
 The long running debate over how to handle error conditions in software has essentially two main camps, those that favor using a exception handling mechanism, and those that favor the use of returned error codes. In the exception approach, when a routine encounters a problem it ‘throws’ an exception and then scans up the calling stack (unwinding the stack as it goes) until it finds an exception handler. Languages like C++ and Java provide exception handling facilities built-in. C does not. Criticisms of the ‘exception handling’ approach include:
The long running debate over how to handle error conditions in software has essentially two main camps, those that favor using a exception handling mechanism, and those that favor the use of returned error codes. In the exception approach, when a routine encounters a problem it ‘throws’ an exception and then scans up the calling stack (unwinding the stack as it goes) until it finds an exception handler. Languages like C++ and Java provide exception handling facilities built-in. C does not. Criticisms of the ‘exception handling’ approach include:- The need for calling code to to declare a handler to deal with failures in called routines represents a leakage of the abstraction and thus runs contrary to OOP principles.
- Poorly handled try/catch blocks can hide the exception from the code level that is best equipped to deal with it and ultimately may make bugs much harder to find.
- Exception handling requires runtime overhead and stack frame space even when no exception occurs. In time critical code, throwing exceptions, even if they rarely occur, should not be used.
- Exceptions tend to result in unknown state and thus force a strategy of aborting the process. If you don’t then the process may crash later (due to messed up state) and the cause may be impossible to determine. The cure can often be worse than the disease.
- Unwinding the stack to find a handler looses information about the exact state where the problem occurred. To debug the problem the programmer requires the most specific details possible.
The alternative approach is to handle the error condition as best as possible where it occurs and then return an error code from that routine to the caller which must itself check for an error condition and take whatever measures are appropriate, including passing the returned (or altered) error code up to its own caller if necessary. At each level in the calling tree, the routine is responsible for undoing any incomplete actions it may have taken (including of course de-allocating memory, closing opened files, etc.). This approach can be use in all programming languages, including of course C. Criticisms of this approach include:
- The need to handle returned error codes directly where they occur in calling code rather than in a separate exception handler can make code more complex to follow.
- Caller’s in general shouldn’t care what the returned error code is since this too represents abstraction leakage.
- Because error code responses are each handled in explicit caller code sequences, the approach can make a unified ‘appearance’ in response to error conditions harder to achieve.
- Calling code may ignore the returned error code and thus do something inappropriate so precipitating further errors. Worse yet, perhaps the calling API does not provide for a returned error indication so the caller is unaware than anything is wrong.
Many types of error conditions are fairly easily handled using either approach, however the hardest types of errors (to survive reliably) tend to be those involving ‘variable mutation’, that is, once a bit of code has changed the state of a variable (local, global, or an external interaction), that state has been overwritten and there may be no record of what its initial state was, and so no simple way to put things back into their previous trusted state and robustly survive the error condition. Unfortunately as the system involved gets larger and contains many layered abstractions each of which maintains hidden global structures describing the global abstraction state, variable mutation errors tend to become all too common. There is little that the programming language can do to help in these cases. The complex multi-threaded environment that is Mitopia® is just such a system, so simplistic adherence to any generic error handling method does little to help the problem and more likely makes it worse. From the outset it was clear that the Mitopia® environment must implement its own standardized error handling and reporting strategies to ensure robustness. This extends into module test harnesses and various other kinds of debugging support within Mitopia®, however, in this post I will limit my discussions purely to the basic error handling/reporting mechanisms.
My early career was spent developing software (usually in assembler) for ‘flight critical’ control systems. Flight critical means that if the software crashes, so does the aircraft, probably with loss of life. I will not belabor the incredible lengths that one must go to to ensure reliability and robustness of flight-critical code, however this early training has no doubt strongly colored my feelings regarding software error handling and robustness in general. In particular, the idea of ‘aborting’ the program by throwing an exception is to me alien and completely unacceptable:
Wikipedia:For example, in 1996 the Ariane V rocket exploded due in part to the Ada programming language exception handling policy of aborting computation on arithmetic error – a floating point to integer conversion overflow – which would not have occurred if the IEEE 754 exception-handling policy of default substitution had been used.
