Throughout the Mitopia® development, the question of why don’t we use
C++ (or more recently
Objective-C) instead of straight
C has emerged again and again, particularly among younger members of the development team. At the outset (back around 1991), the decision was made to use object oriented programming (OOP) techniques and implement all code in C++, we felt that for such a huge undertaking, the claimed increase in coding efficiency more than justified itself, so that was what happened for a number of years. It turned out to be an unmitigated disaster. In the end, all C++ code had to be re-written from scratch in C. The reasons why this was so, are instructive for anyone embarking on a really large and dynamic software project, and are the subject of my post today. We will characterize such a project as one with a large programming team, and where requirements must evolve with changes in the outside world. Given the increasing rate of change in the digital world, this set includes almost all non-trivial, non-isolated development efforts.
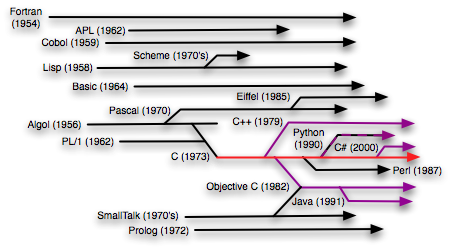 |
| Evolution of Major Programming Languages |
NOTES:
- Prolog – Warren Abstract Machine – implemented in C.
- Perl – Interpreter and library written in C
- SmallTalk – Most implementations now written in C
- Python – Written in C
- C++ – Originally implemented as C preprocessor layer
- Objective C – Initial implementations done using C preprocessor
- Java – Virtual machine written in C
- C# – Derived from C
- Ada – Initial versions implemented in C
The diagram above shows a simplified family tree and time line of the major ‘true’ programming languages where the line lengths for each language indicate the period over which the language remained in significant use. For a more exhaustive language tree, see
here. In an earlier post (
here) we introduced the TIOBE programming community index (
www.tiobe.com) and discussed how C remains the most popular language even today, 40 years after its inception. In contrast, trends for C’s older OOP derivatives are downwards. Over the long term the situation appears as shown in the table below.
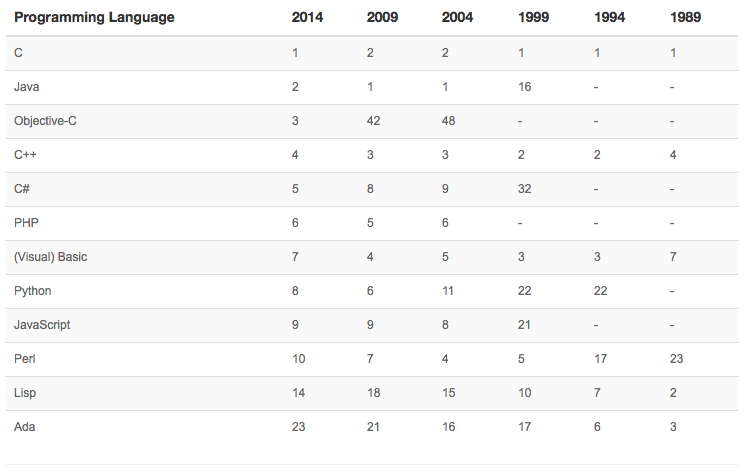 |
| Long Term Language Rankings |
C was developed between 1969-73 at Bell Labs by Thompson and Ritchie. It is the most widely used programming language, prized for its efficiency and for this and other reasons is almost exclusively the language in which system software is written. Another consequence of C’s wide acceptance is that compilers, libraries, and virtual machines for other high level languages are most often written in C. C is essentially a low level language, it directly provides no object-oriented features leaving all such refinements as design decisions up to the developer. C is the language on which Unix is based, and thus in a very real sense is the language on which the Internet itself is built. There is probably more ‘active’ C code out there than anything else, and the gap is getting wider. Other languages have peaked briefly as they become the ‘fad’, but in the end it appears they always fade back into the noise. The reasons for C’s enduring popularity are I believe clear, if one thinks about it with an open mind.
As we can see from the diagram above, a large fraction of all mainstream languages in existence are either ancestrally derived from C or run on a virtual machine and use libraries that are written in C. Why is this? The answer is quite simple. If we consider the act of creating a new language to be an effort to get outside of the “box” imposed by other existing languages in order to attain some new kind of expressive power, then clearly one does not step out of a “box” by climbing into another “box” (i.e., a language with an existing ‘paradigm’) first.
