
We have previously discussed the subject of stemming and its importance to search. Now for historical perspecive, I want to explore Mitopia’s stemming framework which allows a variety of stemming algorithms and techniques to be combined to achieve better results. It should be noted however that this framework and its dictionaries was made largely irrelevant (though it is still in place for proper name identification) once Mitopia’s Fairweather stemming algorithm was developed. This is because no other stemming algorithm can even approximate the same accuracy and so there is little point in including them.
Overview
Mitopia’s stemming solution comprises a unique framework for combining stemming algorithms together in a multilingual environment in order to obtain improved stemming behavior over any individual algorithm, together with a new and unique language independent stemming algorithm based on shortest path techniques (the Fairweather stemmer). The stemming framework provides the necessary logic to combine multiple stemmers in parallel and to merge their results to obtain the best behavior, it also provides mapping dictionaries to overcome the shortcomings of classical stemmers by handling such things as irregular plurals, tense, phrase mapping and entity recognition (to prevent name stemming), even though these dictionaries are largely unnecessary when using the Fairweather stemmer.
The Fairweather stemmer uses a dictionary driven approach to find and combine word parts, and is thus a hybrid stemmer combining aspects of the Affix and brute-force approach, while avoiding the problems with both by using a shortest path algorithm to select from one of a number of possible strategies to stem any given word. The algorithm is far more powerful than any other existing approach, and is based on the premise that in essentially all languages, it is possible to construct all word variations from the following basic pattern:
[ Prefix ] Root { [ Infix ] Root } [ Suffix ]
Where “[…]” implies zero or one occurrence and “{…}” implies zero or more occurrences. In this pattern, the following word components are defined:
- Prefix – is a prefix modifier that will be discarded (or converted to a separate root word) on output. An example is the prefix “un” (meaning not) in the word “unbelievable”. This will be converted to the form “not believe” as a result of prefix recognition.
- Root – is a root word fragment in the language. An example is the word “teach” which is the root of “teaching”, “teachers”, “taught” etc. The fragment may differ from the actual root and is mapped to the true root as a result of stemming.
- Infix – is an infix modifier occurring within a compound word which will be discarded (or converted to a separate root word) on output. Infixes are rare in English, but common in some other languages where words are assembled out of smaller fragments. An example of an infix sequence in English might be “s” as in the dual root word “woodsman”.
- Suffix – is a suffix modifier that will be discarded (or converted to a separate root word) on output. Examples in English are such endings as “ing”, “s”, “able”, etc. Standard English stemming algorithms tend to focus on suffix stripping only
Given this model, the stemmer essentially treats the stemming problem not as a linguistic problem, but as a simple instance of the shortest path problem (e.g., the traveling salesman problem), where the cost for each path can be computed from its word component and the number of characters in it. The goal of the stemmer is to find the shortest (i.e., lowest cost) path to construct the entire word. To do this it uses dynamic dictionaries, constructed as lexical analyzer state transition tables, to recognize the various allowable word parts (via a unique dynamic table driven lexical analyzer) for any given language in order to obtain maximum speed.
The state diagram in Figure 1 below shows all the possible paths the stemming algorithm can follow in order to stem a complete word, where each of the transitions is triggered by recognizing the next sequence of characters encountered in the word as being in either the ‘prefix’, ‘root’, ‘infix’, or ‘suffix’ part dictionaries. If the stemmer finds a path from ‘Start’ to ‘End’ such that every letter of the word is accounted for by valid transitions in this state diagram, it has found one solution for stemming the word and it records the cost (as described later) for the entire path and then re-examines every other possible path permitted by all the fragments contained within the dictionaries provided for the language. The algorithm always selects the lowest cost path found as the stemmed result. If at any point in the process, the algorithm finds itself in any numeric state without an appropriate entry in the necessary part dictionary to get it to the next state, the path has failed and the algorithm falls back to examining other possible paths. Note that it is quite possible for the same sequence of letters to appear in more than one part dictionary so the number of possible paths to examine can be quite large.