Given that, choosing the second error handling approach (error codes) as the basis for building the Mitopia® error handling architecture was clear (even though there was still C++ involved in the early days – see here for why we later got rid of C++). The first step was to define an error reporting subsystem and API that allows any code that encounters an error condition to immediately report any and all relevant details of the error before attempting to recover from it. It is of course essential that any errors reported remain examinable even if the application were to crash following a failed recovery. The basic error reporting function within Mitopia® is ER_LogError() defined as follows:

Each error has a unique 32-bit error code (the ‘ErrorID‘ parameter) and each source file or code package is allocated a range of error codes that it may use so as to ensure all error codes are globally unique. Mitopia® is broken in to a number of libraries or subsystems each of which deals with a broad area of functionality. By convention the unique subsystem code must be reported by any error call (by ORing into the ‘options‘ parameter). This allows the broad area reporting the error to be identified. Eight standard error severity codes ranging from ‘informational’ all the way up to ‘fatal’ (rarely if ever used) are also defined and passed via ‘options‘ in order to indicate the seriousness of the error condition.
Errors can be grouped into one of 64 broad ‘classes’ (e.g., file I/O, memory, range, security, etc.) and like the level and library constants, these are always OR’d into the ‘options‘ parameter when the error is reported, so giving additional insight into the nature of the error. Most importantly, the ‘FormatString‘ parameter and the ellipses parameter that follows give a sprintf() style ability to pass additional critical debugging information to the error log to aid in debugging. The following are typical examples of error reporting calls within Mitopia® code:

As can be seen, by convention the calling routine passes its own name and any relevant parameter values as the start of the ‘FormatString‘ parameter. Any additional information that needs to be passed for debugging assistance goes afterwards and is labelled (as in the STRING:%s portion of the first call). The last call above is perhaps the most common form since by programming standards, ALL functions within Mitopia® have only a single return statement at the end which is often preceded by error reporting/handling (and cleanup) code labelled ‘BadExit:‘. The call below is a typical example:

The macro ERR_DECLARE(err); is used to declare the error variable (‘err‘ in this example) and also simultaneously declares the variable ‘N_err‘ which holds the ‘options‘ flags. This allows code following this pattern to jump to error handling/reporting code using a simple statement like:
ERR_ABORT(err,1+kNotFoundCLASS+kWarningLVL);
This macro ensures that the content of ‘N_err‘ contains all the required flag settings for the ‘options‘ parameter (other than the library code which is added in the ER_LogError() call). The ‘1+‘ term shown above refers to one of up to 64 numbered ERR_ABORT() calls within any given routine which can also be extracted by the error logging GUI (also from the ‘options‘ parameter) in order to allow rapid isolation of exactly which error condition within the function triggered the reported error. This ‘indexed‘ call approach allows the exact cause and location of any error report to be unambiguously identified. The ability to determine exactly what went wrong from the error log is of course critical to debugging and fixing the problem and the design and usage of ER_LogError() is driven by this need.
A built-in error browser window is of course built into Mitopia® in order to allow errors reported through this API to be examined in detail. The screen shot below shows a sample error browser appearance:
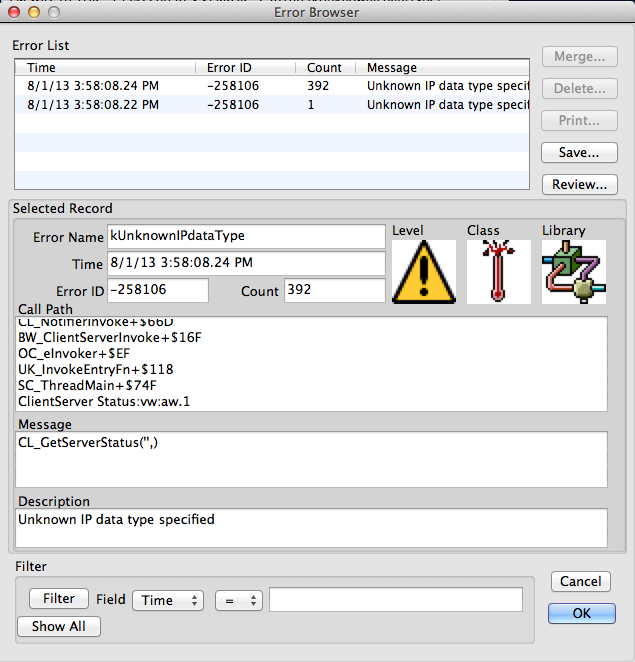
As can be seen the GUI shows the ‘level’, ‘class’, and ‘library’ as icons and it shows the full error message (i.e., the expanded sprintf() string) in the ‘Message’ control. Note that the ‘ErrorID‘ value is displayed not only numerically (in this case -258106), but also in human readable form in the ‘Error Name’ control. This is accomplished by having the error subsystem scan headers (including of course the headers for the underlying OS) to extract all possible error codes and names as well as an error description (shown in the ‘Description’ control). The details of how this is done are not important here, however, the end result is that the system can identify any error code coming from the underlying OS or from within the Mitopia® code uniquely by name and display its meaning. Obviously this helps greatly in user understanding of what has occurred. Note also that the time of the (first) error report is displayed in the ‘Time’ control (it is recorded within the ER_LogError() function), that each and every error report includes a complete stack crawl (see the ‘Call Path’ control), and that if any given stack crawl occurs more than once, it results in simply incrementing the ‘count’ for that error, not in a whole new error log. Simply counting multiple occurrences of the same error is critical when an error occurs many times (in a loop say) as is the case in the example shown above. By simply bumping the count we avoid clutter (generally only the first error is important, subsequent occurrences of the same stack crawl give little additional information), and also we ensure that the error log does not explode under such circumstances. Note (from the stack crawl) that within Mitopia® code each function name starts with a two letter prefix “XX_”, this uniquely identifies the source file/package which contains the function involved.