But what are these derivative languages? Why of course they are themselves no more than new “boxes” embodying some set of constraints and restrictions in order through the resulting paradigm to achieve greater expressiveness within some target domain. If you want to make a new “box” you need to do it based on a language that does not itself impose “box” walls and paradigms of its own, otherwise the “boxes” will overlap and you will spend most of your time trying to overcome the incompatibilities in the paradigms. Given this requirement, the only real substrate choice available is C, since it has no paradigm at all. It is primarily for this reason that almost all other language developments are a least initially based on C, and that virtually all system software is written in C.
What we set out to do in Mitopia® was to create a new “box”, one that challenged not only programming language thinking, but also the thus far unchallenged principles of control based programming, and at a more fundamental level, the very memory model on which code is written, the Von-Neuman architecture itself, and the dichotomy between memory based data and persistent data which first gave rise to the concept of databases. Clearly this is a box that cannot co-exist with any of the earlier paradigm boxes, our only choice for an implementation language is therefore C. In retrospect then, the initial decision to go with C++ as the implementation language was foolishness. Clearly the object oriented programming paradigm would conflict with a system based on data flow and run-time type discovery where classic memory allocations are strongly deprecated.
But when a programmer is in a language manifested ‘box’, it is very hard to even see the walls, let alone appreciate what may be beyond them. How do we know that we have grown accustomed to the constraints of a “box” and thus now longer see how it limits our thinking? For decades now, I have had a sort of mental contract with myself relating to use of the words “can’t” and “should not” regarding developing software. Whenever I use one of these words, or I hear somebody else use them relating to programming, this is a very good indication that thinking has collided with the walls of a “box”. So when this happens, I make a point of stopping what I’m doing and examining the reasons behind the “can’t” or “should not”. Sometimes they are legitimate, but most often they are the result of slipping into some mental sink-hole. The only high level language that I have ever used which has not done the “can’t” or “should not” thing to me is C. If I don’t like where the walls of my current “box” are, I want to be sure I am able to move them, I don’t want the thinking of a bunch guys I can’t argue with standing in my way. That’s just me, other people are more comfortable in “boxes”, especially when many others share the “box” with them.
Now from this you might assume that I am against the principles of object oriented programming, which we have all been taught is our salvation. In this you would be only partially correct. While I am totally convinced of the power and utility of the principles of abstraction and data hiding, I am not convinced that object oriented programming, which has somehow in people’s mind commandeered these principles and made them its own, is the right solution in all cases.
The principles of abstraction and data hiding were perhaps most eloquently expressed in the article by D.L. Parnas entitled “On the criteria to be used in decomposing systems into modules” (Comms. ACM Dec. 1972). If you have not read this paper, I strongly recommend doing so (see
here). I first read it in the early 1980s, and it profoundly shaped my thinking. Parnas presented a compelling comparison between the top-down structured approach that was then the accepted thinking, and a data abstraction approach. He did so without the use of a programming language, but merely at the level of design decision criteria. In the end, you can write a bad program in any language, all that OO languages provide is a formalism that tries to encourage good design principles in those programmers that might otherwise have gone astray. Through the use of common constraints and conventions, such a language attempts to build up libraries of re-useable components.
The features of the language itself provide no capability not inherent in a lower level language (such as C), they simply provide a shorthand and a set of guide posts for those that choose to heed them. After all as we have seen, many languages are actually implemented in C, so obviously they cannot do anything that C can’t. It is the libraries that these languages seek to build up that adds the expressive power, not the languages themselves.
Abstraction and
information hiding, and how to accomplish them, are design decisions, they should not be enforced by the language unless, for each problem being solved, the programmer confirms that the choices made by the language designers are compatible with the problem itself. Rarely considered at the outset is the issue of pervasive change and how it will impact development.
Unfortunately, in my experience OOP programmers tend to become so enamored of the language, that they fail to re-examine it’s suitability to each new problem, a debilitating condition that I refer to as “Objectivitis”.
But you may argue, once you learn the language, its classes, its paradigms, and its libraries, then you can write code faster than in a lower level language. At first glance, there is some empirical evidence to support this claim, the Lines of Code (LOC) per
Function Point (FP) figures quoted by software Engineering literature reflects this perception.