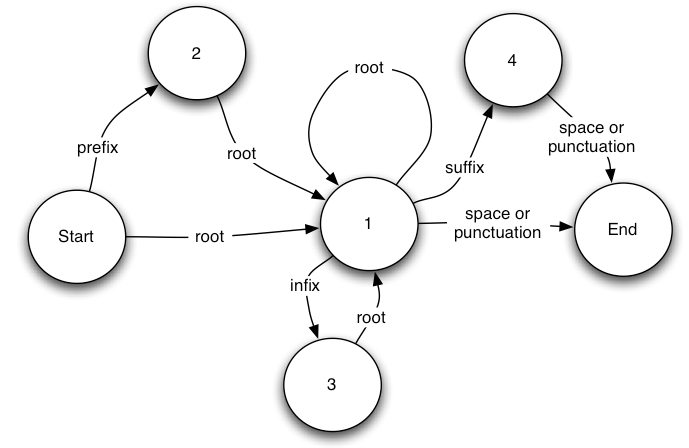
Figure 1 – State Transition Diagram for Fairweather Stemmer
To see in detail how this works, consider the word “abacterial” (meaning not bacterial). The stemmer examines 32 possible paths to stem this word, finding five solutions to parse the complete word as follows:
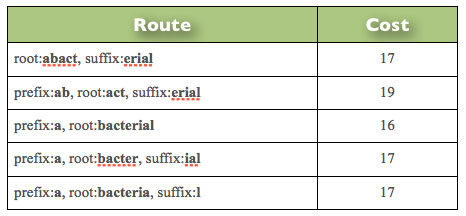
As a result, the algorithm picks the lowest cost path and then (as described later) maps the various fragments used to their final output, resulting in a stemming output of “not bacterium”. As can be seen, in this case the stemmer has not only correctly identified and preserved a significant word prefix (i.e., negation), but it has also mapped the plural form bacterial into the correct singular form bacterium. Other possible but discarded results of this stemming action given the solutions above are “abaction” and “not act”, both of which are obviously wrong since they have completely different meanings from the original word. Note that the ‘suffix’ dictionary used by the algorithm is roughly equivalent to the behavior of the classical suffix stripping algorithms, and yields similar results if used in isolation. In this case, without the ability to recognize prefixes (in this case “a”), the result of a classical stemming algorithm would be the equivalent of “abaction” and this would result in incorrect search results, and the loss of any connection between the word “abacterial” and bacteria in general.
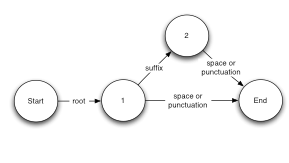 This of course brings up the question of what is the theoretical upper limit on classical suffix stripping stemmer algorithm accuracies given the fact that such algorithms can only recognize the two forms “root” and “root,suffix”, that is their equivalent state diagram would be as show to the right. The answer can be determined by examining the confirmed universal stemmer outputs to see which fraction conform to one of these two forms in the same 450,000 English word list. The answer is that only 62% of all correct stems are comprised of these simple forms. In addition 8% of root words end in valid suffixes, and would thus probably have been over-stemmed by a suffix stripper.
This of course brings up the question of what is the theoretical upper limit on classical suffix stripping stemmer algorithm accuracies given the fact that such algorithms can only recognize the two forms “root” and “root,suffix”, that is their equivalent state diagram would be as show to the right. The answer can be determined by examining the confirmed universal stemmer outputs to see which fraction conform to one of these two forms in the same 450,000 English word list. The answer is that only 62% of all correct stems are comprised of these simple forms. In addition 8% of root words end in valid suffixes, and would thus probably have been over-stemmed by a suffix stripper.
This means that the theoretical maximum accuracy of a suffix stripping algorithm is somewhere between 54 and 62% regardless how sophisticated it is. For other languages, the theoretical limit would generally be significantly lower. This accuracy is also the upper limit on search accuracy for any system using such a stemmer, and this is clearly far from ideal. It is for this reason that MitoSystems developed the Fairweather stemmer algorithm, in order to ensure that Mitopia’s search accuracy was as close as possible to 100%, regardless of the language being used to search.
We will discuss in a lot more detail later exactly how the algorithm performs this stemming process, but before we examine the Fairweather stemmer algorithm in detail, we must first understand the function and operation of Mitopia’s stemming environment itself, for which the Fairweather stemmer is simply one of a number of possible stemming algorithms for use on a given language.
