Real world problems make computer chess look easy…

Welcome to our little corner of the Internet. Kick your feet up and stay a while.
Real world problems make computer chess look easy…

In an earlier post (here) lamenting blind unthinking use of Object Oriented Programming and espousing OOP alternatives, I made the following statement: “What in my opinion is the greatest feature …

Today’s databases drastically limit what problems we can tackle…
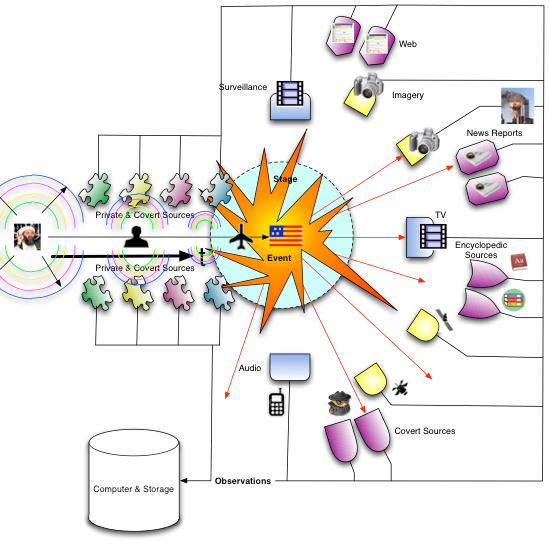
Ontology should be based on science, not on philosophy…

Ontology isn’t an add on, its the only way to access data…

An impossible pipe dream right? Maybe not…

Taxonomic thinking prevents ‘real’ data integration and limits insights…

Much of this post and the illustrations within are taken from a Semantic Web lecture by John Davies, BT. The motivation behind the semantic web, for which OWL is the …

Pointers ultimately cause schisms and should be outlawed…

Implementing scaleable data-flow based systems…

The software one, not the one in the Western Atlantic…
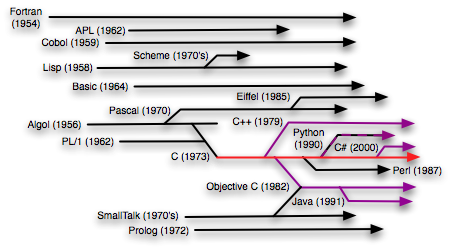
Throughout the Mitopia® development, the question of why don’t we use C++ (or more recently Objective-C) instead of straight C has emerged again and again, particularly among younger members of …

This post on information overload is part 3 of a sequence. To get to the start click here. More and more our lives and interactions occur in the digital world, not …

Truncated [knowledge] pyramids are great for human sacrifices…
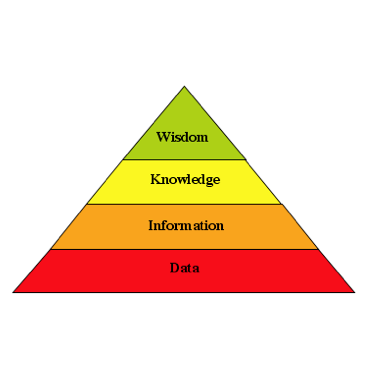
Before future posts can discuss true ontologies and how they fit into the range of computing systems, and most particularly how ontology-based systems differ fundamentally from todays taxonomy-level systems, we …