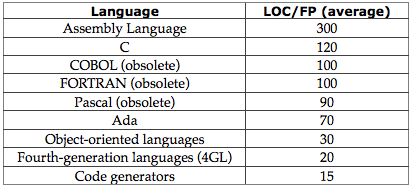
Here we see that LOC/FP for object-oriented languages is taken to be roughly one quarter of that required by straight C. Why is this so? The standard answer of course is that OOP relies heavily on
inheritance; that is you can acquire complex functionality concisely by inheriting it from one or more ancestral classes. This is in contrast to the bottom up layered approach that is exhibited by
component based programming models. This has been the conventional wisdom for quite some time. Beyond the realm of trivial programs, it is, and always has been, wrong.
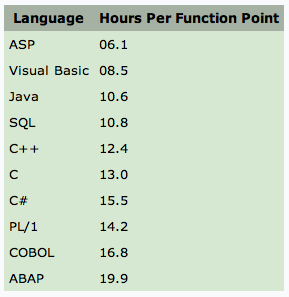
Just this month,
ISBSG, a non-profit software research group released a study based on findings from 6,000 projects using the function point measure to track real world programmer productivity in terms of the number of hours it takes to develop each function point (see
here). The results are shown in the table. As can be seen, the data shows that there is little difference in productivity between straight C and C++, Java, or C#. The conventional wisdom that OOP languages yield massive increases in productivity is clearly false. The reason why the latest figures contradict those found in earlier textbooks is simply because the scale of programming projects has increased dramatically from then till now. What may have applied for simple little demo programs, clearly does not scale to the huge and complex programming undertakings of today. In a large project, you must develop most of your own classes from scratch, there is much less inheritance from the language ‘library’ to distort the numbers.
Add to this the fact that in a truly large code base, there is much simplification to the programmer’s ‘orient’ activity (which should occur before writing any piece of code) in knowing that one need only continue to look ‘down’ through the abstraction layers to see how something actually gets done. In a huge OOP code base, it is hard to tell if one should look ‘up’ into the inherited classes or ‘down’. The existing code becomes harder to fully understand by others ‘at a glance’ in the OOP case. The OOP language’s gain in expressivity thus manifests itself as a increased difficulty to ‘orient’ during maintenance which leads to a somewhat reduced real world productivity over the long term. This effect reduces OOP productivity gains significantly as the code base grows. Remember, studies have shown that around 40-80% of software cost is in the ‘maintenance’ phase.
The flaws in the simplistic belief that a programming language itself can dramatically improve performance only become apparent with today’s large scale programming projects that must integrate across multiple disciplines and that have development timeframes that expose them to to the corrosive power of change.
We can picture the two programming metaphors (straight C vs. and OOP derivative) in terms of pyramids resting on an underlying plain which represents the operating system, the environmental, and application specific assumptions (many unconscious or unknown), on which the code base is developed. This appears something like the diagram below:
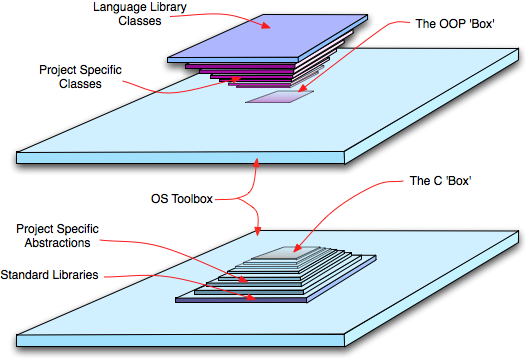 |
| Comparison of OOP vs. non-OOP approach to abstraction and information hiding |
The blue plane is the underlying environment and assumptions. The bottom diagram represents the Mitopia® approach of building up successive abstraction layers from the bottom up, starting essentially with nothing but the language and the underlying operating system. This takes a lot of code and many layers nested one on top of another before we reach the flat square at the top of the pyramid which is the “business-end” where “application level” programming takes place (i.e., the “box”).
The upper diagram represents the OOP approach for C++ say where the “box” lies below the bulk of the code which it inherits from the classes of the application framework which are in turn based on the classes, constraints, and libraries of the underlying language (represented by the blue square on the inverted base of the pyramid). Classes in the language library, much as for functions within the OS Toolbox, tend to be inaccessible and not subject to reconsideration. Obviously as we have shown before, there is fundamentally no difference between the size, expressivity, and capabilities of the final “box”, it is simply a matter of the geometries of the pyramids. Since both pyramids, and most likely also the underlying OS, can be considered ultimately to be built on C, in the end, it is not even logical to discuss any inherent differences in ‘box’ dimensions, since with a little more work, or a few more layers in either diagram, the “boxes” can obviously be brought to identical dimensions. Note however that in the OOP diagram the ‘box’ lies close to the underlying plane, if the class hierarchy has not encapsulated some substrate/toolbox functionality, the temptation to include such calls directly into the box code is significant. These embedded box calls can make the approach more vulnerable to change from the outside world over the longer term.