Detailed Description of Stemming Framework
Mitopia’s stemming framework is implemented as a plug-in architecture where each distinct language to be stemmed must register the necessary plug-ins in order to implement the complete suite of logical behaviors required by Mitopia® in order to support stemmed database query. The stemming framework supports the language specific registered plug-ins listed below, which are sufficient to allow the framework to invoke all stemming behaviors that are language specific, while allowing all other logic to be handled by the Mitopia® stemming framework itself. This greatly simplifies the complexity of creating and connecting a stemmer for a new language. These plug-ins are registered symbolically with the framework during program initialization by language name, and plug-in name, where the plug-in symbolic names are as follows:
- “makeStemmerContext” – (typedef QX_MakeContextFn) This plug-in is called during framework initialization for each language registered. The framework provides and maintains a language-specific stemmer context allocation which is passed to all plug-ins for that language when they are subsequently invoked. This context structure can be used by the stemmer to store whatever information and dictionaries it needs as part of its operation. Context allocations must start with a “basic” context structure containing information needed by the framework itself, and which is sufficient to support operation of the Fairweather stemmer, without the need for any additional context, in cases where no other stemming algorithm is available for the target language.
- “killStemmerContext” – (typedef QX_KillContextFn) This plug-in is called by the framework during framework termination for each language registered. The purpose of this callback is to allow cleanup of whatever custom context and allocations were stored by the stemmer during the corresponding “makeStemmerContext” call.
- “invokeStemmer” – (typedef QX_InvokeStemmerFn) This plug-in actually invokes the stemmer(s) registered for the language by calling QX_UniversalStemmer(), and allows any necessary language specific pre- and post- processing to be performed on the text. For UTF-8 text streams pre- and post- processing is rarely required.
- “scanWord” – (typedef ET_ScanWordFn) This plug-in is called by the framework in order to extract the next word in the language from the incoming text stream, in order to pass that word to the language-specific stemmer(s) for stemming. Word scanning is preferably accomplished by a call to the lexical analyzer described later. The only difference between one language and the next is essentially the range of valid UTF-8 characters that are allowed in the language involved.
- “prepareForIndexing” – (typedef ET_PrepareFn) This plug-in is called by the framework on a block of text to be stemmed prior to beginning the word-by-word stemming process. The purpose of “prepareForIndexing” is to scan through the text converting it all to lower case (if appropriate in the script involved) while preserving and protecting from stemming any proper names, acronyms and other specialized words that should not be stemmed. Words that are to be protected are wrapped in the source text by inserting enclosing delimiter sequences, thus causing the stemming algorithm to skip over the word without processing it. This plug-in is designed to overcome the tendency of conventional algorithmic stemmers to stem words that should be left unaltered, for example without this step, the proper name “Hastings” will be stemmed by the “Porter” stemmer to “hast” which will be conflated with words derived from the root “haste” resulting in incorrect search results.
The “invokeStemmer” Plug-in
Given these plug-ins, which will be discussed in detail later, other than housekeeping functions, there is just one key function that represents the primary interface to the Mitopia® stemming framework this is QX_UniversalStemmer(). This function is invoked by the language specific “invokeStemmer” plug-ins in order to perform the actual stemming operation. Regardless of language, “invokeStemmer” plug-ins are typically virtually identical and would as shown in Listing 1 below.

Listing 1 – Form of a typical “invokeStemmer” framework plug-in
The additional parameters implied by the ellipses parameter “…” in the function prototype above include such things as references to the inverted file index (if appropriate), and additional context information that are not relevant to describing the algorithm itself. The function QX_MapRootsToEnglish() is provided by the framework and uses the root word mapping dictionary described below in order to convert any text in the output buffer to the equivalent English text wherever a root word mapping can be found from the native language stemmed root to an English root word(s). The purpose of this logic is to implement the conflation of roots into a common cross-language root set, which in Mitopia® has been chosen to be the English roots. The form of the “invokeStemmer” plug-in allows it to be called from a database subsystem during indexing and furthermore allows the creation of both a native roots index file (to allow language specific search) as well as a mapped roots index file (to allow cross-language search) simply by calling the stemming plug-in twice with different parameters. The plug-in is also called on query terms in order to convert the query words into the appropriate stemmed equivalents so that the database can efficiently search the inverted index file(s). The code for all non-English “invokeStemmer” plug-ins is virtually identical and for this reason the function QX_NonEnglishStemmer() has been supplied which performs all the basic necessary logic (as in Listing 1) including the call to QX_UniversalStemmer() thereby reducing the code for any non-English stemmer to a single function call (with the appropriate parameters!).
