algorithm compare process works by comparing all the ‘confirmed’ outputs of the Fairweather stemmer (which means the output is 100% correct for the ‘confirmed’ words) for the word list, against the outputs for the other stemmers looking for similarity in the clustering of the stemmed results. Note also that unlike the other stemmer’s, the Fairweather stemmer produces real words as output, not arbitrary word fragments. This distinction is vitally important in cross language search as we will see later.
Of course providing accurate stemming results cannot come at the cost of a run time performance that is dramatically slower than the other algorithms, and fortunately, this is not the case. The third column in the table gives the execution times for the various stemming algorithms under identical circumstances (stemming the same word list) as multiples of the execution time of the Porter stemming algorithm. It is clear that the execution time of all the algorithms discussed is quite similar. The impact of stemmer execution time is primarily on the indexing phase of database construction, and in this context there is little to choose between them. In this test, the Porter stemmer was stemming at the rate of approximately 55,000 words/s. In the case of the Fairweather stemmer, much of its speed is predicated on the use of Mitopia’s lexical analyzer technology.
Issues with Stemming Other Languages
Thus far we have discussed only the English language where stemming technology is the most advanced, in part because of the relative ease of stemming by suffix stripping in English. If we broaden our discussion to other languages and other script systems, the situation becomes far worse. Most languages have no stemmer available, however, the Porter algorithm has been adapted to handle many European languages (Latin languages) since they are actually quite similar in form.
Porter provided the stemmer definition language “Snowball” in order to make the creation of such stemmers easier. Almost all languages are more inflected than English, and as a consequence these variants of the Porter stemmer generally have inferior performance to the English version. When you change the script system to Arabic, Korean, Japanese or any of the countless other script systems, stemmers are few and far between, and their performance to date has generally been abysmal compared with English. The reason for this is that these other languages can contain words that are essentially equivalent to an English sentence, and thus the stemmer would have to handle multiple roots, prefixes, suffixes and even infixes, which makes the creation of effective stemming algorithms by current techniques almost impossible.
Additionally, in scripts other than the Latin script, it is no longer possible to encode characters of the script in a single byte as it is with English, and thus any given character in the word may be physically represented in memory by anything from 2 to 6 bytes in a UTF-8 encoded text stream (Unicode UTF-8 has become the predominant standard for encoding text on computer systems). This more complex encoding makes it impossible to treat text in the simple manner found in standard stemmers, and forces people to create stemmers for non-Latin scripts by converting text into weird English letter encodings, stemming the converted text, and then converting the results back.
To further complicate things, characters in other scripts can be modified by diacritic marks (the French circumflex accent is an example) and these may, or may not, modify the meaning. The end result of all this is that stemming in languages other than English is patchy or non-existent and requires highly skilled linguists and programmers if it is to be attempted. This means that the quality of search in foreign languages is generally much worse that that in English, and that the idea of a system capable of searching across all languages through a single query, regardless of the language of the searcher, is no more than a pipe dream, since such would require a standardized stemmer capable of near 100% accuracy in all languages, and able to correctly extract all meaningful roots (not just word fragments) and map them to a single set of roots that have a common meaning across languages.
 What is required therefore is a single stemming algorithm that can be applied to all known languages regardless of script system, without the need to modify the code in any way, allowing it to be adapted for a language by any non-technical person fluent in that language, which has an accuracy near 100% in all languages, which can conflate roots between languages to form a single searchable root set over all languages, and which is not hopelessly slow in order to achieve all this. Such an algorithm could revolutionize text search as we know it. Mitopia’s stemming framework and the patented stemming algorithm in combination meet all of these criteria. We will explore the overall framework in greater detail in the next post.
What is required therefore is a single stemming algorithm that can be applied to all known languages regardless of script system, without the need to modify the code in any way, allowing it to be adapted for a language by any non-technical person fluent in that language, which has an accuracy near 100% in all languages, which can conflate roots between languages to form a single searchable root set over all languages, and which is not hopelessly slow in order to achieve all this. Such an algorithm could revolutionize text search as we know it. Mitopia’s stemming framework and the patented stemming algorithm in combination meet all of these criteria. We will explore the overall framework in greater detail in the next post.