What we must look at instead of absolute ‘box’ size, it the nature of life for the programmer who did not personally participate in creating the entirety of either pyramid. This should be the only true measure by which we can distinguish design approaches, not by simplistic claims of enhanced productivity measured in function points or otherwise.
Although the ‘box’ is of identical size in either case, this is not to say that the inherited “box” does not at first glance feel more expressive, after all, the weight of all the code above almost ‘squirts’ into the “box” when you use it, as features accrete based on inheritance pushing you around in the “box” ‘plane’ by the simple expedient of deciding which of the provided classes of the environment you want the be part of. This give the perception of a very empowering environment…pick a class and just tinker with a few bits of it to do your special thing.
On the other hand, the right-side-up pyramid approach requires more work and a deeper understanding of the layers that make up the pyramid before it is possible to decide how to write the code you need. Moreover, without the rigid constraints of a language metaphor, once you make such a choice, you are not shuffled off to another part of the “box” plane but are simply faced with new choices, which you can assemble in any way you like. The fact that above you is the open sky, and to the edge of you the railing that prevents you falling down the side, looks, and is, quite flimsy, can be unsettling for those who suffer from agoraphobia, are unsure of their balance, or are afraid of heights.
In effect the OOP approach is like building a house out of pre-fabricated whole rooms (which you may decorate) while the component based approach presents you with a bewildering array of possibilities, but in the end, allows you to custom build your house from the ground up including using prefabricated panels if you desire.
The point here is that this automatic “box” sealing tends to make the unwary feel empowered, and as long as they don’t try to get out of the “box”, and the problem is small and fits the paradigm of the pyramid floating above them, this is true. This effect accounts for most programmer’s natural attraction to the OOP paradigm. But remember, both approaches accomplish abstraction and information hiding, there is fundamentally no difference from the perspective of the “box” dweller in the expressive power available, it is just that the walls in the OOP “box” somehow seem stronger and more reassuring since they snap conveniently into place with just the smallest design decision, and they do so smoothly and with such a reassuring swish, that it alleviates agoraphobia, and cleverly does not trigger claustrophobia except in a few.
Of course this auto-snapping of the walls is also the reason why object oriented programming languages are poor choices for those seeking to break paradigms and build new “boxes”; it is also a problem when your project grows beyond the simplifying assumptions built into the hovering class structure above you.
As mentioned above, way back in the beginning of the Mitopia® project after much debate we chose to go the C++ rather than the straight C route. So we hired the best C++ programmers we could find, we handed out the requirements, and told them to go forth and design/implement a system to the requirements. It was an disaster on a scale so grand as to be embarrassing. After a number of years when we realized everything was a complete loss and sat down to think about the causes, we came up with the term “Objectivitis” to describe the debilitating disease that afflicted our OOP superstars, we laid off (or otherwise shed) almost every last one of them. We interviewed and hired new programming staff with the specific goal of weeding out and rejecting any that were smitten with OOP to the point where they suffered from objectivitis. All told, over the history of the Mitopia® project, OOP (mainly C++) has been responsible for more wasted time than any other single cause, well in excess of a quarter of a man-century. If you add Java to the mix, the damage is even greater. To recount the main incidents (by subsystem within the project):

To summarize, my experience has been that OOP techniques when applied to problems that they are unsuited to, are almost universally a disaster. OOP works well only in problem spaces that are naturally constrained, which are not subject to pragmatic considerations imposed by the outside world and existing environment, do not conflict with the paradigm restrictions of the OOP language chosen, do not have to deal with rapid change, and most importantly of all, it appears that OOP only works when a single individual is involved and can keep the whole thing in his/her head. The problem gets worse as the project gets larger and more complex.
Why is this so? Consider the pyramid diagram I gave earlier. Both pyramids rest on the underlying substrate, and both are stable as long as nothing changes. But of course things always change! Imagine if you will a tectonic shudder rippling through the substrate like someone pulling out a rug from under you. Such a shudder could be a change in the environment but most often it is a change in the assumptions that govern what the program is attempting to do. Now what happens? In the right-side up pyramid, not much, perhaps a few blocks in the lower regions of the pyramid get broken and need repairs but programmers in the “box” are unlikely to even be aware of the change. Over twenty years of development, Mitopia underwent a number of massive tectonic changes. Yet over the years, most tectonic shudders never even rippled up to a level where anyone other than the person(s) repairing the base blocks was aware of the earthquake. Assuming good abstraction layers, little extends into the box, all repairs are to isolated and independent lower level abstractions. The result was that life continued for most ‘box’ developers pretty much unchanged.