The QX_UniversalStemmer() Function
The function QX_UniversalStemmer() performs the following logical steps in order to combine the results from one or more stemming algorithms for the language concerned, as well as handle basic dictionary mapping to improve current generation stemmer behavior (not necessary for the Fairweather stemmer algorithm):
- Check in the phrases dictionary (if present) and if recognized, replace by the phrase meaning text.
- Check in the tense dictionary and if recognized, replace by current tense root and continue.
- Check in the irregulated plural form dictionary and if recognized, replace by the singular root and continue.
- Check in the fixup dictionary and if recognized, replace by the mapped form and continue.
- If any change made above, return.
- Temporarily truncate the input at the first word boundary (if more than one word present).
- Check the stop-word dictionary and if found, discard/ignore.
- If the word is less than ‘minLength’ letters, don’t stem it.
- Check if the word exists in the stemmed word dictionary and if it does, don’t stem it.
- Check against history as follows:
- If ‘cache’ supplied then
- If the word is already in the cache, return the previous cached result
- Else check if the word already exists in the stemmed inverted file(s), if it does, don’t stem it.
- If ‘cache’ supplied then
- Stem the word in parallel using each algorithm supplied in the ‘algorithms’ list and if a stemming action results:
- If the algorithm is the “Fairweather” stemmer
- Accept the stem and return the result (this stemmer is reliable!)
- Else if a word list dictionary is present:
- if stem word in dictionary OR original word not in dictionary
- accept the potential stem
- else
- discard the potential stem
- if stem word in dictionary OR original word not in dictionary
- Else accept the potential stem
- If the algorithm is the “Fairweather” stemmer
- If no change or stemming occurred, done.
- Check the dictionary of root words for each of the stemmed results and if any is found, take the longest one.
- Otherwise take the shortest stem.
- If there is a stemming cache in effect update it with the results
The various dictionaries required by this logic are either passed to the routine as parameters, or they are passed through the basic stemmer context record described below as set up by the “makeStemmerContext” plug-in call.
Note the fact that the input is not internally truncated to a single word until after the three mapping dictionaries have been applied. This allows for things like thesaurus compaction as well as dealing with the possibility of multi-word plural forms (e.g. “will be” becomes “is”). The ‘charsConsumed’ result can be used by the caller to determine how many characters have actually been consumed from the input stream (see the description above for the “invokeStemmer” plug-in). This function is completely script and language independent and merely performs dictionary and logical operations as part of the stemming framework, calling registered stemming algorithms as specified by an ‘algorithm’ list set up by the “makeStemmerContext” plug-in. For these reasons, the function itself is completely multilingual and invariant across all languages. The implementation and operation of the various dictionaries will be discussed later. The beneficial effects provided by this federated approach to stemming include the following:
- The framework can handle irregular plural forms (e.g., men and man).
- The framework can handle irregular tense forms(e.g., teach and taught)
- The framework can handle phrase mapping (e.g.,”when hell freezes over” becomes “never”).
- The framework handles caching results thereby improving performance of any algorithm regardless of algorithm speed.
- The framework chooses the best result from all available stemmers allowing multiple algorithms to be combined for improved results. In Table 1, we see that the output from the Porter stemmer (not the Fairweather stemmer) was used for the word “abjurdicating” (which in this case is actually a spelling error) since the Fairweather stemmer did not produce a result. This means that even if the dictionaries for the Fairweather stemmer are incomplete, reasonable stemming behavior is still possible by adding another stemmer algorithm as a backup that is only invoked when the primary algorithm fails.
- The framework handles lookup of words in the existing stemmed inverted index. This is critical in English for example when a word starts a sentence and thus begins with an upper case letter, since this behavior allows the system to correctly determine that the word is identical to it’s lower case variant occurring elsewhere in any preceding sentence, and thus avoids stemming errors as a result.