The provision of a full stack crawl is invaluable as it defines the exact calling context within which the error occurred including the exact program counter position in each and every calling function. Moreover if higher level callers choose to report additional errors (with more details) for the same call, these can be matched through stack crawl to yield a complete understanding of error recovery operations. Mitopia® uses its own code to provide the stack crawl through the coding standards requirement that EVERY function running under Mitopia® (other than external libraries) have a single ENTER() macro at the start and a single RETURN() macro at the end (the only exit point). The data necessary to generate stack crawls including offset within the routine involved can then be invisibly setup by the ENTER() and RETURN() macros and used by ER_LogError() and other client abstractions. The ultimate goal is that an error, no matter how infrequent, only has to occur once in order to hopefully give sufficient information to isolate and debug the cause, even without a debugger available. Once again this level of instrumentation is crucial in investigating problems that only occur at the customer site but are not repeatable in the lab. It is these kinds of problems that can drive developers crazy without such tools. The ENTER() and RETURN() macros are also used for various other debugging, profiling, and instrumentation purposes by Mitopia’s debugging and test framework, indeed, these macros actually redefine the meaning of C’s ‘return‘ key word so that it is impossible to accidentally create a function with more than one ‘return‘ statement if the Mitopia® header files are included.
The instrumented error is flushed to file (and optionally elsewhere also – e.g. syslog) as it is reported, and old error logs can be opened and examined through the browser window in order to debug errors occurring before an application crash. A number of additional API functions are provided to customize error behaviors including:
- Suppressing specific error reports within called code in cases where the caller is expecting it or has code to fix and continue.
- Published breakpoints for the debugger to catch any error immediately as it occurs.
- Queuing error reports at interrupt level.
- Launching dialogs to the user to help.
- Providing an exception handler like API allowing callers to handle errors without lower level reports being logged.
- Calling functions determining if errors have occurred within, even if the calling API doesn’t support this.
- Passing error callbacks to provide custom fixes to errors in lower level code.
Given the setup described above, all that remains in order to create a robust system that reports and recovers from errors, but does not crash or abort is the following:
- Where functions return error codes, or Booleans indicating success/failure, it is essential that the calling code check this value and on a failure take whatever additional cleanup actions are required at the caller level. If the calling routine also exits abnormally (i.e., does not recover and re-try), it too should return some kind of error indication. Callers generally don’t care exactly what error code is returned, just the fact that an error has happened is sufficient.
- Criticisms 2 and 3 against the error codes approach are mitigated by the error reporting infrastructure described above.
- Criticism 4 remains and must be addressed by rigorous module and integration testing. Mitopia® provides tools to force common failure types within module tests in order to test recovery strategies. It also provides comprehensive memory tracking and leak checking on a per-thread basis which ensures that recovery and error handling strategies do not leak.
- If anything has to be aborted, it is limited to the widget/thread involved, the entire application rarely if ever crashes.
The combination of a robust error handling infrastructure and an equally robust set of debugging tools, combined with enforced use through the coding standards and built-in module tests for each package, leads to a reliable system which is easy to debug and develop on top of. It is not possible to rely on programming language constructs to achieve this level of reliability, one must have a pervasive culture, tools, test harnesses, and strictly enforced coding standards to achieve this. Unsurprisingly all these things (and more) are true of flight critical software.