Now lets examine what happens in the inverted OOP pyramid case? Well, the assumption change generally impacts as a need to change the class hierarchy, and of course this ripples throughout the entire code base including those in the “box” who have made all their decisions based on the class hierarchy “walls” that were so comforting. To keep the pyramid from topping over (since it rests on its point), its creator must work frantically to keep it ‘balanced’, and must then help all the poor box dwellers to update their code to handle whatever was necessary to maintain that balance. New ‘box’ classes, new assumptions. For any large highly connected system exposed to the real world, these assumption changes can hit at an alarming rate, and unless the single creator of the original framework/pyramid is around and still capable of re-balancing it, the whole thing falls in pieces on the ground. If there is a team involved in the project, the chances of balancing are apparently reduced proportional to the number of people involved. Since Mitopia® was from the outset predicated on the assumption of continuous change, clearly we should not allow inverted pyramids to be part of the code base. Worse than this, even if the one super programmer is still involved, what if they get hit by a bus, and anyway once things get really large, even they cannot remember all the subtle adjustments made over the years to achieve balance, and so in the act of re-balancing they inevitably break stuff in the box based on prior class assumptions.
When we eventually moved to the C++ GUI framework, the development team became very familiar with the impacts of re-balancing in the pyramid above our heads. We got accustomed to bracing ourselves each time a major new build appeared, and the development version generally took weeks to re-stabilize. Of course since the developer was a super-programmer, everything was rapidly fixed once the culprit was isolated and proven.
The lack of any classes or inheritance and the use of run-time type discovery and auto-generation of both the GUI and the ‘database’ from the ontology became even more important as Mitopia’s mechanism to decouple the fallout from ‘above’, but just as importantly tectonic shudders from below, from everyday life in the “box”.

What then is the problem with OOP other than being an addictive drug? Basically it is inheritance. It is inheritance that gives OOP its expressive power, but it is also inheritance that is its greatest fault, for it is inheritance that produces these solid vertical walls that so reassuringly protrude into the “box”. But when the assumptions that govern the placement of these walls are challenged or changed, as they inevitably will be, the resultant effect on the “box dwellers” is much like being in a blender as walls whiz back and forth sometimes crushing the occupants of a room that has suddenly disappeared.
Knowing, though seldom verbalizing, this ‘blending’ problem, causes most good OOP programmers to get stuck in the “class thrashing” loop as they try to find the ultimate class breakdown that will never change and thus never ‘blend’ their “box dwellers”. When the problem space does not lend itself to this approach, as it often doesn’t, we have the all to common result of producing virtually nothing useful despite huge efforts.
No such effect occurs when abstraction is handled in a bottom up, horizontally layered, component-based approach. From the “box dweller” perspective, one simply sees new bricks and building blocks appear, but the house room plan does not re-arrange itself without permission.
To solve a problem in an OOP language the programmer must choose to ‘become’ part of one or more existing classes, subsuming any personal conceptualization into that of the class library. Program structure is ordained from above.
To solve a problem in a component-based abstraction, the programmer chooses and assembles components from the available abstractions, but remains free to conceptualize the problem in any way. While the components may influence the solution approach, they are generally subordinate to the code of the problem solver.
What in my opinion is the greatest feature of OOP? It is the ‘tagged union’ construct used by a ‘class’ to handle inheritance and polymorphism. Regrettably however, this trick is hidden within the ‘implementation’ and wholly unknown and unappreciated by most OOP programmers who think it some magical feature conferred by the class concept. The construct should instead be exposed for overt and creative use within the ‘box’. Were this to be done, many might see OOP languages for the thin facade that they really are. I will deal with this concept in later posts (
see here).

If your goal is to create something radically new, don’t waste time peering enviously into other people’s boxes, they will drift where they will, you need to chart your own course without outside influence. New language fads are among the most dangerous boxes to peer into. In all things, you should look at what others have done only AFTER you have implemented your own initial solution. If you look before, you will likely fall into the canyon of their bad decisions. If you look afterwards, you will appreciate why they made their choices and you may actually learn something. More likely it has been my experience that you will disagree with the fundamental approach and chart a wholly different course. The needs and paths of the shoal are not those of an innovator.
P.S. For a related bit of programming language humor, click here.