- The framework can handle multi-word variants (e.g., “will be” becomes “is”).
- The framework can implement a “thesaurus” mapping which causes different words with similar meanings to be conflated. This can be used to provide another level of meaning search so that for example a search for “chair” would also return hits for “sofa”, “recliner”, “stool” etc. Such aggressive conflation may not be desirable in all cases, but in certain applications might provide considerably improved results.
- The framework can handle common abbreviations for example the sequence TTYL appearing in instant messaging exchanges can be mapped to “talk to you later”.
The execution time for the function QX_UniversalStemmer() is approximately 3 times that of the Porter algorithm itself, which means that the overhead to obtain this improved federated performance (even if not using the Fairweather stemmer) is small and can have a significant impact on search accuracy.
In a very real sense then, Mitopia’s stemming framework can be seen as a first generation effort to overcome the limitations of classical suffix stripping stemmer algorithms by providing the necessary dictionary lookups to handle the language exceptions, as well as allowing multiple algorithms to be executed in parallel and choosing the best results of all available algorithms. This is much like the “Hybrid Approach” stemming algorithms described in the introduction with the added ability to use multiple algorithms.
Later on in Mitopia’s history, the Fairweather stemming algorithm was added to the registered set for each language, and if a Fairweather stemmer is available for the language and fully trained (as described later), it’s accuracy is close to 100%. Even if it is not fully trained, but has a complete list of suffixes, the algorithm can give equally good results to a registered classical algorithm without the need to write any code! This removes much of the motivation to set up and maintain some of the other dictionaries, with the notable exception of proper name dictionaries, and dictionaries that map multiple words into one such as the “phrases” dictionary. The dictionaries associated with the Fairweather stemmer itself are quite capable of handling the functions provided by all the other framework dictionaries. This means that if a new language is to be added and no classical stemming algorithm is available to be registered, the preferred approach is to simply develop and train a Fairweather stemmer for the language. At the present time classical stemming algorithms are only registered for the English language, though at one time a classical Arabic stemmer was also registered. It is probable therefore that going forward, there will be no need to register additional classical stemmers for any language.
Standard Dictionaries used by the Stemmer Framework
The purpose and need for the various standard dictionaries supported by the framework (which can be seen in the declaration of the public type ET_BasicStemCont) is summarized in Table 1 (below).
In this table, the “L/D” column indicates if the dictionary involved is simply a lookup recognizer “L” (i.e., a Boolean true/false) result, or is instead a dictionary “D” which maps any entry found to a corresponding output sequence (which may be empty).
In addition to these dictionaries which are passed through the basic stemmer context, the function QX_UniversalStemmer(), which forms the basis of all language specific stemmers within Mitopia®, can be passed via its parameter list, additional dictionaries alluded to in the logic sequences described above. These dictionaries are as follows:
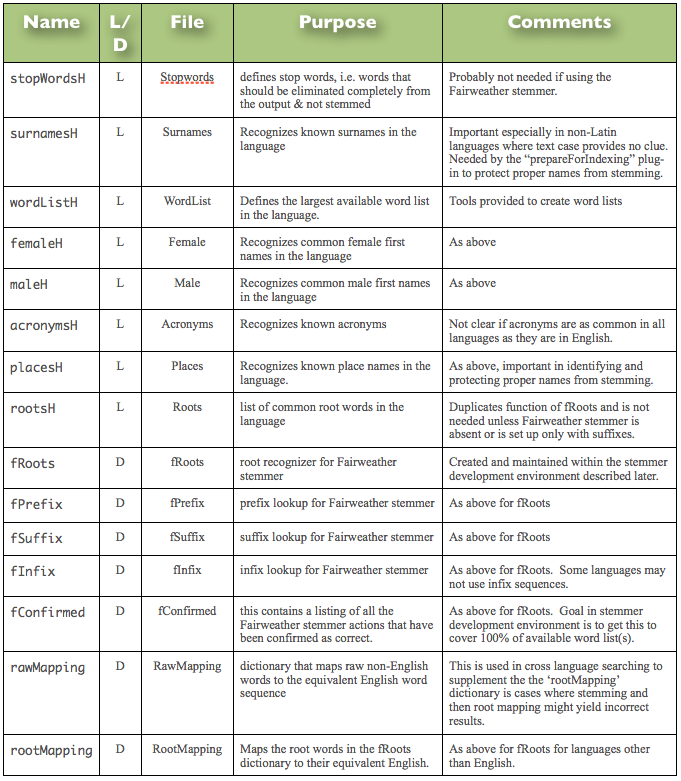
Table 1 – Basic Dictionaries Supported by the Stemming Framework
- “phrases” – This is a mapping dictionary used to map sequences of words into a single word prior to attempting any stemming algorithm. The “phrases” dictionary can be critical in handling common phrases with known meanings, as well as cases where tense causes one word to be split into two (as in the phrase “will be” which is the future of the word “is”). In the process of developing a stemmer, adding a phrase dictionary is probably something one does after all single word variants in the development corpus can be handled correctly.
- “tense” – This is also a mapping dictionary originally envisaged to handle the failure of classical stemming algorithms to deal with irregular tense forms (e.g. teach and taught, run and ran, etc.). If the Fairweather stemmer is being used, this dictionary is probably not needed since the algorithm itself can handle this problem quite effectively.
- “plurals” – Like the “tense” dictionary, this mapping dictionary was originally intended to overcome the limitations of classical stemming algorithms when faced with irregular plural forms. As with the “tense” dictionary, if a Fairweather stemmer is in use, this dictionary is not required.
- “fixup” – Once again this mapping dictionary was intended to overcome classical stemmer shortcomings that did not fall into the categories described above. As with the other parameter based dictionaries described above, it may be unnecessary if the Fairweather stemmer is used.
- “rootsH” – This simple lookup dictionary was intended to overcome the tendency of classical stemming algorithms to “over-stem” root words that end in common suffixes (English root words that end in ‘s’ are a classic case where suffix strippers invariably over stem). In addition, the logic of the framework uses this root word list to distinguish between different stemming results for classical algorithms by favoring results that match a known root. Once again, if the Fairweather stemmer is being used, this dictionary may be unnecessary.
- “wordListH” – As with the “rootsH” dictionary, this simple lookup dictionary is used by the framework to check various stemmer outputs against each other and favor outputs that are in the word list over those that are not. As part of training the Fairweather stemmer, it is likely that a word list is available to use in training and so it is advisable to pass this into the framework even though it may not currently be used, since it may be used to provide additional capabilities in the future, particularly as part of spell checking applications.
- “stopWordsH” – This is a simple lookup dictionary for the words in the language that are essentially meaningless connector words (e.g., the, a, and etc.) and which should simply be eliminated entirely from the stemmed output stream in order to save space. The use of stop words is still a subject of debate. There is no definite list of stop words which all natural language processing (NLP) tools incorporate. Not all NLP tools use a stop list, and some tools specifically avoid using them to support phrase searching. In Mitopia® the issue is somewhat more complicated due to the ability to search across multiple languages using a single query in any supported language. In addition, Mitopia® creates three distinct inverted indexes for all data, an “un-stemmed” index which allows exact match search (and thus can overcome specific stop word and other issues), a native stemmed index in the language concerned, and a mapped and stemmed index in English. This changes the tradeoffs for stop words somewhat. The set of stop words in each language can be quite distinct from other languages and the word involved often has no equivalent when mapped to English. Within Mitopia® each language should define a set of stop words that are specific to that language, and since when doing cross-language queries, the text is first stemmed in its native language, then root word mapped to English, and then stemmed in English, the end result will be that any English stop words generated as a result of the root mapping will also be eliminated prior to multilingual indexing. This means that the developer of stemmer dictionaries for languages other than English does not need to include English stop words in their consideration but instead can concentrate only on those words that are language specific.
It is perhaps important to describe how this stemming framework is integrated with any database subsystem that uses it. There are essentially just two points where stemming must be performed, the first is during the creation of the inverted index file used by the database to search text, and the second is on any text query terms passed as the result of user query to the database. We will gloss over the details of how this connection is made for now since it is not relevant to this post. We will also gloss over the details of implementing the various framework plugins described above since they too are not needed to reach our goal of discussing the Fairweather stemming algorithm itself which must wait till a future post.